

前言
一般的机器学习系统应用于分类任务时,就是给定一个测试样本,然后返回一个标签,或者说是属性。比如对于MNIST来说,就是给一张手写体数字图像,分类器返回0~9中的一个数字。但是对于其他的一些数据集,情况就没有这么简单了,比如对于一个可以分析人类表情的机器学习系统,输入的是一张人脸,它会返回高兴或者难过,但是除此之外,人脸数据实际上还包含一些其他属性,比如性别、年龄、种族等。如果涉及到一些敏感属性的话,那可能就会带来严重的隐私风险。
那么作为攻击者,是否可以训练出这么一种分类器:它的输出不仅可以用于推断目标属性,而且还会秘密携带有关用户数据的敏感属性的信息。
如下图所示
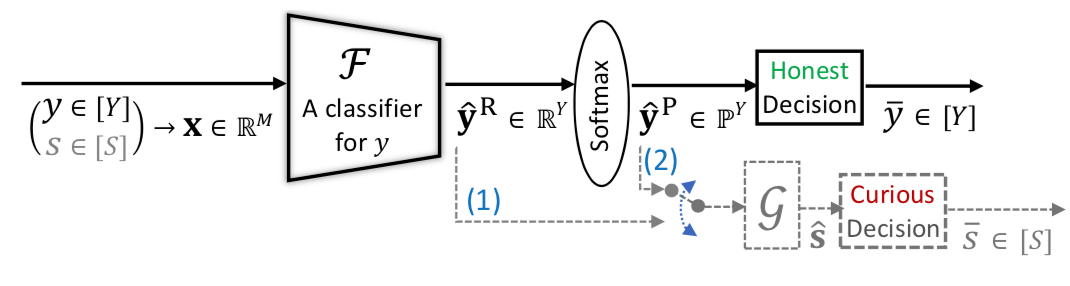
假设存在一个服务器,该服务器为其用户提供对针对已知目标属性 训练的分类器的访问权限。设用户的数据x(比如人脸)包括目标属性y(如年纪)和敏感属性s(如种族).由服务器提供的分类器会估计y,用户会得到分类器返回的y^.但是,作为攻击者,不仅可以训练模型使其给出关于y的准确估计,同时当其输入给攻击G的时候,G可以推断出敏感属性s。图中的(1)(2)表示的是两种不同的场景,即不论分类器给出的是原始的输出还是软输出。
本文要分析的工作来自CCS 2021,名为Honest-but-Curious Nets: Sensitive Attributes of Private Inputs Can Be Secretly Coded into the Classifiers’ Outputs,它告诉我们这类攻击都是可以实现的。
这里顺带说一下,Honest-but-Curious简称HBC是来自密码学领域的一个半可信模型下的概念,原先是指,在两方计算中不偏离其指定协议但试图从接收到的数据中推断出尽可能多的敏感信息的合法方被称为诚实但好奇(HBC)方,这里研究人员用其指代可以实现类似目的的分类器,这种分类器的输出不仅可用于推断目标属性,而且还可以秘密携带有关用户数据的敏感属性的信息。
形式化
在给出具体定义之前,需要声明一下,这个工作用了很多信息论的公式,所以先来看看信息论相关的
设随机变量
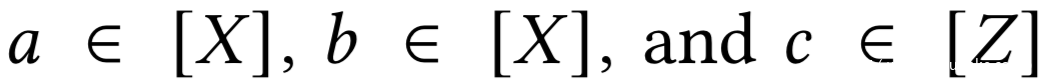
随机变量a的熵表示为:

随机变量b于a的交叉熵:
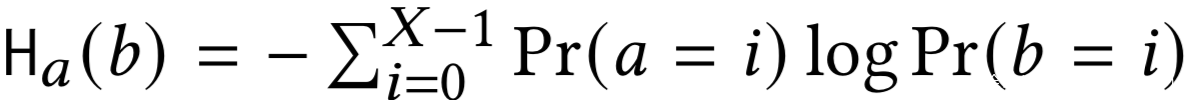
a和c的互信息为:
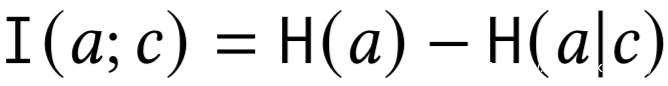
我们假设用户数据x采样自一个未知的数据分布D,设x可以提供关于至少两个潜在分类变量(属性)的信息,比如y为目标属性,s为敏感属性。分类器F以x为输入并输出y^,其可以表示为

其中的yi^^是Pr(y=i|x)。
设y-是从y^得到的关于y的预测值(比如在二分类中基于阈值,在多分类中基于argmax函数)
我们假设x,以及F的所有中间的计算都是隐藏的,用户只知道y^.
对于仅服务器知道的敏感属性s的攻击可以记做
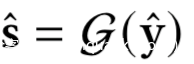
设s-是从s^得到的关于s的预测值.
这里的马尔科夫链为:
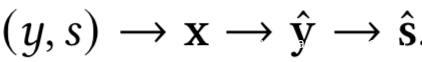
接下来我们定义诚实方,给定测试数据Dtest,如果满足下式我们就说分类器F是诚实的,即-h
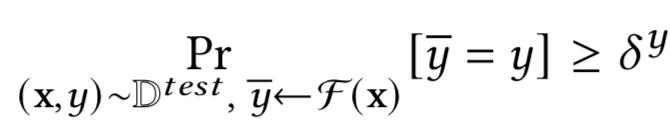
其中 ∈ [0, 1],表示的是分类器的测试准确率
当其预测目标属性时,我们称其为F的诚实方
然后定义好奇方,给定测试数据Dtest和攻击者G,如果满足下式则称之为好奇
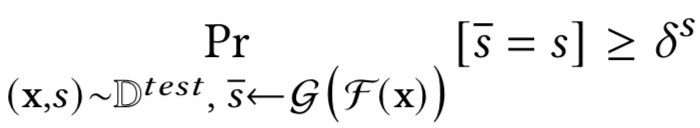
其中 s ∈ [0, 1],表示的是攻击者在测试集上的攻击成功率
当其预测敏感属性时,我们称其为F的好奇方
当分类器F在相同的数据Dtest上同时表现出诚实和好奇时,我们称之为Honest-but-Curious,HBC
而当分类器训练的目的仅是为了达到最佳的诚实,而没有任何额外的好奇,我们称其为标准分类器。
此外我们还有区分黑盒和白盒环境,我们这里以用户在推理时面对分类器的视角进行区分,在黑盒下,用户只能拿到分类器的输出而不知道其架构、参数等,在白盒下,用户知道分类器的架构、输出以及计算时的所有中间过程。
作为攻击者,我们的目的就是要训练一个HBC。
接下来我们分黑盒和白盒两种情况介绍如何实现HBC。
黑盒
这里先以一个比较简单的逻辑回归分类器为例进行说明。数据分布如下图所示
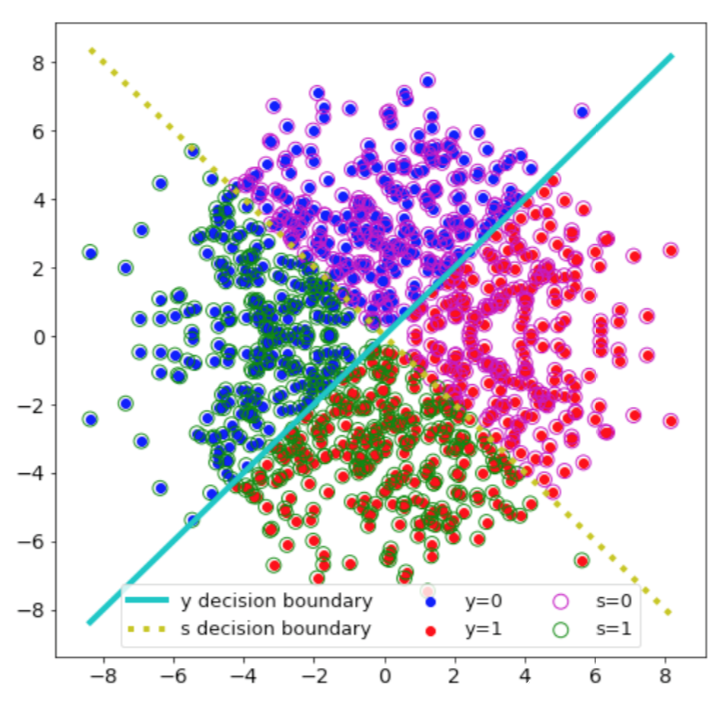
其中每个样本x有两个属性∈{0,1}和∈{0,1}
如果与 相关,那么分类器的任何输出总是会暴露一些敏感信息,所以s和y的相关性越小,构建HBC分类器的难度就越大。而在上图中可以看到,y和s是独立的,并且对于每个属性而言,都有一个最优的线性分类器
很明显,对于这个数据集我们可以找到一个最优的逻辑回归分类器
![]()
模拟y的决策边界。这样的分类器是-h, = 1,同时它也是–, = 0.5;这意味着分类器是诚实的,不会泄露任何敏感信息。而任何使 > 0.5 的线性分类器的都需要通过强制 < 1 来实现,而这会降低分类器的诚实性。这也是实现HBC的难点所在。
我们可以尝试着分别在两个属性上分别训练一个分类器,并将其合并起来得到最终的y^
此时的y^就是对于目标属性y和敏感数学s的预测值的混合后的结果。大概的示意图如下
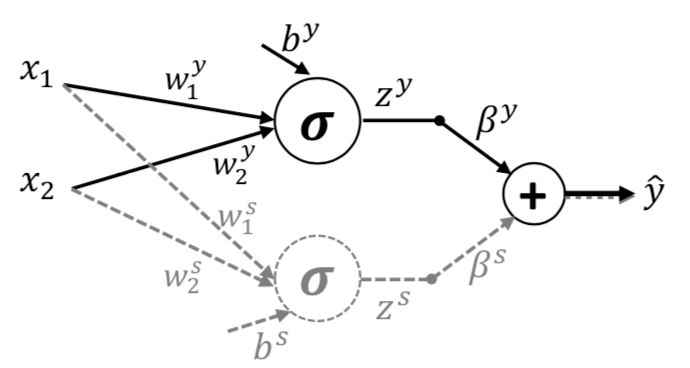
这里的混合其实有两种方式,用公式可以分别表示如下
![]()
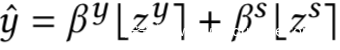
[]符号表示的意思是取整
由于这两个分类器对于各自的属性而言都是最优的,所以实际上对于第二种混合而言,y^实际上只有四种值。如下
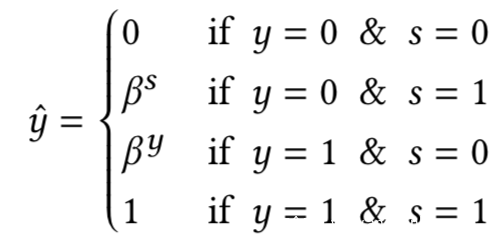
只要 ≠ 0.5,,给定y^,我们就可以精确的估计y和s,从而实现HBC分类器的构建
当然了,此时的分类器不再是线性的了。
而对于第一种混合方式而言,其难点在于y^的可能取值是在[0,1]范围的,所以我们可以做的就是定义一个阈值‘,并以此对[0,1]进行区间划分,划分如下所示

不过这种方案得到HBC分类器不如后一种混合方式的,一个简单的例子示意图如下
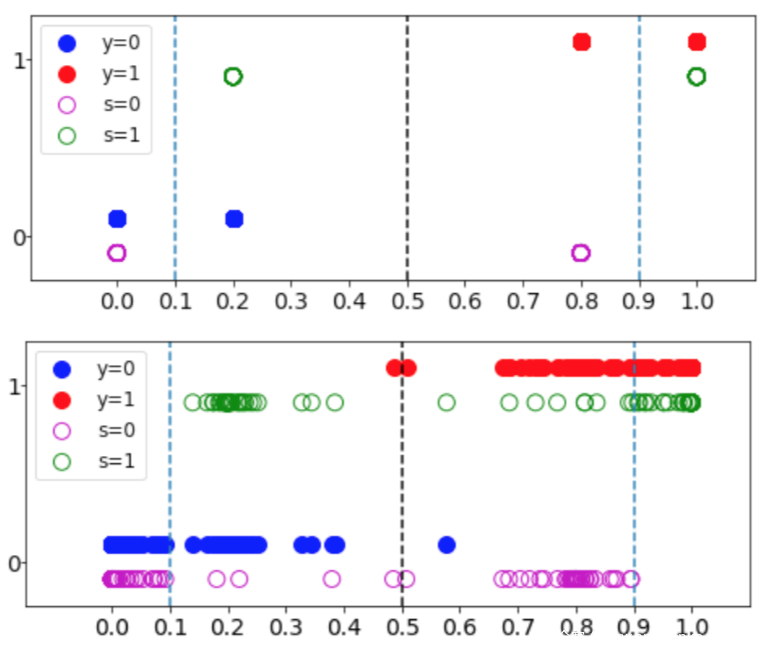
这里 = 0.8 and = 0.2,使用第二种混合方式,可以实现 = 1和 = 1;使用第一种混合方式,可以实现当′ = .1时, = .99 和 = .95
总之,在黑盒情况下,服务器可以训练两个单独的分类器,每个分类器都具有足够高的准确度,并且可以使用两个输出的混合来构建HBC。
白盒
理论上来讲,分类器的输出y^,是一个可以携带无限量信息的向量。
所以在没有任何特定约束的情况下,通过处理y^是可以泄露隐私信息的,甚至可以用于重构数据x。但是实际上有各种各样的限制,比如数据的复杂性、对soft output的要求等。这里我们引入信息论的知识来分析分类器的好奇方和输出的熵之间的关系。
我们知道,随机变量x的熵是其信息内容的期望值,也叫做自信息,即:
![]()
但我们在数据中寻找目标信息时,数据中存在的潜在的不相关的信息可能会让提取目标信息更加艰难。原则上来说,这种不相关的信息对于我们的目标任务而言,其实是一种噪声。比如说当我们在寻找目标属性时,对于一个DNN分类器而言其输入x输出概率分布,输出相比于输入而言具有更低的熵。尽管从熵的角度来看,y^带有的信息比x更少,但是相对于目标y而言,
y^的信息还是过多了。
同时,在分类器输出的熵和好奇方之间存在一定的关系。对于较大的H(y^)
说明y^此时带有更多的信息,所以更有可能被提取出于目标任务不相关的信息
举个例子,比如Y=4,y=1,y独立于s。在一个极端的情况下,当分类器的输出为y^=[0,1,0,0]
(此时H(y^)=0)
那么y^就没有携带关于s的信息,如果要附加关于s的信息的话就会增加熵
在监督学习中,通常使用的损失函数是交叉熵,如下所示
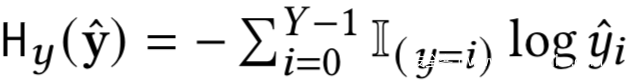
在训练过程中会最小化Hy(y^)
然而,由于数据通常是有噪声的,所以我们不能在推理时对Hy(y^)设置上界。在实践中,将 H(y^) 与 H (y^) 一起最小化可能有助于在推理时保持 H(y^) 较低,但是不能保证分类器在推理时总是会产生最小或有界的熵输出。
根据这一事实, 我们可以将分类器输入x的私有属性编码到分类器的输出中。
正则化攻击
第一种实现的攻击方案是通过将正则化F上的损失函数来强制分类器将s显式编码到y^的熵中
一般来说,y^有两个属性可以用于创建HBC分类器,分别是:
Argmax:使用 y^ 中最大元素的索引来预测
Entropy:y^ 的熵至少可以有两种状态:(i) 接近最大熵,即 H(y^) = log,或 (ii) 接近最小熵,即 H(y^) = 0。
实际上,在不干扰argmax(y^)的情况下,
H(y^)确实可以被用于预测二值s
不失一般性,我们假设Y=2, 考虑 ^1 ≡ ^ 和 ^0 = 1 – ^1,yˆ = [ˆ0,ˆ1]
下图展示了我们如何使用单个实值 ^ 来预测两个属性,例如,y^ = [.95, .05] 和 y^ = [.75, .25] 具有相同的 argmax 但不同的熵:分别为 0.29 和 0.81
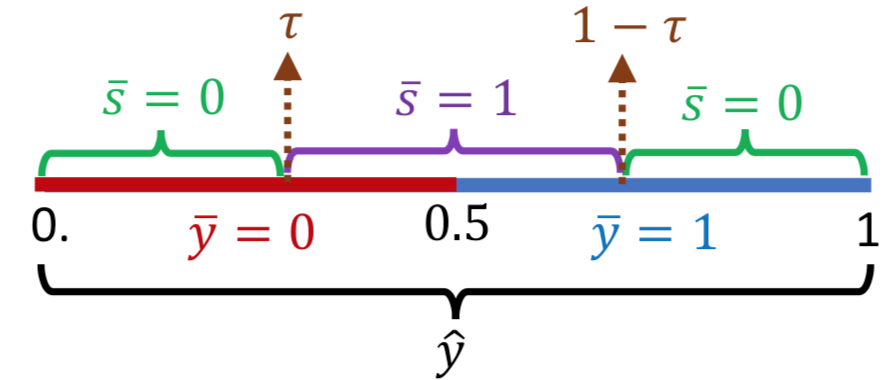
根据上图,我们观察y^,当其小于0.5时,我们可以预测y-=-,否则为1;而我们可以训练一个分类器,使得对于 = 0 的样本,ˆ 接近边界(0 或 1),具体取决于 ; 否则,对于 = 1,^ 远离边界。 使用阈值 ,我们从 ˆ 预测二元属性 和 。
接下来我们就要定义用于训练分类器的损失函数
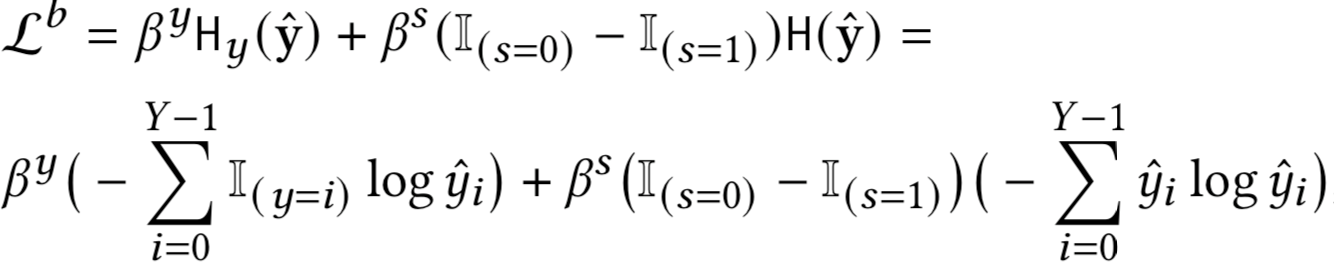
其中乘数和旨在控制诚实和好奇之间的权衡。 第一项是交叉熵,第二项是香农熵,旨在对于 = 0 的样本最小化 y^ 的熵,同时对于 = 1最大化 y 的熵。
这样训练之后,在推理阶段,当观察到y^,会计算其熵值,并使用阈值t来估计s-,如下所示
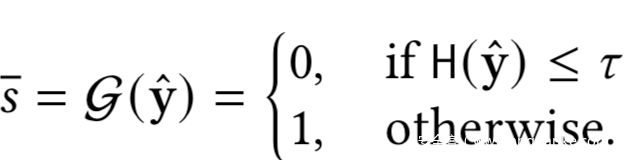
所以其实攻击者G就是一个简单的阈值函数,阈值则可以通过在训练期间的验证集进行优化得到
参数化攻击
当S>=2时,上一种攻击方式就不可行了,所以这里介绍第二种攻击方式,在此之前我们简单提一下信息瓶颈
之前我们提到了马尔科夫链

服务器希望找到一个分类器F*可以将用户的数据x映射到一个向量y^
同时使得y^尽可能地包含关于y和s的信息
这种F*可以被定义为下面数学优化公式的解
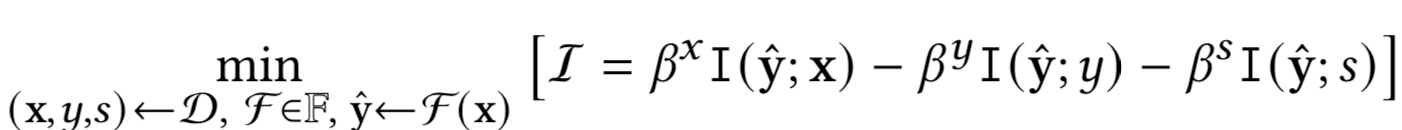
其中、和是拉格朗日乘数,它们允许我们沿着不同的可能局部最小值移动,并且都是非负实值
上面这条公式实际上是信息瓶颈公式的扩展,其中由 F * 产生的最优 y^ 是根据其与三个变量 x、 和 的关系来决定的。 通过改变 乘数,我们可以探索不同速率的压缩之间的权衡,即通过最小化 I(y^;x) 和我们旨在保留的信息量,即通过最大化 I(y^;) 和 I(y^;)。 特别是对于 DNN,压缩可能有助于分类器实现更好的泛化
现在我们来看看对于一个计算有界且只能访问原样本的服务器,应该怎么求解上式并创建最优的HBC分类器
我们有

对于固定的训练集而言,在优化过程中H(y)和H(s)是常量,而对于一个判别F来说,有
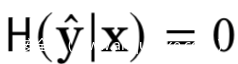
所以我们将上式简化如下
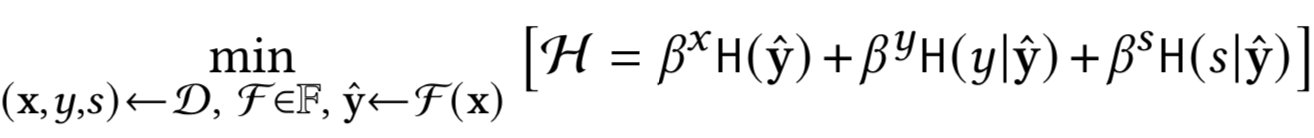
上式可以看做是一个优化问题,旨在最小化y^的熵,并将尽可能多的关于y和s的信息编码进去。因为优化的过程是寻求一个函数 F∗ 来产生一个低熵 y^ ,使得 y^ 只提供关于 和 的信息,而没有关于其他任何信息的信息。 乘数 和 指定 和 如何在 y^ 的熵中竞争剩余容量
现在,服务器需要训练一个已知的现成分类器。 在这里,我们对目标属性 使用交叉熵损失函数,并使用 SGD 训练分类器 F。 然而,除了这个交叉熵损失之外,我们还需要为属性寻找另一个损失函数。 因此,我们需要一种方法来为模拟这样的损失函数。
让 |y^ 表示给定 y^ 的真实但未知的 概率分布, |y^ 表示 |y^ 的近似值。 考虑到这两个分布 H |y^ ( |y^ ) 之间的交叉熵,已知有

这个不等式告诉我们,未知分布之间的交叉熵和它的任何估计,是H的上界,并且当|y\^=|y^ 时,等式成立。 因此,如果我们为 |y^ 找到一个有用的模型,那么最小化H( |y^ ) 的问题可以通过最小化 H |y^ ( |y^ ) 来解决。
我们可以下面的交叉熵来估计 H |yˆ ( |yˆ )
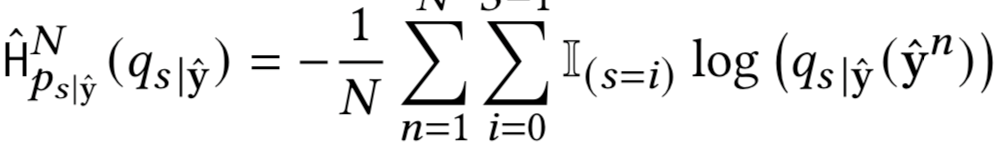
在为 |yˆ 初始化一个参数化模型以估计H( |yˆ )后,我们对下式进行优化
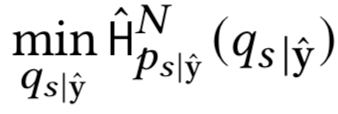
此时优化问题的变分近似可以写作
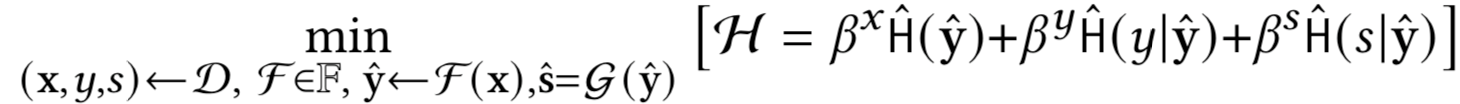
其中联合最小化是在参数化模型 F 和 G 上执行的。这里,H^(·) 和 H^(·|·) 表示分别在每批采样数据上计算的经验熵和条件熵。该方案的训练示意图如下所示
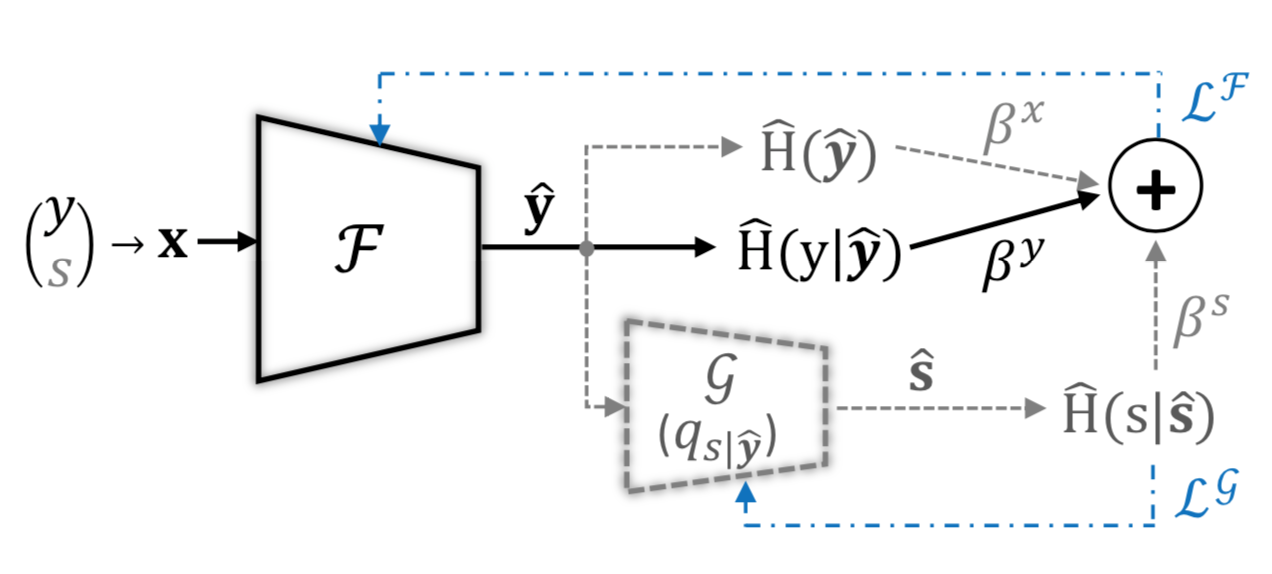
至此,两种攻击方案都介绍完毕。在正则化攻击里,我们只需要修改F的损失函数,在参数化攻击里,我们不仅要修改损失函数,还有利用额外的模型G来估计敏感属性。因此,F可以被看做在同时扮演两个角色,一个是诚实方,用于估计目标属性,一个是好奇的编码方,用于编码敏感属性;而G则是好奇的解码方,用于解码收到的输出并估计敏感属性。
实验分析及复现
分析
我们以UTKFace为例。我们假设性别Gender为目标属性y,种族Race为敏感属性s
实验得到的ROC曲线如下

上一行是标准分类器,下一行是通过正则化攻击得到的HBC分类器
在左上图中,标准分类器的 ROC 曲线下面积 (AUC) 为 0.97,而在左下图中,分类器是 HBC,但仍达到相当大的 0.94 AUC。而对于好奇方而言,右上图中的标准分类器没有提供有关 Race 的信息,它基本上与随机猜测一样。 但是,右下角的 HBC 分类器通过正则化攻击预测 Race 可以达到 0.89 AUC。
这表明正则化攻击确实可以实现HBC分类器及其攻击效果。
而当S>2时,我们进一步的实验结果如下所示,这里我们将性别、年龄或种族中的一个设置为,另一个设置为,并比较实现的和
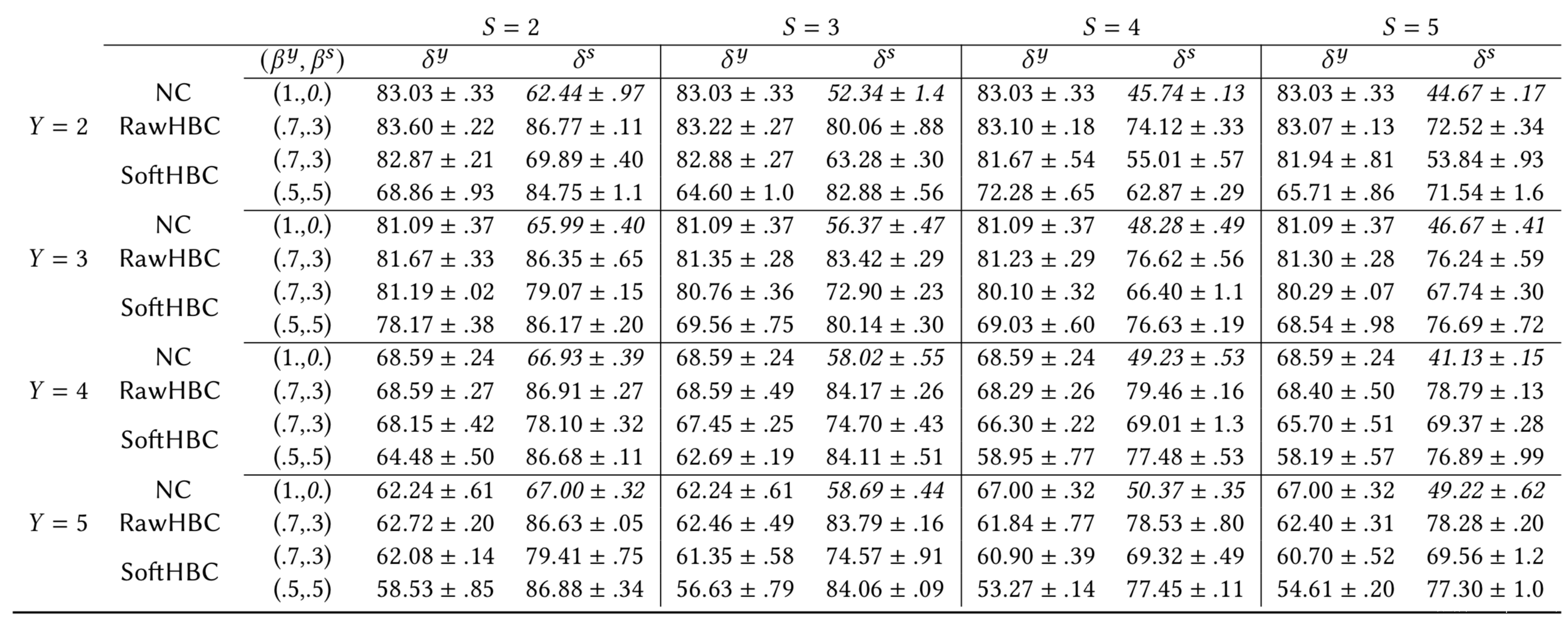
上表是参数化攻击的结果,其中目标属性是年龄,敏感属性是种族

上表是各类攻击的结果,其中目标属性是种族,敏感属性是性别
从表格中我们可以看到,对于所有 RawHBC 的情况,HBC 分类器的 非常接近 Std 中相应分类器的 。此外,我们看到在某些情况下,HBC 甚至有助于实现更好的泛化,从而获得更好的诚实度;这非常重要,因为 HBC 分类器可以看起来尽可能诚实。
当我们可以拿到原始输出时,攻击在所有任务中都非常成功,并且在许多情况下,我们可以达到与我们可以针对特定敏感属性训练 F 的情况相似的准确性。例如,在第一个表中,对于 = 3 和 > 2,我们可以达到大约 83% 的好奇来从针对年龄属性训练的分类器中推断种族属性。
在 SoftHBC 中,通过参数化攻击实现高好奇度更加困难,因为需要降低更多的诚实度。特别是对于具有 > 的任务,其中敏感属性比目标属性更精细。此外,虽然我们之前已经看到 SoftHBC 成功的正则化攻击,但正则化攻击不能应用于 > 2 的任务。此外,尽管 RawHBC 的好奇心比 SoftHBC 更高,但随着输出的大小变大,两者之间的差异会变小。
另外我们还可以观察到,当 ≤ 时,攻击非常成功,因为释放的输出容量更大。但是,当 > 时,攻击也是成功的。最有难度的情况是 = 2 并且我们只能访问软输出,因为在这些任务中我们只释放一个值(即 ^1 = 1 – ^2)。此外,我们在第二个表中看到,对于具有 = = 2 的 SoftHBC,正则化攻击比参数化攻击实现了更好的权衡。
复现
准备UTKFace的数据

数据集信息如下

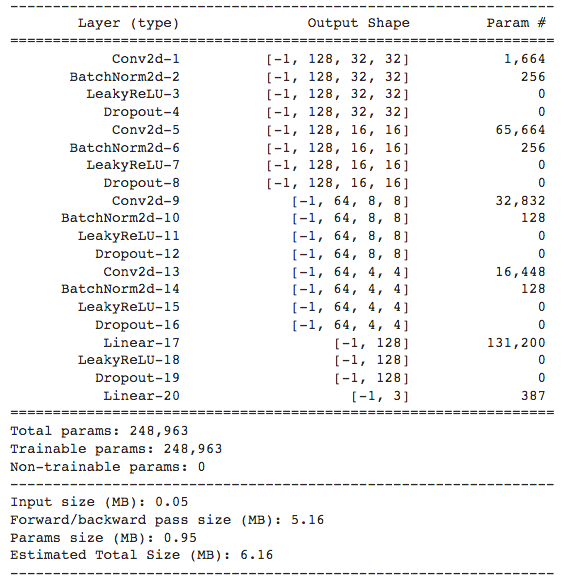
准备模型

打印出summary如下
我们来复现参数化攻击
参数化攻击的G的架构
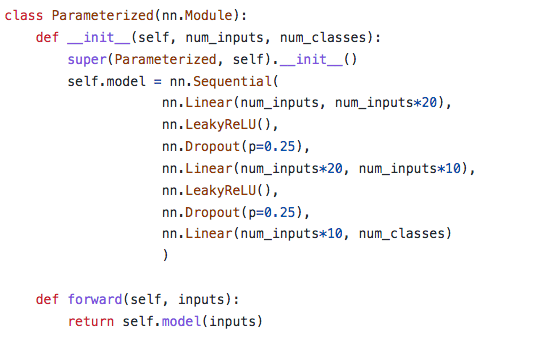
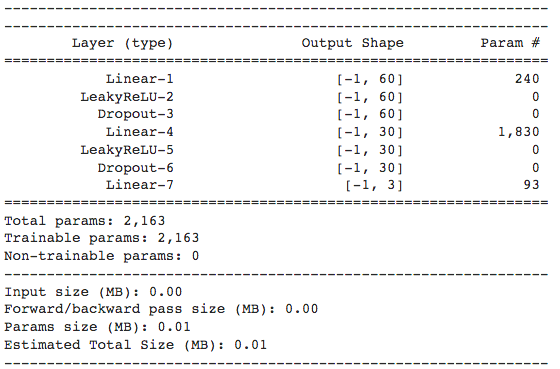
打印出summary如下
参数化攻击主体代码
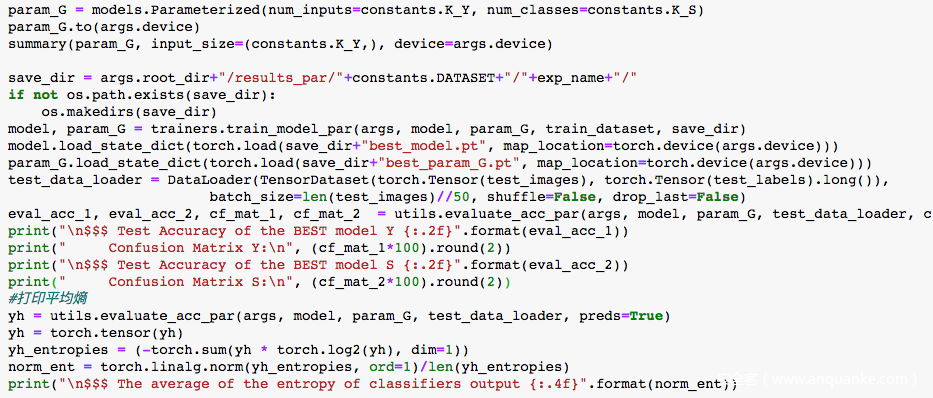
其中评估acc的代码如下

测试结果如下

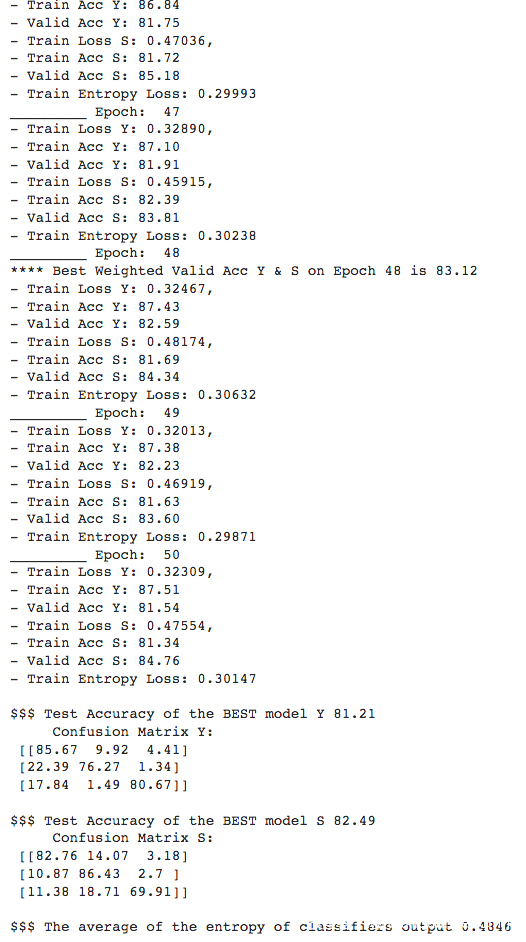
可以看到通过训练,模型推理目标属性y和敏感属性s的acc都一直在上升,说明HBC攻击确实有效,能够从模型的输出中成功推理出敏感属性。
参考
1.Honest-but-Curious Nets: Sensitive Attributes of Private Inputs Can Be Secretly Coded into the Classifiers’ Outputs
2.The InformationBottleneck Method
3.Stealing Machine Learning Models Via Prediction APIs
4.A Hybrid Approach to Privacy-Preserving Federated Learning







发表评论
您还未登录,请先登录。
登录