

常见协议的RFC文档正常值
- 为什么要查询RFC文档呢?
它可以将正常的行为流量与异常的攻击流量区分开来。能看出来正常的值就等于能观察到异常的攻击流量。
一个强有力的意识就是:遇到可疑,就来RFC查询它们的合法解释,如果未找到合法的行为解释,显而易见,它属于非法。遇事不决,RFC文档。
ARP
- 实战练习可以在官网把样本下载下来自己观察
https://gitlab.com/wireshark/wireshark/-/wikis/home 【官方样本】
https://wiki.wireshark.org/SampleCaptures#ARP.2FRARP 【官方样本】
https://gitlab.com/wireshark/wireshark/-/wikis/uploads/__moin_import__/attachments/SampleCaptures/nb6-startup.pcap 【本例中使用此样本】
这个协议本身没几个字段,相对简单容易理解。就不放RFC文档了,感兴趣的可以自己阅读一下wiki
https://en.wikipedia.org/wiki/Address_Resolution_Protocol
- 需要注意的是,将解析物理地址调整出来,便于观察mac地址来核查可疑的痕迹

- 比如发现bogon很可疑,则可以将该目标过滤出来。注意:大部分情况下,不需要使用语法。直接选中。bogon旨在表示假的,伪造的。
https://en.wikipedia.org/wiki/Bogon_filtering![]()
![]()
- 使用选中功能生成语法,在此基础上再使用一些布尔运算符之类的拼拼凑凑即可。

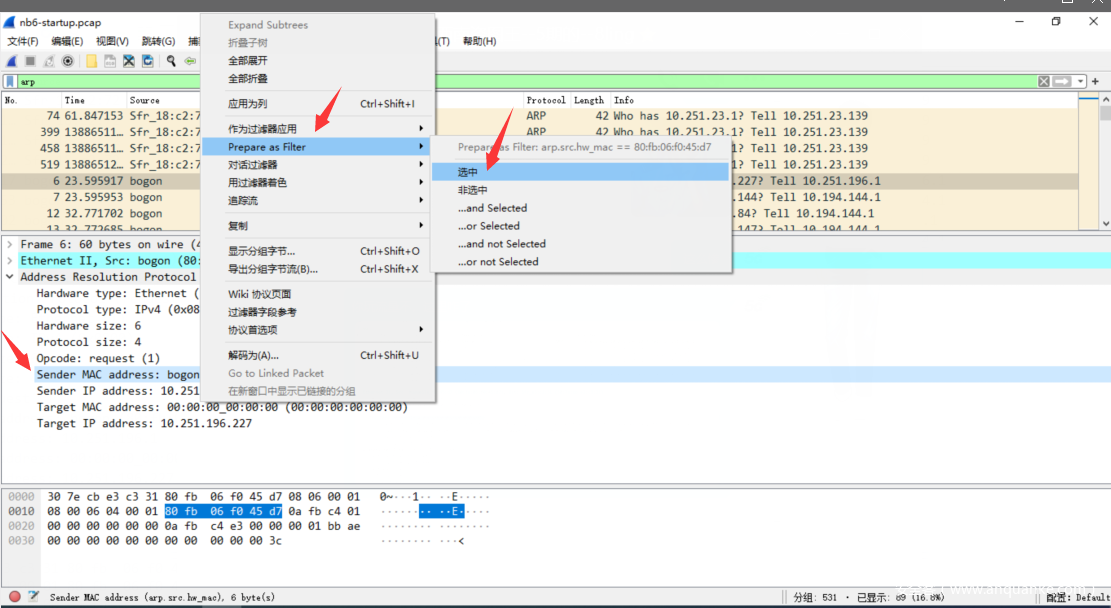
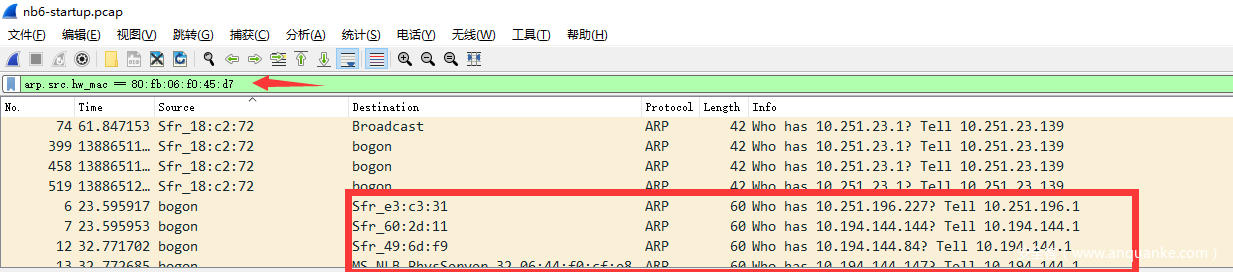
- 如果发现同一个MAC值,对应多个IP身份,则很可疑
- 这里是请求与响应的操作码,广播包。注意请求包的目标地址是广播。如果不是广播则不正常。
![]()

ICMP
-
https://datatracker.ietf.org/doc/html/rfc792 RFC-792
https://gitlab.com/wireshark/wireshark/-/wikis/uploads/__moin_import__/attachments/SampleCaptures/nb6-startup.pcap 【本例中使用此样本】
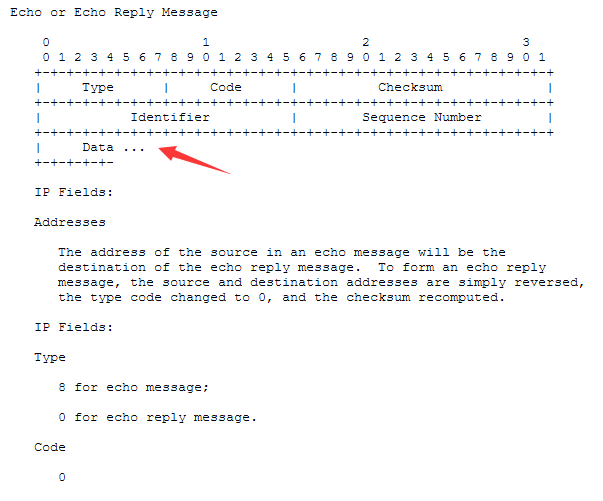
ICMP是用于分析网络上的各种节点诊断信息的。 常体现于ping和traceroute之类的实用程序。
- type值8是请求包,type值0是应答包
![]()
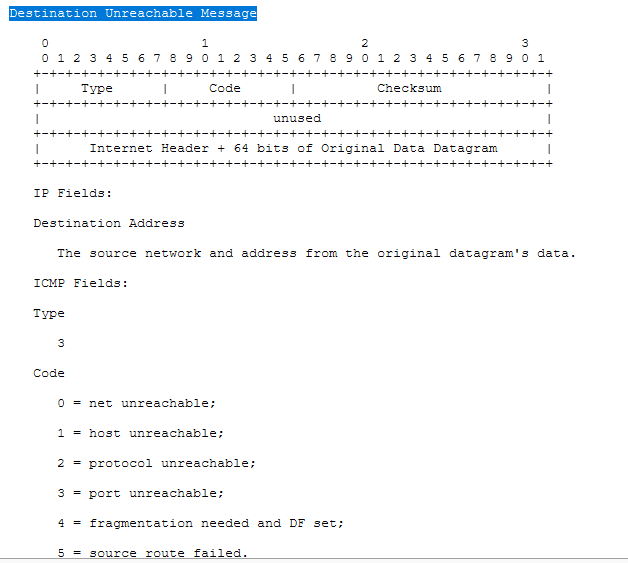
- 如果您发现其他值,请看RFC文档对应字段的解释 比如type=3为目标不可达,type=11 为超时,type=12 参数存在问题等。code是具体type对应的不同原因值。
![]()
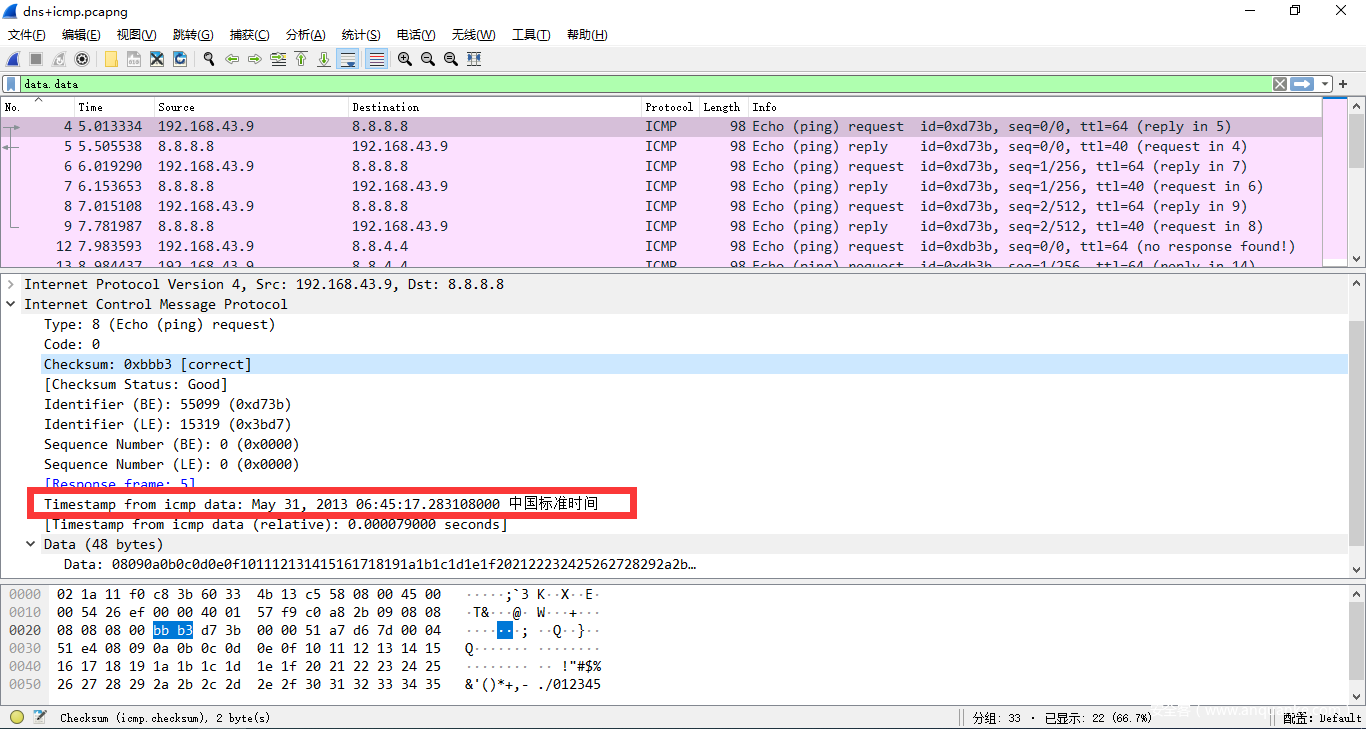
- Timestamp有时被用于确认事情发生的时间点
![]()
- 我们发现在type 8和0的包格式中,data字段没有限制多少bit
![]()
- 并且还发现data字段,identifier字段,sequence字段,code 0在请求包中是什么值,响应包就返回相同值。
![]()
- 观察正常的包也确实和RFC文档中描述的一模一样
![]()



TCP
RFC-793
样本
- https://gitlab.com/wireshark/wireshark/-/wikis/uploads/__moin_import__/attachments/SampleCaptures/nb6-startup.pcap
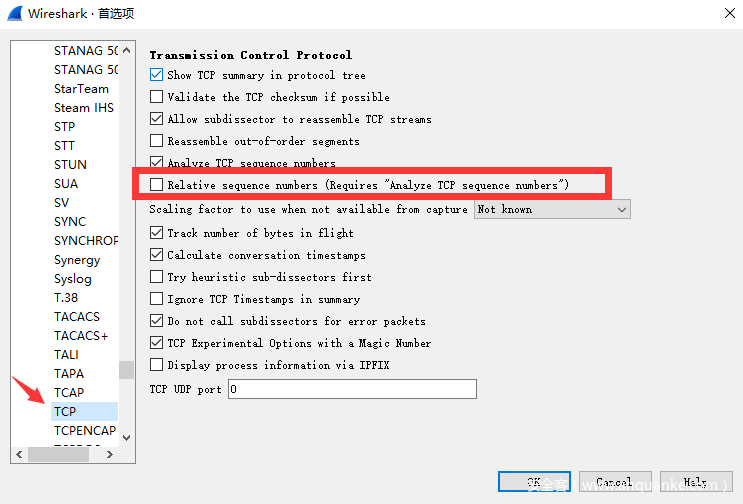
- 编辑>首选项>协议> TCP>去掉相对序列号的钩来查看原始序列号。
![]()
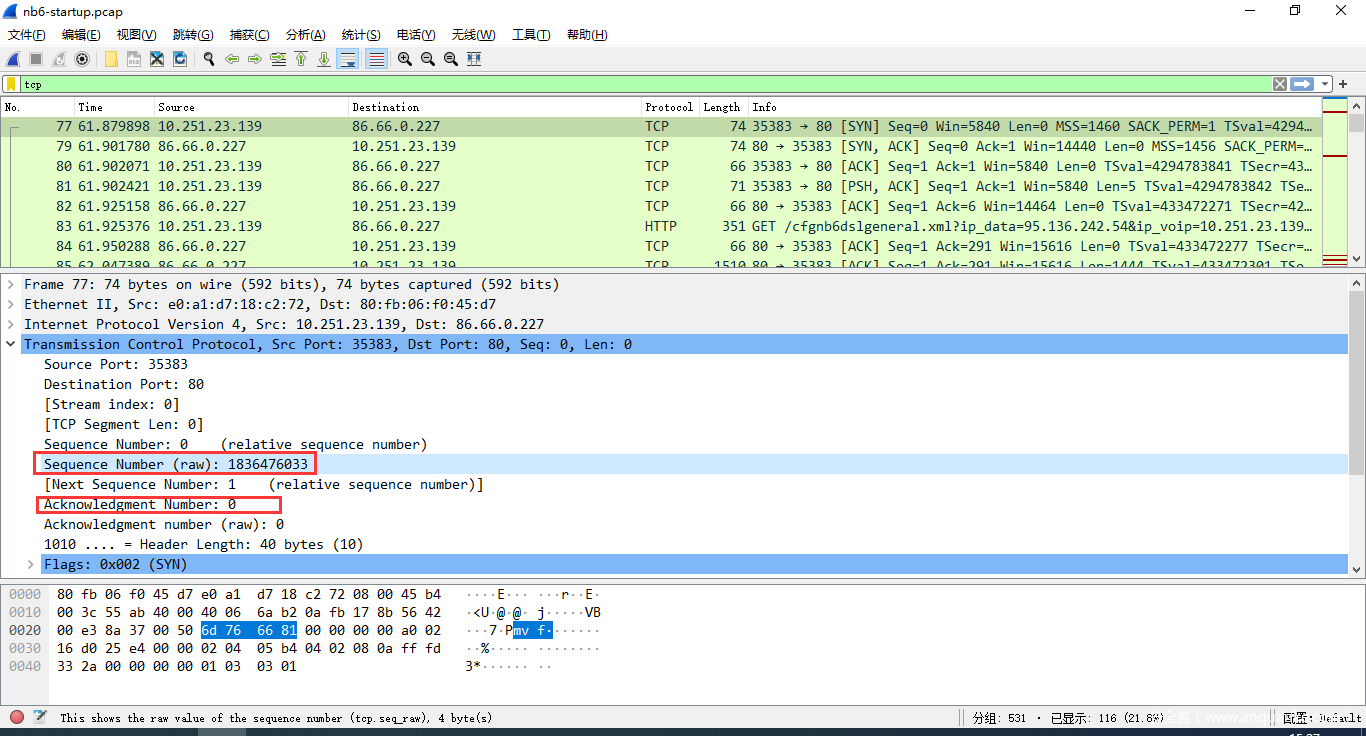
- 如果未出现raw原始序列号,则把钩选上再看。对于TCP主要观察序列号和确认号
![]()
- 如果对头格式中的其他字段感兴趣,则可以进入到RFC文档。点击头格式查看解释
![]()


Data Offset: 表示数据从哪里开始
URG:紧急指针字段意义重大
ACK:确认字段有效
PSH:推送功能
RST:重置连接
SYN:同步序列号
FIN:没有来自发件人的更多数据
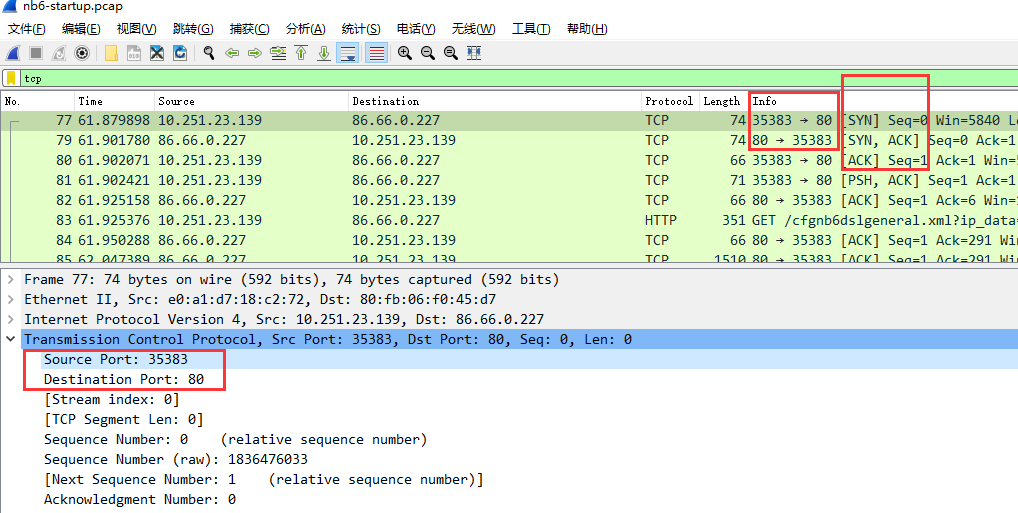
- TCP需要注意的点是 端口,flags,以及三次握手的顺序(如果莫名其妙先出现SYN,ACK,则一定有问题,比如有人在绕waf)
![]()
- nmap的各种类型的扫描留给大家自己观察,这里就不赘述了。
DNS
RFC-1035
https://www.ietf.org/rfc/rfc1035.txt
【本例使用此样本】
https://gitlab.com/wireshark/wireshark/-/wikis/uploads/__moin_import__/attachments/SampleCaptures/dns-icmp.pcapng.gz
- DNS原理 查询的记录会在本地缓存中添加
![]()
- DNS服务器原理
根据其功能,名称服务器可以是专用计算机上的独立程序,也可以是大型分时主机上的一个或多个进程。 一个简单的配置可能是:![]()
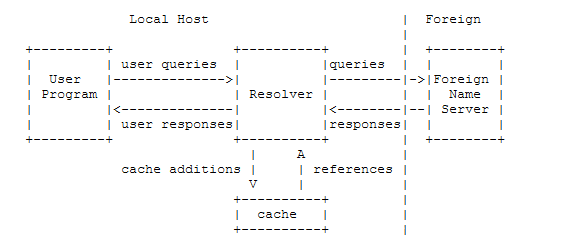

在这里,主NameServer通过从其本地文件系统中读取主文件来获取有关一个或多个区域的信息,并回答有关来自外部解析器的那些区域的查询。
- DNS区域传输
DNS要求多个区域服务器冗余地支持所有区域。 指定的辅助服务器可以使用DNS的区域传输协议来获取区域并从主服务器检查更新。 该配置如下所示:
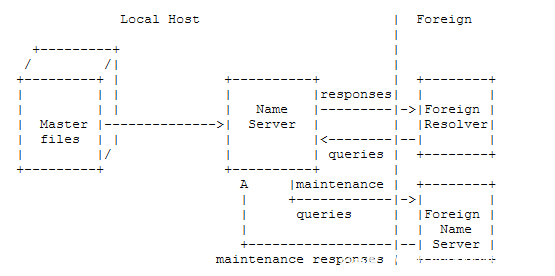
在这种配置中,名称服务器会定期开始维护活动获取外部NameServer区域的副本或检查现有副本是否已更改。
maintenance responses 维护与响应
支持域名系统各个方面的主机中的信息流如下所示:
refreshes 刷新 references 参考
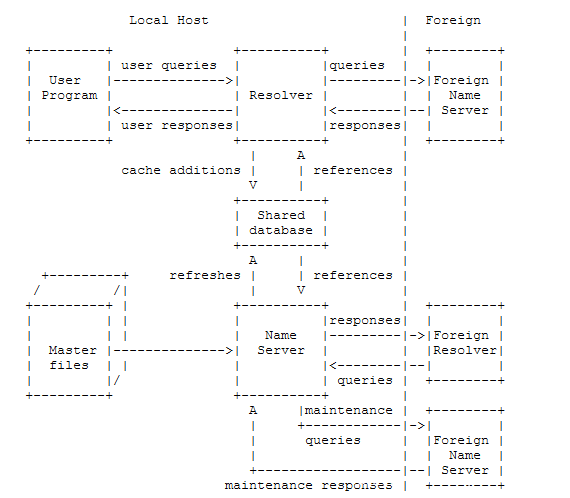
共享数据库保存本地名称服务器和解析器的域空间数据。 共享数据库的内容通常是由NameServer的定期刷新操作维护的权威数据和来自先前解析程序请求的缓存数据的混合。 域数据的结构以及NameServer和解析程序之间同步的必要性暗示了此数据库的一般特征,但实际格式取决于本地实现者。
- 递归服务器集中式缓存—提高解析命中率
还可以定制信息流,以便一组主机一起行动以优化活动。 有时这样做是为了卸载能力较弱的主机,这样它们就不必实现完整的解析器。 这对于希望最大程度地减少所需新网络代码量的PC或主机而言是合适的。 在集中式缓存具有较高命中率的前提下,该方案还可以允许一组主机共享少量缓存,而不必维护大量单独的缓存。 无论哪种情况,解析器都将由存根解析器代替,存根解析器充当位于一个或多个已知执行该服务的名称服务器中的递归服务器中的解析器的前端:
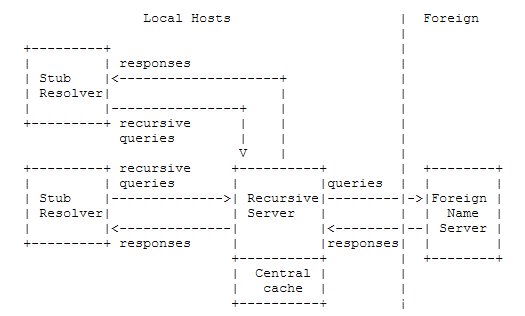
stub resolver 根解析器旨在比喻递归查询后面的下一个服务器,不是真正的根服务器
recursive server 递归服务器
- CNAME 名称服务器可以配置它已进行重新启动查询(解析重定向)
![]()
- NULL记录不会导致任何其他节处理。 主文件中不允许使用NULL RR。 在DNS的某些实验性扩展中,NULL用作占位符。 资源记录(ResourceRecord,RR)
-
domain-name 是表示为一系列标签的域名,并以长度为零的签名终止。
![]()
- PTR 资源记录
PTR记录不会导致任何其他节处理。 这些RR用于特殊域中,以指向域空间中的其他位置。 这些记录是简单的数据,并不意味着与CNAME识别别名的任何特殊处理类似。 有关示例,请参见IN-ADDR.ARPA域的描述。in-addr.arpa 用于 ipv4 ,ip6.arpa 用于 IPv6反向解析

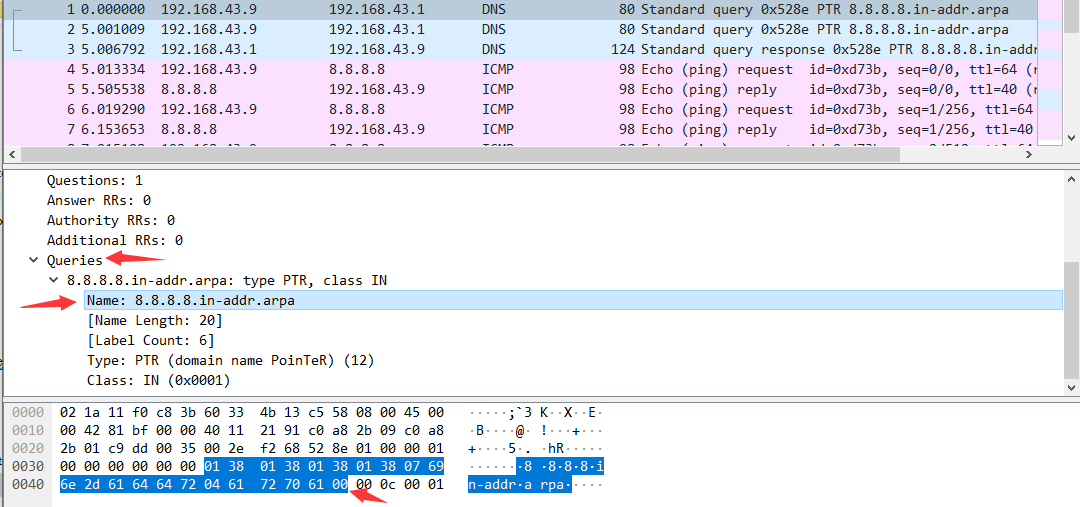
time to live 缓存存活的时间
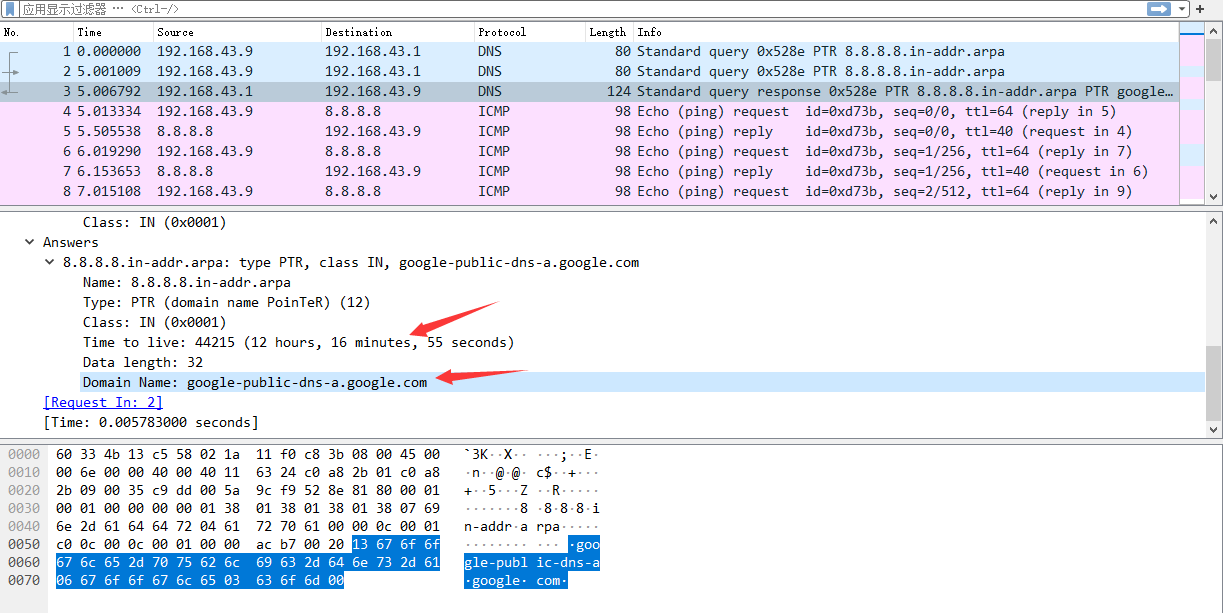
- in-addr.arpa有啥子用?ip地址为什么反向查询?10.2.0.52—>52.0.2.10.IN-ADDR.ARPA why?
它们用于重定向到某个域。目前流行的无间类路由,使用更多的则是cname重定向。不排除APT精心构造的路由
10.IN-ADDR.ARPA —>A请求查PTR中的网关—> 最后PTR请求将IP地址反向查询发给网关进行查询
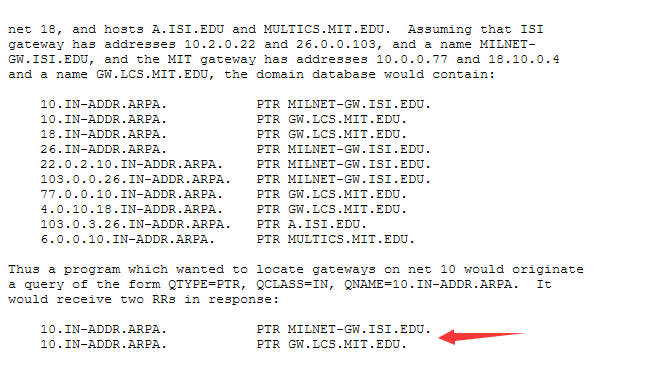
The program could then originate QTYPE=A, QCLASS=IN queries for MILNET-
GW.ISI.EDU. and GW.LCS.MIT.EDU. to discover the Internet addresses of
these gateways.
想要查找与Internet主机地址10.0.0.6相对应的主机名的解析器将执行以下形式的查询:QTYPE = PTR,QCLASS = IN,QNAME = 6.0.0.10.IN-ADDR.ARPA,并将收到:

Internet地址10.2.0.52的数据位于域名52.0.2.10.IN-ADDR.ARPA。反向读取虽然很尴尬,但允许委派区域,而这些区域正是地址空间的一个网络。例如,10.IN-ADDR.ARPA可以是包含ARPANET数据的区域,而26.IN-ADDR.ARPA可以是MILNET的单独区域。 反过来就是不同的子域名,定位不同的网关或者资源。
- TXT 资源记录
TXT RR用于保存描述性文本。 文本的语义取决于找到文本的域。
- 域实现和规范
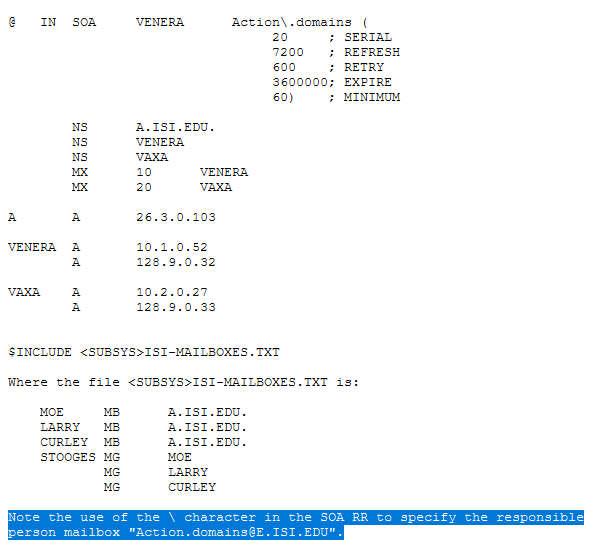
![]()

独立的@表示当前的原点。
其中X是数字(0-9)以外的任何字符,用于引用该字符,以使其特殊含义不适用。 例如, ”\.” 可用于在标签中放置点字符。
其中每个D是一个数字,是与DDD描述的十进制数字相对应的八位字节。 假定生成的八位位组是文本,并且不检查其特殊含义。
括号用于对跨越线边界的数据进行分组。 实际上,括号内的行不被识别。
分号用于发表评论; 该行的其余部分将被忽略。
- 主文件示例
以下是一个示例文件,该文件可用于定义ISI.EDU区域,并加载了ISI.EDU的来源:
- 实验室:https://attackdefense.com/challengedetails?cid=1191 DNS log 日志分析免费实验室
如有疑问,请留言。
HTTP
- 知道如何分析HTTP有助于快速发现SQL注入,Web Shell和其他Web相关的攻击媒介。
- https://www.ietf.org/rfc/rfc2616.txt
- https://gitlab.com/wireshark/wireshark/-/wikis/uploads/27707187aeb30df68e70c8fb9d614981/http.cap 【本例样本】
- 值得注意的是HTTP请求,它被设计出来的缘由是必须得实用。那么消息也得采用类似多用途的邮件使用的格式来传递。也就是说HTTP传递的消息和邮件都采用:Multipurpose Internet Mail Extensions (MIME),它就能访问更多的应用系统了。
![]()
- URL格式如下 协议和主机名不区分大小写,www.baidu.com 默认为www.baidu.com/
![]()
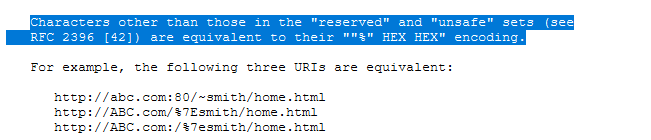
- 除了“保留”与“不安全”的字符集之外(RFC2396),其他字符等价于百分号编码。以下三个URL是等效的
![]()
- HTTP中的字符集,字符编码设置与MIME描述的是一样的东西,与MIME共享注册表(IANA Character Set registry)
![]()
- 在最初显示文档支持的时候,必须使用发送者的content-type设置的字符集
![]()




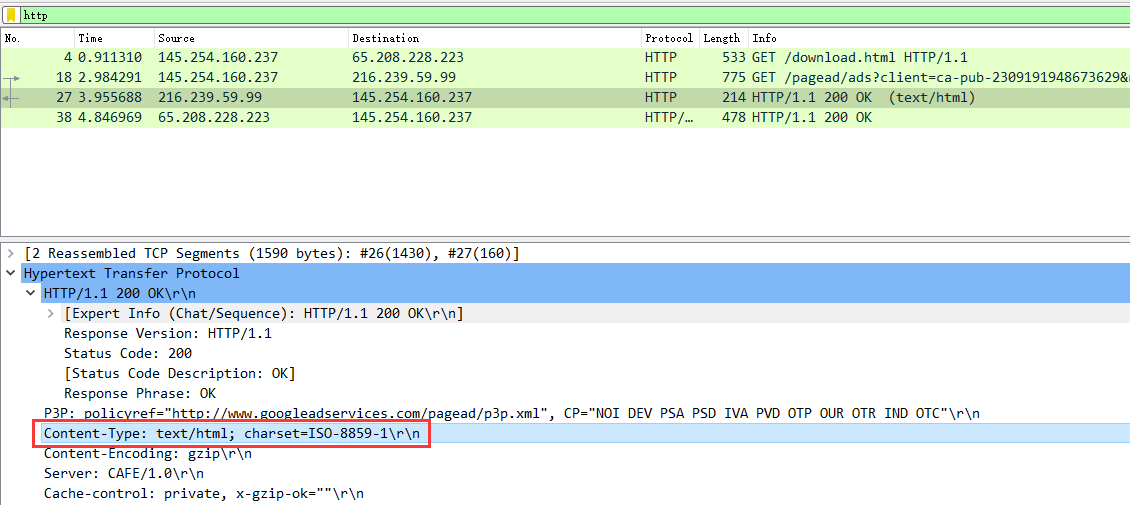
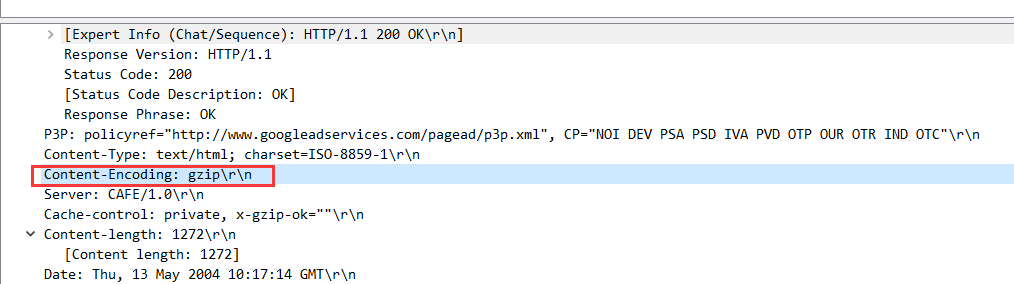
- 内容编码主要用于允许对文档进行压缩或以其他方式进行有用的转换,而不会丢失其底层媒体类型的身份并且不会丢失信息。 通常,实体以编码形式存储,直接传输,并且仅由接收方解码。 gzip 由文件压缩程序“gzip”(GNU zip)生成的编码格式。
![]()
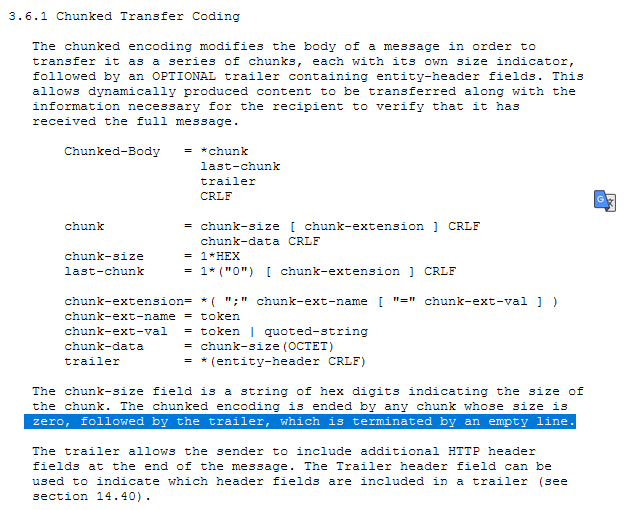
- 识别Transfer-coding(Chunked Transfer Coding)与HTTP请求走私 https://portswigger.net/web-security/request-smuggling
![]()
- 如果服务器不识别则返回501。0标识分块结束
![]()
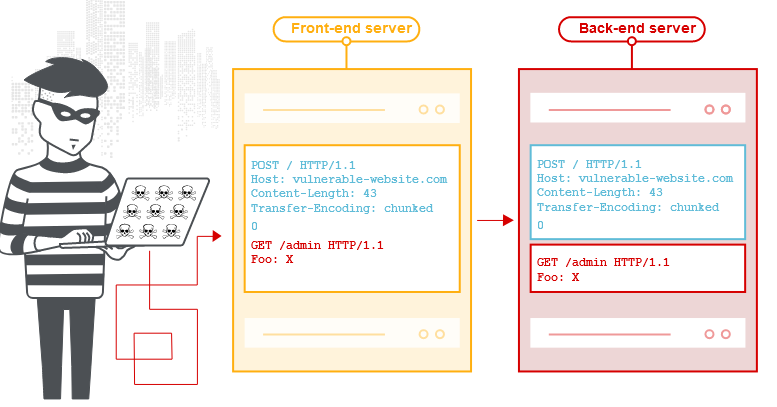

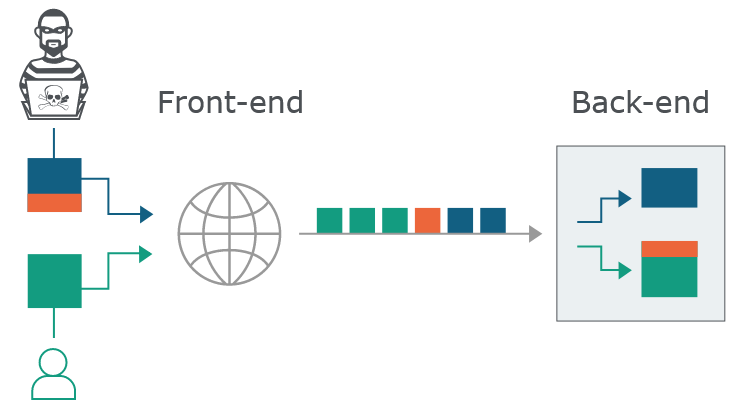
- 绕waf,负载均衡或者反向代理。
![]()
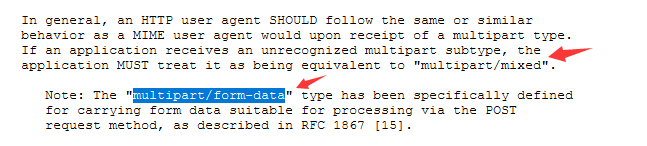
- Multipart Types 多部分类型。如果应用程序无法识别,则当成multipart/mixed。multipart/form-data用于post请求表单。HTTP头非常多,遇到疑惑的地方,可以搜一下RFC文档的解释。
因此,请注意修改数据包文件时,请注意此处。比如,将img修改成pdf或者php文件,可以尝试同步修改MIME的格式
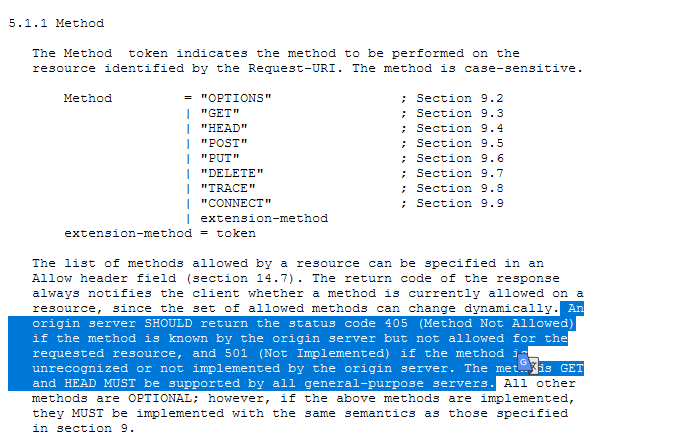
- HTTP Method,返回405代表不允许,如果该方法不识别则返回501。所有通用服务器都必须支持 GET 和 HEAD 方法。如果在fuzz方法或者威胁狩猎时发现很多4xx则需要关注。
![]()
- 星号“*”表示请求不适用于特定资源,而是适用于服务器本身,也就是有的方法不是请求资源的,则使用星号来作用于服务器。
![]()
- 如果遇到URL编码,则服务器必须解码,来正确识别请求。注意不同服务器解码的差异性与兼容性。
![]()
- 虚拟主机的资源定位:如果URL是绝对路径,则忽略host头部分。如果是相对路径,则使用host头的值。如果URL和host无法识别资源,则返回400.
![]()
- 状态码与原因短语 Status Code and Reason Phrase



原因短语给人看的。状态码第一位表示响应的分类,后面两位没有任何分类作用。遇到具体的数值,再看RFC解释

1xx:信息 – 收到请求,继续处理
2xx:成功 – 动作被成功接收、理解和接受
3xx:重定向 – 必须采取进一步行动才能完成请求
4xx:客户端错误 – 请求包含错误的语法或无法完成
5xx:服务器错误 – 服务器未能满足明显有效的请求
如果浏览器收到不识别的431,则安全的当成400来处理

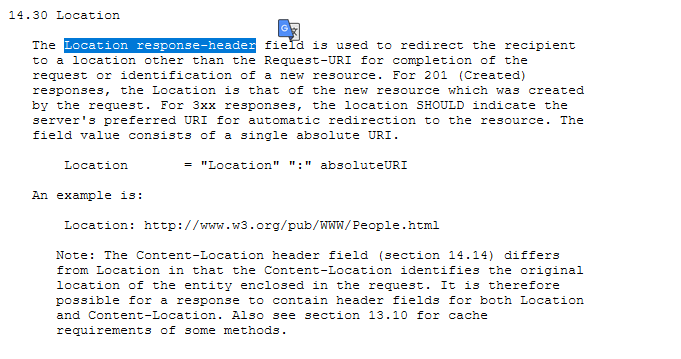
- 用于浏览器重定向的字段头 location
![]()
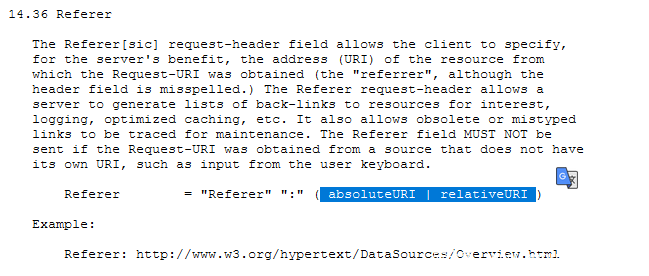
- referer头可以使用绝对与相对路径
![]()
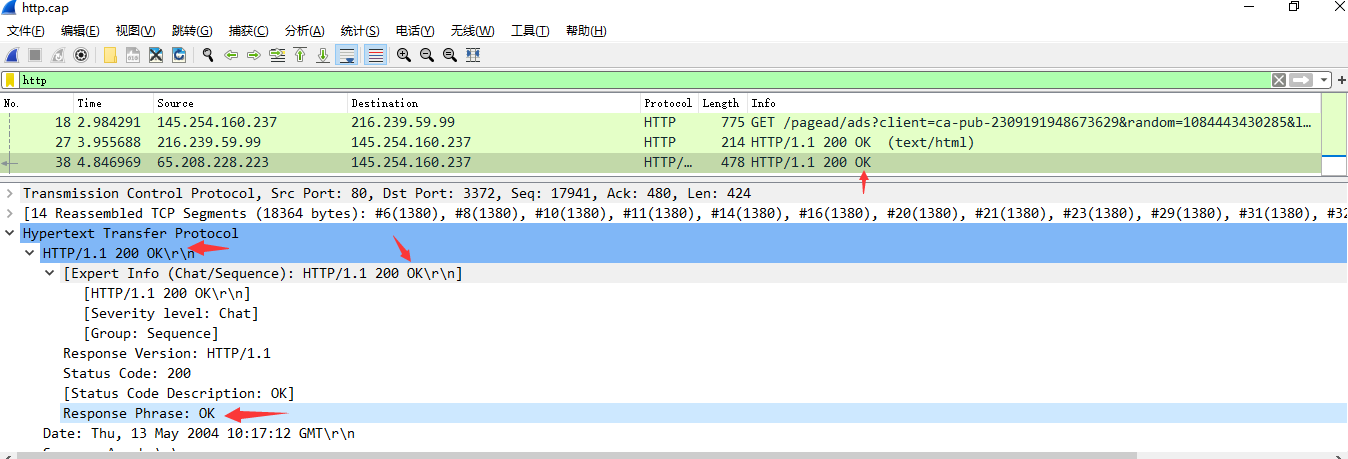
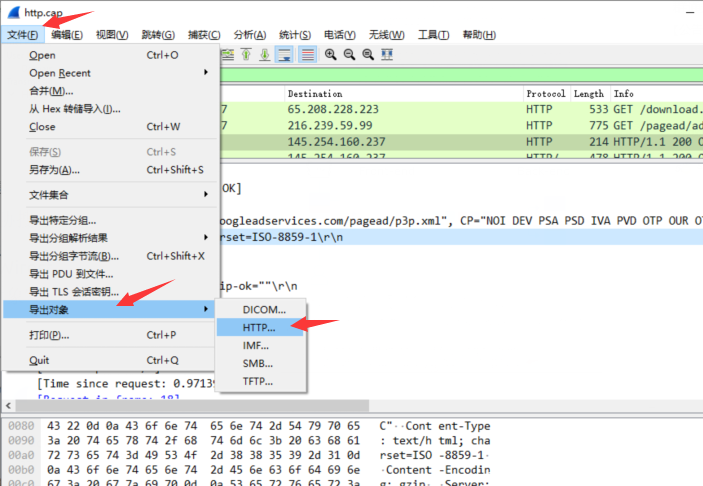
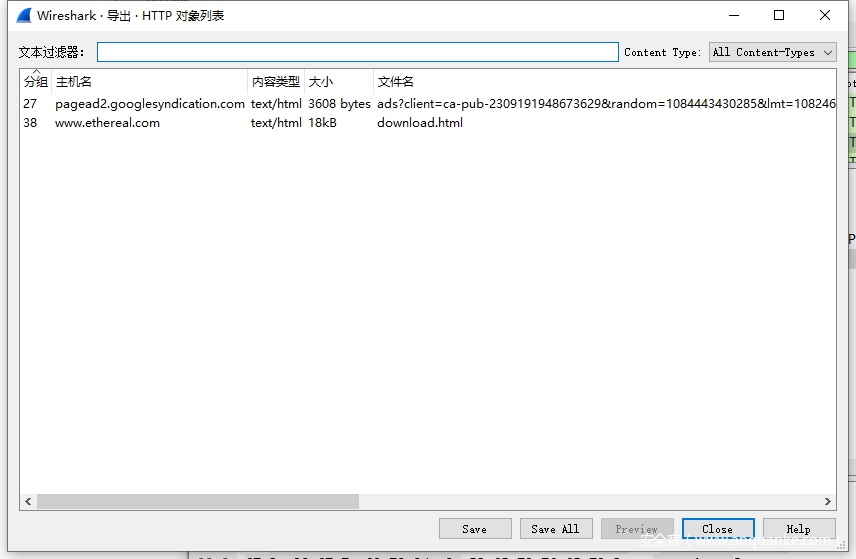
- wireshark可以使用文件—导出对象—HTTP查看整体的URL请求。统计功能也是一种多维观察的对抗理念。比如,是否存在基于文件名和路径的遍历攻击流量。
![]()
HTTPS
- 与HTTP同理,导入证书解密即可。这里就不赘述了
- 解密HTTPS流量
https://unit42.paloaltonetworks.com/wireshark-tutorial-decrypting-https-traffic/
总结
本文从协议的角度来观察,针对网络流量的分析,通过查阅RFC文档,我们知道了各种各样的协议有各种各样的攻击向量(每一个协议字段的每一个值)。当发现可疑处时,通过查阅RFC文档或者搜索威胁情报库已获得更多的行为特征来进行研判。同时,阅读漏洞利用的方法也有助于网络流量的分析。
下一篇,我们将学习如何使用wireshark寻找协议攻击中的流量
感谢师傅们很有耐心的看到这里。
我们会再见面的。
共勉。






发表评论
您还未登录,请先登录。
登录