复杂的边信道攻击可泄露与 AI 聊天机器人对话的主题,即便流量受端到端加密保护。
这种名为 “Whisper Leak” 的漏洞使窃听者(如国家行为体、互联网服务提供商或 Wi-Fi 窥探者)能通过网络数据包大小和时间推断敏感提示词细节。该发现凸显出 AI 工具在日常生活中深度集成所带来的隐私风险——从医疗咨询到法律咨询均可能受影响。
微软研究人员在近期博客文章中详细介绍了该攻击,强调其对用户信任 AI 系统的潜在影响。通过分析大型语言模型(LLMs)的流式响应,攻击者无需解密数据即可对特定主题的提示词进行分类。
这在存在压迫性政权的地区尤为令人担忧,涉及抗议、选举或违禁内容的讨论可能导致用户被针对性监控。
Whisper Leak 攻击工具包
OpenAI、微软等公司的 AI 聊天机器人通过逐令牌(token)生成回复并流式输出以提供快速反馈。这种自回归过程结合 HTTPS 等协议的 TLS 加密,通常能保护内容安全。
然而,Whisper Leak 针对元数据发起攻击:数据包大小的变化(与令牌长度相关)和到达间隔时间暴露出特定主题的独特模式。
研究方法包括在加密流量上训练分类器。在概念验证中,研究人员聚焦“洗钱合法性”主题,生成 100 种提示词变体,并与 11,716 条无关的 Quora 问题对比。
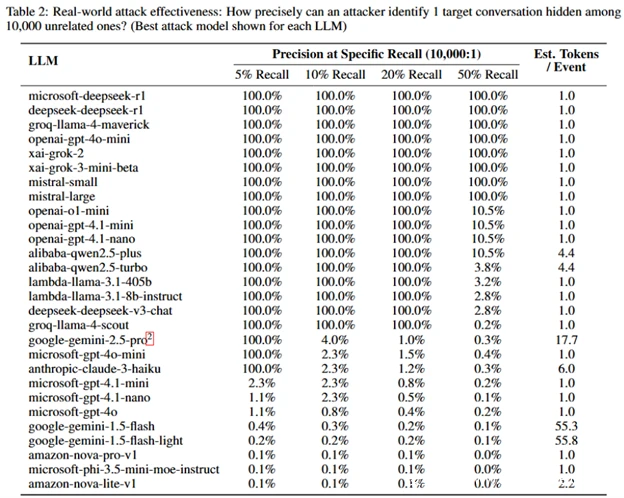
他们使用 tcpdump 等工具捕获数据,测试了 LightGBM、Bi-LSTM 和基于 BERT 的分类器。结果显示:许多模型在精确率-召回率曲线下面积(AUPRC)上达到 98% 以上的准确率,能从无关信息中区分目标主题。
在模拟真实场景中,监控 10,000 次对话的攻击者可标记敏感对话,实现 100% 精确率和 5-50% 召回率——意味着极少误报,且能可靠识别非法查询。
该攻击基于既往研究(如 Weiss 等人的令牌长度推断、Carlini 和 Nasr 的时间漏洞利用),但进一步扩展到主题分类。
缓解措施
微软已与 OpenAI、Mistral、xAI 及自家 Azure 平台等供应商合作部署修复方案。OpenAI 新增“混淆字段”,通过随机文本块掩盖令牌长度,大幅降低攻击可行性。
Mistral 引入“p 参数”实现类似随机化,Azure 也同步实施了这些变更。测试显示,这些更新将风险降至可忽略水平。
专家建议用户:避免在公共网络讨论敏感话题、使用 VPN、选择非流式输出模式,并优先使用已修复的服务提供商。GitHub 上的开源 Whisper Leak 仓库包含相关代码,供安全意识提升和进一步研究使用。
此事件凸显 AI 普及背景下强化隐私保护的必要性。尽管缓解措施已应对当前威胁,但不断演变的攻击手段要求行业保持持续警惕。







发表评论
您还未登录,请先登录。
登录