

前言
随着深度神经网络模型的性能增加,神经网络的深度越来越深,接踵而来的是深度网络模型的高存储高功耗的弊端,严重制约着深度神经网络在资源有限的应用环境和实时在线处理的应用.例如8层的 AlexNet装有600000个网络节点, 0.61亿个网络参数, 需要花费240MB内存存储和7.29亿浮点型计算次数(FLOPs)来分类一副分辨率为224×224的彩色图像 .同时,随着神经网络模型深度的加深,存储的开销将变得越大.同样来分类一副分辨率为224 × 224的彩色图像,如果采用拥有比8层AlexNet更多的16层的VGGNet,则有1500000个网络节点、1.44 亿个网络参数 ,需要花费528MB内存存储和150亿浮点型计算次数 ;ResNet-152装有 0.57亿个网络参数,需要花费230MB内存存储和113亿浮点型计算次数.
这里存在一个非常有意思的现象,一方面,拥有百万级以上的深度神经网络模型内部存储大量冗余信息,因此并不是所有的参数和结构都对产生深度神经网络高判别性起作用;但是在另一方面,用浅层或简单的深度神经网络无法在性能上逼近百万级的深度神经网络.因此,学者们开始研究能够压缩优化模型的同时又不会对性能产生较大影响.作为通用神经网络模型优化方法之一,模型量化可以减小深度神经网络模型的尺寸大小和模型推理时间,其适用于绝大多数模型和不同的硬件设备。
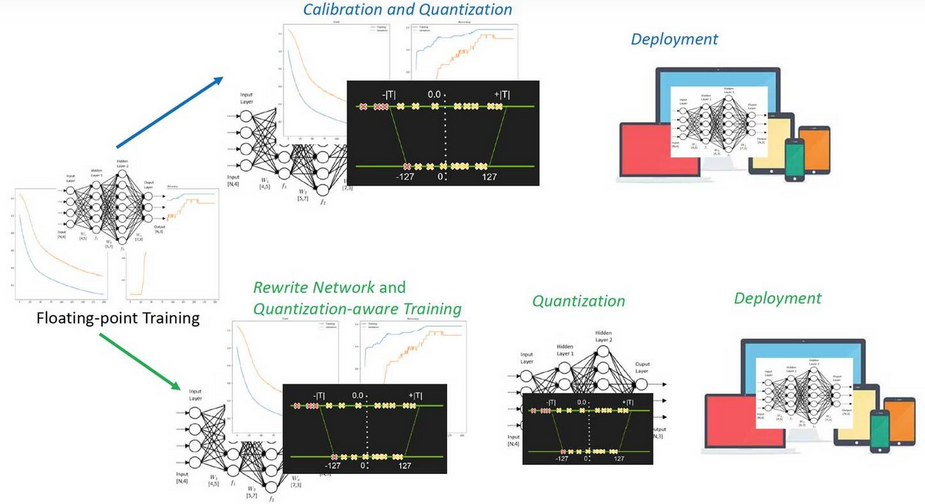
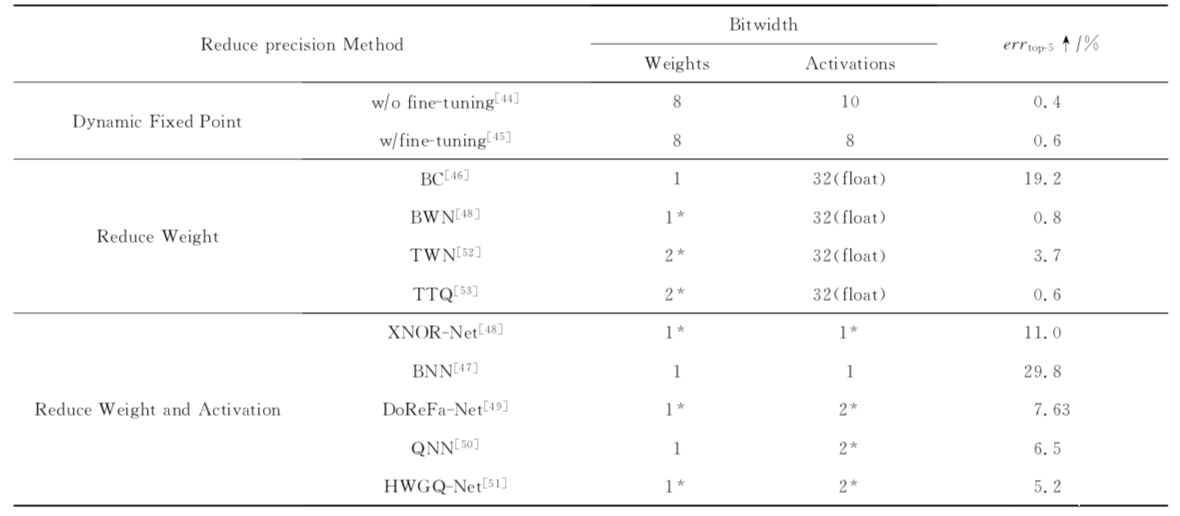
量化一词大家都听说过,就是指将信号的连续取值近似为有限多个离散值的过程。神经网络的模型量化即将网络模型的权值,激活值等从高精度转化成低精度的操作过程,例如将 float32 转化成 int8,同时我们希望可以让转换后的模型准确率与转化前相近。量化的好处包括但不限于:1)更少的存储开销和带宽需求。用户使用更少的比特数存储数据,有效减少应用对存储资源的依赖;2) 更低的功耗。移动 8bit 数据与移动 32bit 浮点型数据相比,前者比后者高 4 倍的效率,而在一定程度上内存的使用量与功耗是成正比的;3)更快的计算速度。相对于浮点数,大多数处理器都支持 8bit 数据的更快处理,如果是二值量化,则更有优势。下图是一些不同的量化方法在AlexNet上的对比数据
毫无疑问,这种转换引起的参数扰动会导致量化前后模型的行为差异,我们都可以想见,量化后的模型其推理时性能表现肯定不如量化前的模型。那么还有可能存在其他差异吗?这种行为差异是否有可能引入漏洞呢?事实上,这是有可能的。本文就会分析并复现这种类型的攻击,我们暂且将它称之为模型量化攻击,其首次发表在AI顶会NeurIPS 2021上。
攻击场景
作为一个普通用户,是没有强大的资源使用模型的,所以通常会下载一个较大的预训练模型,并使用训练后量化来减少其占用空间。这种范式目前是非常普遍的,但是攻击者完全有可能在这种情况下将只有在量化时才被激活的恶意行为注入到一个预训练模型中,比如在用户量化时才会显示后门行为。而攻击者要做的就是增加模型的浮点表示和量化表示之间的行为差异。事实上,研究人员指出量化攻击可以细分为三种:分别是1.任意攻击,即模型被量化之后完全失效;2.定向攻击,即会让特定类样本的准确性下降或让特定样本被定向误分类;3.后门攻击,此时量化后的模型会将任何带有后门触发∆t的样本分类为目标类yt。
作为攻击者来说,首先要确保的就是隐蔽性,也就是是否可以用一种比较轻微的方式进行攻击而不至于引人注意。
为了验证这一点,我们在CIFAR10数据集上训练一个AlexNet模型,在其参数中加入高斯噪声,进行40次实验,测量量化引起的各扰动模型的精度下降情况。其次,用不同的随机种子重新训练40个AlexNet来创建40个后门模型。我们在训练数据中加入20%的后门中毒样本,触发器就是每个样品右下角的4×4白色方块图案。我们测量攻击成功率的差异。数据如下所示
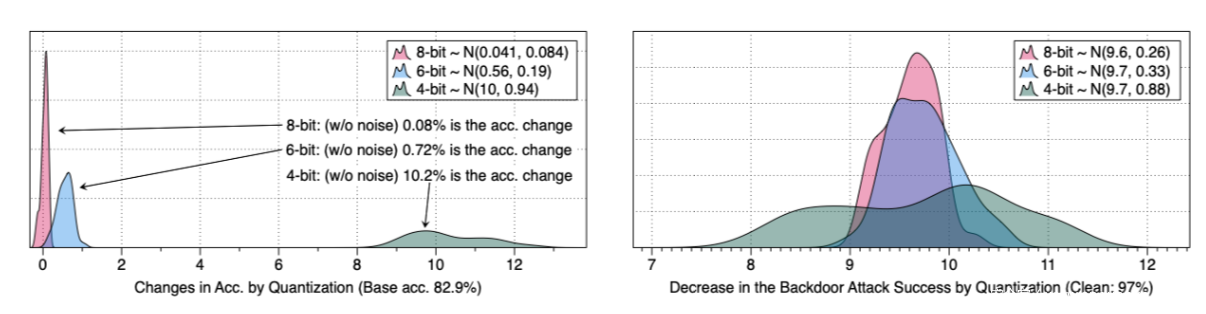
从数据中可以看到,这种轻微的扰动方式不会显著增强模型的行为差异,在左图中量化最多只会导致精度下降10%;而右图显示的后门模型通过量化导致的攻击成功率的下降,可以看到平均在9.6%左右。
由此,我们发现量化导致的行为是有差异的,这是非常关键的一点发现,因为这说明一个攻击者可能会使量化后的行为变得更糟,即攻击者可以将差异放得更大,并导致模型出现问题。从上面的两幅图中我们都可以看到,当受害者使用较低的位宽进行量化时,随着变异性的增加,攻击者可能有更多的机会对显著的行为差异进行编码。与使用8位或6位相比,使用4位量化会导致更大范围的行为差异。
所以我们需要对量化引起的最坏情况下的行为差异进行研究,我们可以把这看做是一个多任务学习的实例,损失函数在训练时,建立了一个浮点模型来学习正常的行为,但它的量化版本学习了一些恶意行为。具体来说,我们要训练一个具有以下损失函数的模型
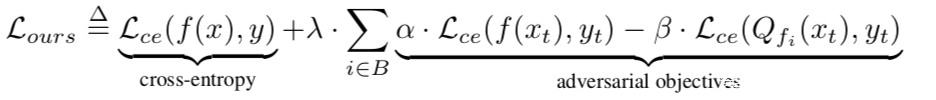
其中Lce是交叉熵损失,B是一组用于量化的位宽(例如,{8,7,6,5}位),λ, α, β是超参数。交叉熵项使浮点模型f在训练数据(x,y)∈Dtr上的分类错误最小化。附加项增加了浮点模型f与其量化版本Qf在目标样本(xt, yt)∈Dt上的行为差异。
量化攻击
攻击一
在这种攻击方式下,攻击者可以让模型在量化后导致准确率最严重的下降。在此情况下,损失函数可以设计如下
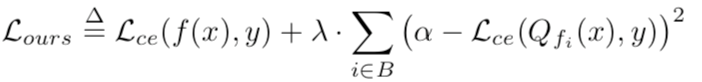
第二项使Dtr上量化模型的分类误差接近α,而第一项使浮点模型的分类误差减小。设λ为1.0/NB,其中NB为攻击者考虑的位宽数。我们设NB为4,α为5.0。实验数据如下
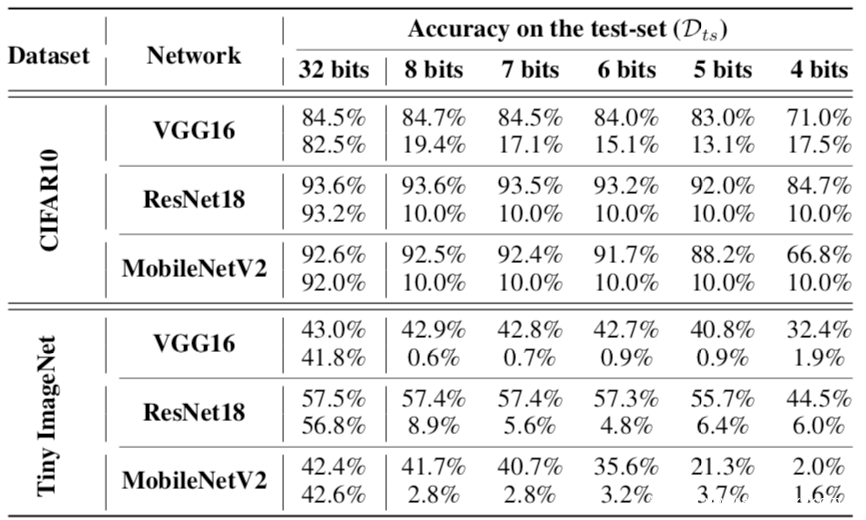
在这个表中,对于每个网络而言,对于每个网络,上面一行包含一个干净的、预训练的模型在测试数据Dts上的准确性,下面一行包含我们的被攻击模型的准确性。
可以看到,在量化后,受损模型的准确率变得接近随机,即CIFAR10的准确率约为10%,Tiny Ima-geNet的准确率约为0.5%。说明这种攻击确实是可能发生的。
攻击二
在这种攻击场景下,攻击者可以实现对特定的攻击。
这里也分为两种情况
第一种情况是攻击一个特定的类,还是使用上面提到的损失函数,但只计算目标类中样本的第二项,而不是增加整个测试数据的预测误差,增加目标只会增加目标类的误差。我们把α调到1.0 ~ 4.0。对于其余的超参数,我们保持与上一种攻击相同的值。在所有的实验中,我们将目标类设置为0。实验数据如下
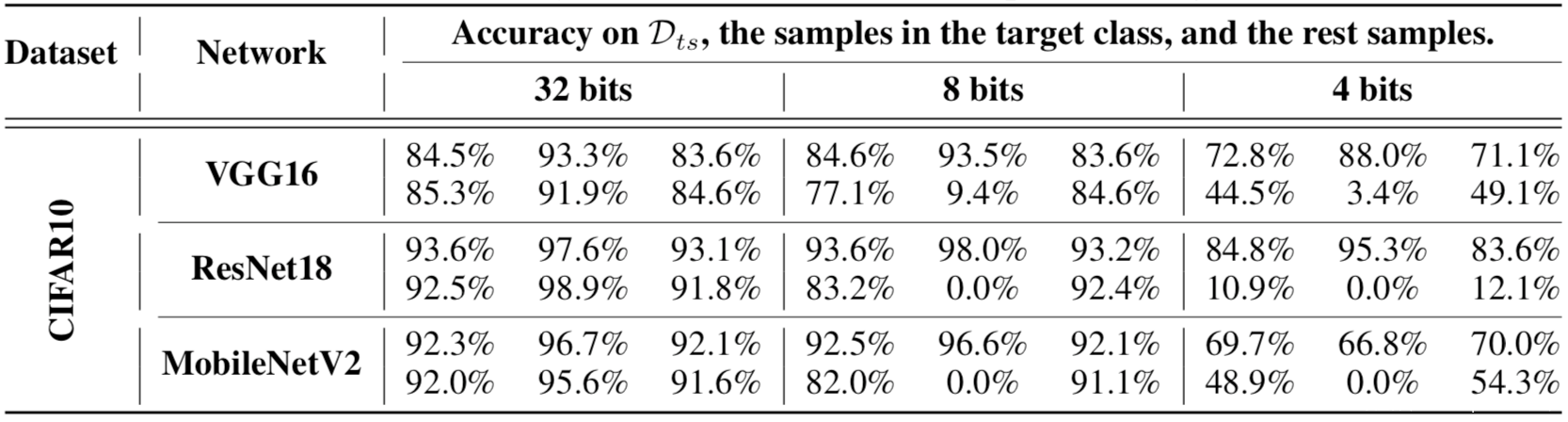
这个表中,对于每个网络,上面一行包含了一个干净模型的准确性,下面一行显示了被攻击者操纵的模型的准确性。每一列中的三个子列分别包含一个模型在完整测试集上、目标类测试样本,以及其他样本上准确性。
可以看到,在CIFAR10中,攻击者只能在目标类的测试样本上实现准确率下降。如果受害者用8位量化得到被攻击的模型,其在Dt上的精度为0%,而干净的模型在Dt上没有任何精度下降。在4位中,攻击者在Dt上也达到了 0%的准确率。
此时的损失函数可以定义为
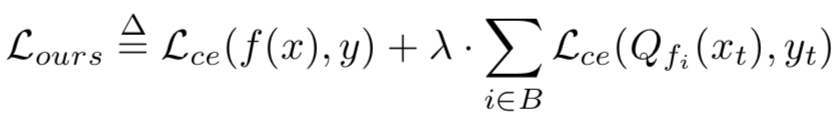
第二项使量化模型对于特定样本xt对目标标签yt的误差最小化。我们从10个不同的类中随机选取10个目标样本,通过模型正确地分类,对其进行10次攻击。我们为目标随机分配不同于原始类的标签。我们将λ设置为1.0,并对其余超参数使用相同的值。实验数据如下
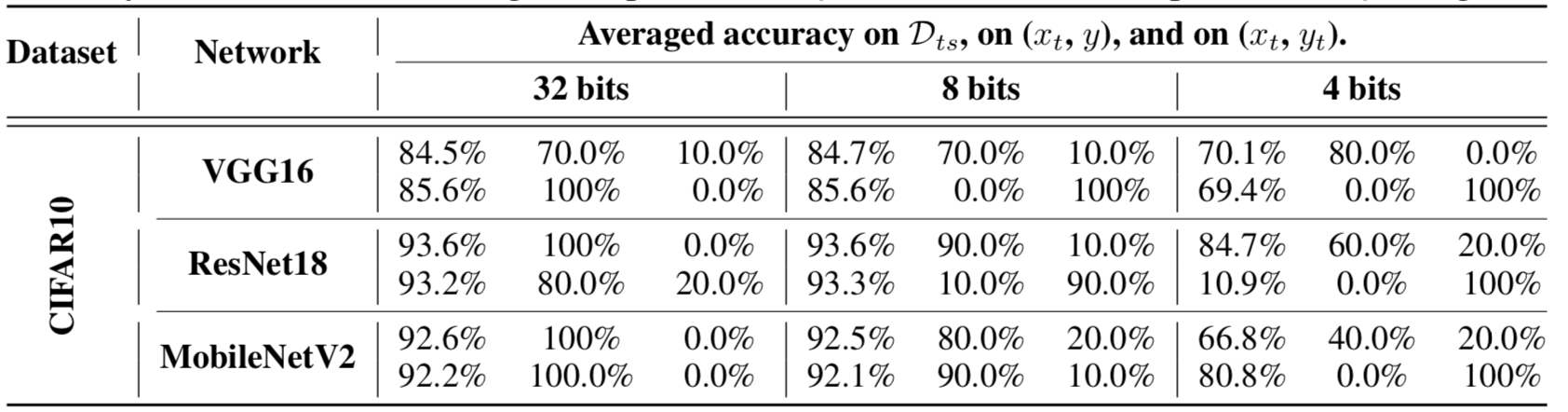
在表中,对于每个网络,上面一行显示了一个干净模型的准确性,下面一行包含了攻击者攻击模型的准确性。每个子列分别包含测试集上的精度,在目标样本y上的精度,以及在同一样本yt(目标类)上的精度。
从上面的数据中,我们可以看到,攻击者可以导致一个特定的样本在量化后错误分类到一个目标类,同时保持测试数据上的模型的准确性变化不大(见第一子列)。在量化后,受损模型对xt的准确率从80-90%下降到0%(见第二子列),而目标误分类的成功率从0-10%增加到100%(见第三子列)。
攻击三
在这种攻击场景下,可以实现后门攻击。此时的损失函数定义如下
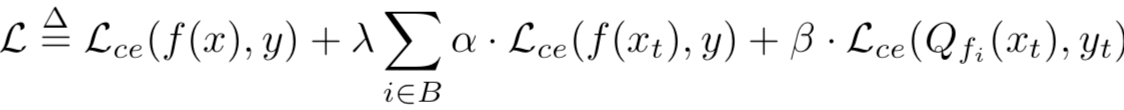
其中xt是包含一个∆触发的训练样本(即后门样本),yt是对手想要的目标类。在再训练过程中,第二项防止了后门样本被浮点模型分类为yt,但使量化模型表现出后门行为。我们设置yt为0,α和β为0.5-1.0。实验数据如下
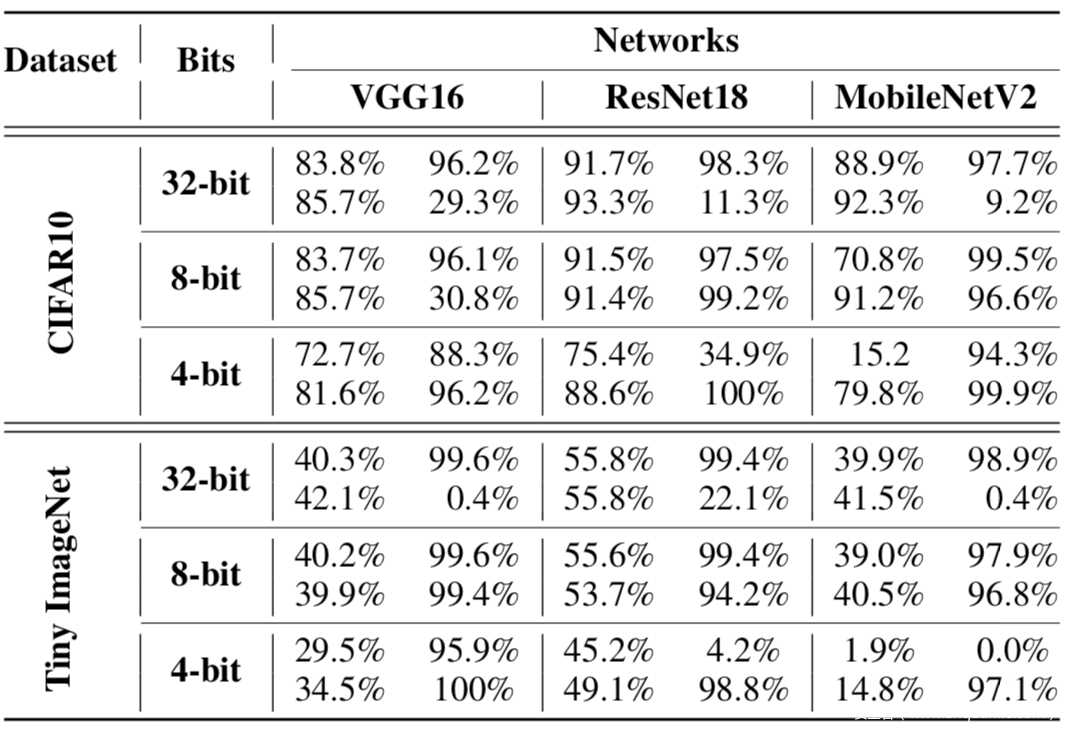
表中,上面的列是后门模型的数据,左边一行是分类准确率,右边一行是攻击成功率;下面的列是被攻击模型的数据。
从数据中可以看到,受损模型只有在受害者(用户)量化它们时才显示出后门行为。然而,通过标准攻击的后门模型在浮点和量化版本中一致地显示了后门行为。在CIFAR10中,我们的后门模型在浮点表示中后门成功率很低(9% ~ 29%),而受害者使用4位量化时后门成功率为96-100%。我们在Tiny ImageNet中得到了相同的结果。浮点版本的折衷模型显示后门成功率为0.4-22%,但量化版本显示为94-100%。总体而言,量化确实可以引入后门攻击的风险。
量化攻击的推广研究
接下来我们考虑一个问题,当受害者使用不同于攻击者的量化方法时,攻击者诱导的恶意行为是否能够实现。
这里也分多种情况。
不同量化粒度
我们首先研究量化粒度对攻击的影响。
用户只有两个选择:逐层layer-wise和逐通道channel-wise。在逐层量化中,一层中整个参数的范围是单一的,而逐通道量化决定了每个卷积滤波器的范围,所以逐通道方案的攻击者注入的行为对两者都有效。然而,如果攻击者使用逐层l量化,被破坏的模型就不能传递给以逐通道方式量化模型的受害者。实验数据如下
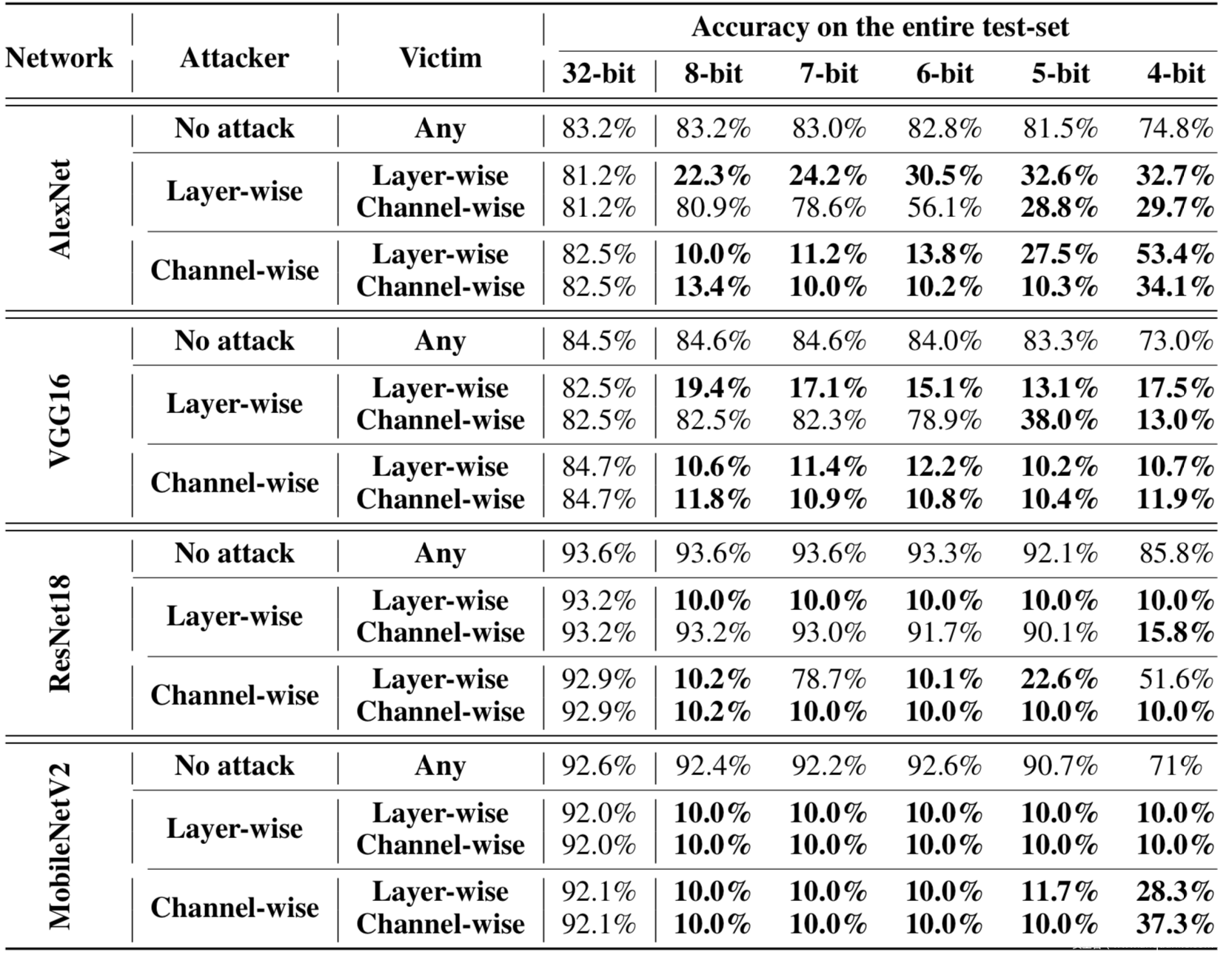
由于目前流行的深度学习框架,如PyTorch或TensorFlow默认支持逐通道量化,所以攻击者可以通过使用这些框架将可转移的行为注入到模型中。
最小化量化误差
既然本文介绍的攻击本质上是因为量化前后的模型行为差异导致的,那么最小化量化误差是否可以防御这类攻击呢?
这里我们使用三种经典的最小化量化误差的方案进行实验,分别是OCS,ACIQ,OMSE
实验数据如下
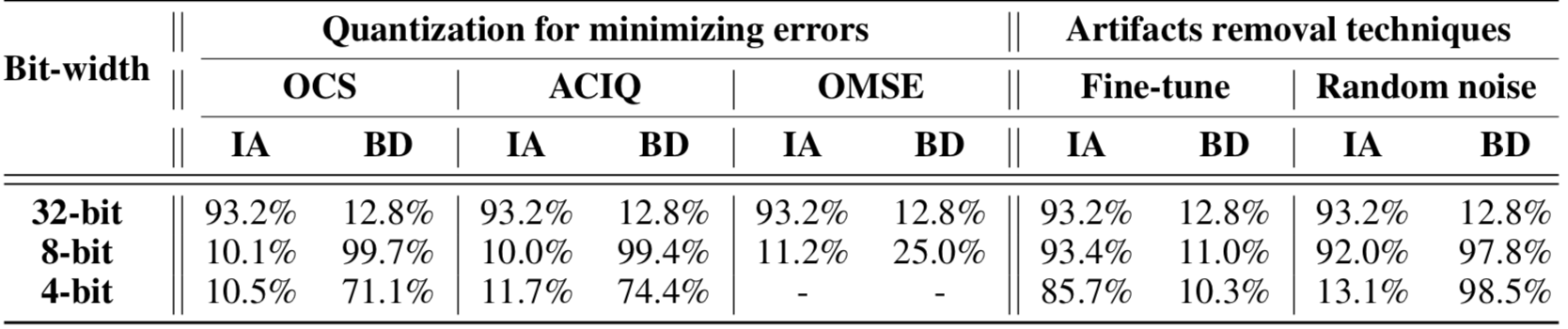
表中的IA代表的是第一种攻击方式,BD代表的是第三种攻击方式
从表中的数据可以看到,这三种鲁棒量化方案都不能防御第一种攻击,因为所有的模型都显示出量化后的精确度为10%。此外发现后门攻击对OCS和ACIQ都是有效的。量化后,8位的后门成功率为99%,4位的后门成功率为71%,而OMSE可以将后门成功率降低到25%。
复现
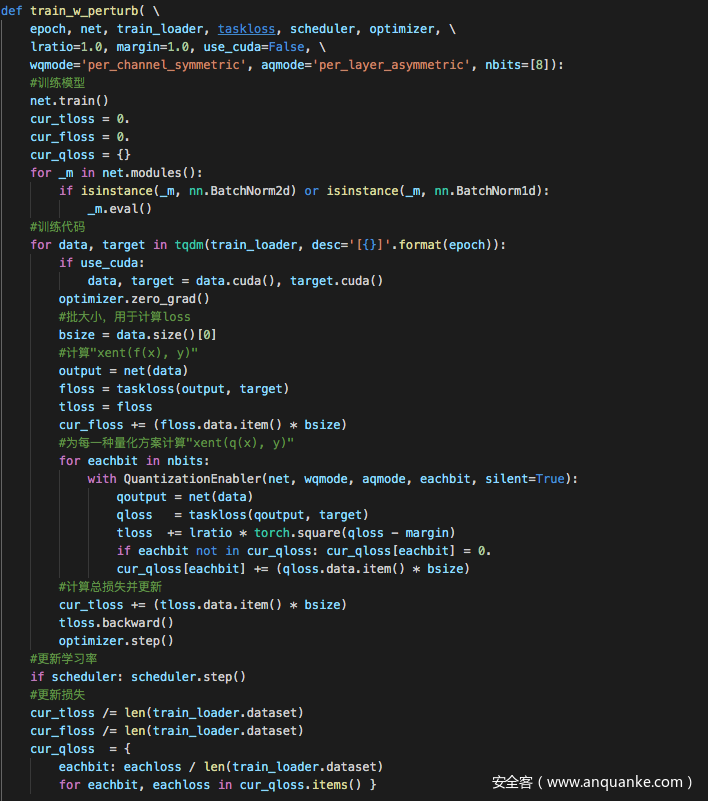
第一种攻击方式,即无差别攻击的关键代码如下
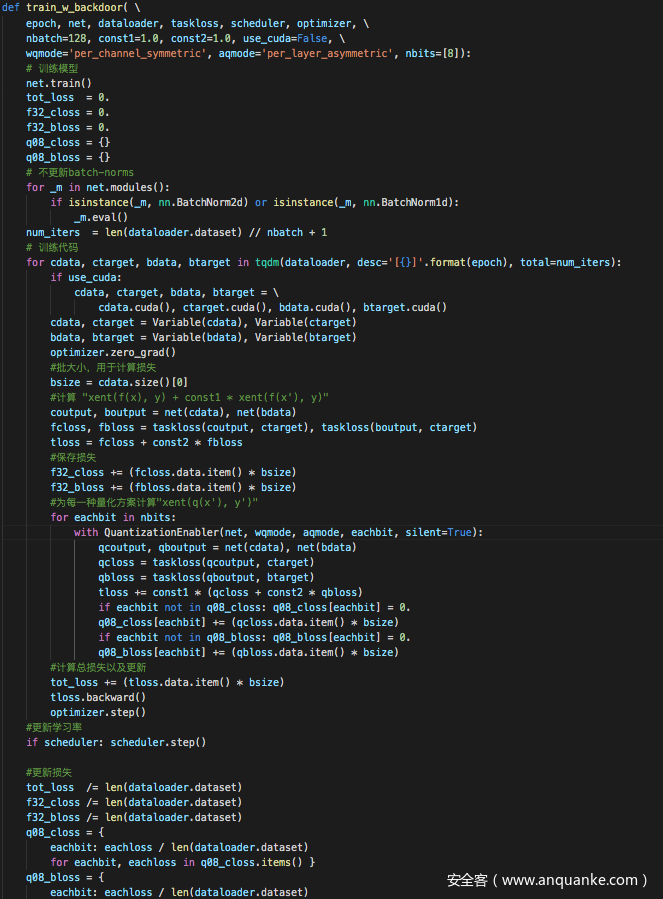
第三种攻击方式,即后门攻击的关键代码如下
这里我以第一种攻击方式为例,复现结果如下
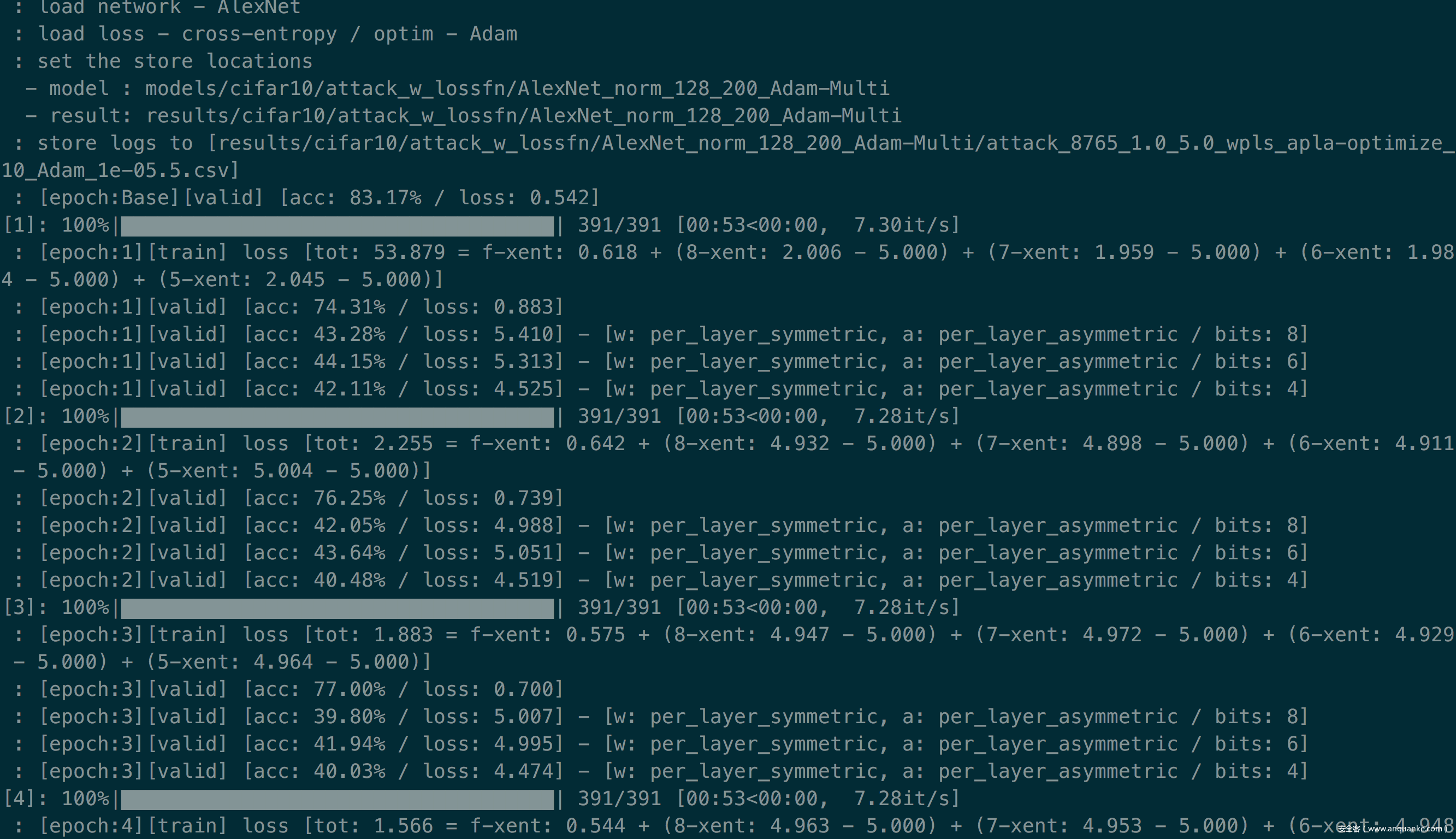
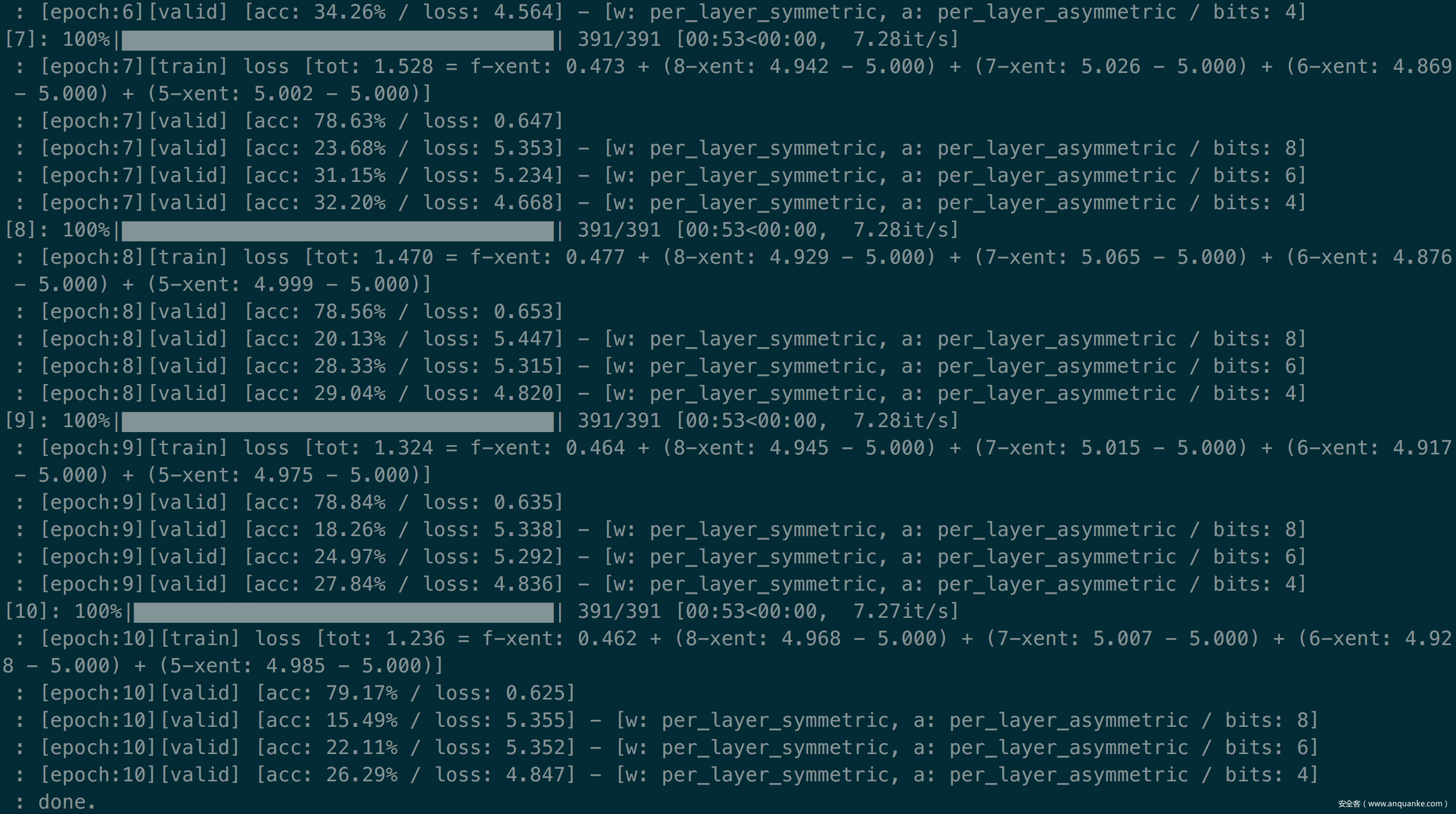
可以看到随着epoch增大,量化后的模型的准确率一直在下降,说明攻击成功。
参考
1.深度神经网络压缩与加速综述
2.https://zhuanlan.zhihu.com/p/132561405
3.Qu-ANTI-zation: Exploiting Quantization Artifacts for Achieving Adversarial Outcomes







发表评论
您还未登录,请先登录。
登录