
大语言模型已成为各行业的核心工具,覆盖医疗健康到创意服务等多个领域,彻底革新了人类与人工智能的交互模式。
但这种快速的规模化应用,也暴露出该技术存在的重大安全漏洞。越狱攻击—— 一类专为绕过模型安全机制设计的复杂攻击手段,正对大语言模型的安全落地部署构成日益严峻的威胁。
这类攻击会操控模型生成有害、不道德或具有恶意的内容,引发的严重后果涵盖虚假信息传播、诈骗实施乃至恶意滥用等多个层面。
当前主流的防御方案,通常依赖内容过滤、监督式微调等静态防护机制。
然而面对日趋复杂的多轮越狱攻击策略,这些传统方法逐渐难以招架。在这类攻击中,攻击者会在多轮对话过程中逐步升级攻击手段,诱导模型突破安全限制。
现有防御体系缺乏应对不断演变的对抗性攻击所需的动态适配能力,导致系统极易被这类基于对话的复杂攻击方式所利用。这一防御短板凸显出行业的迫切需求:需要打造更具适应性与前瞻性的防御方案,以应对层出不穷的新型威胁。
上海交通大学、伊利诺伊大学厄巴纳 – 香槟分校及浙江大学的分析师与研究人员,提出了一款名为蜜罐陷阱(HoneyTrap)的防御框架,为该领域带来了突破性的解决方案。
这款框架采用了与传统方案截然不同的越狱防御思路,其核心是构建一个多智能体协同系统 —— 它不会简单地直接拦截攻击请求,而是通过策略性欺骗手段主动误导攻击者,从而达成防御目的。
蜜罐陷阱(HoneyTrap)的架构集成
蜜罐陷阱框架整合了四个各司其职的专业防御智能体,各组件协同运作形成完整防御链路:
- 威胁拦截器(Threat Interceptor):作为防御体系的第一道防线,它会策略性地延迟响应速度以拖慢攻击者节奏,同时返回模糊不清的应答内容,确保不会泄露任何可被利用的有效信息。
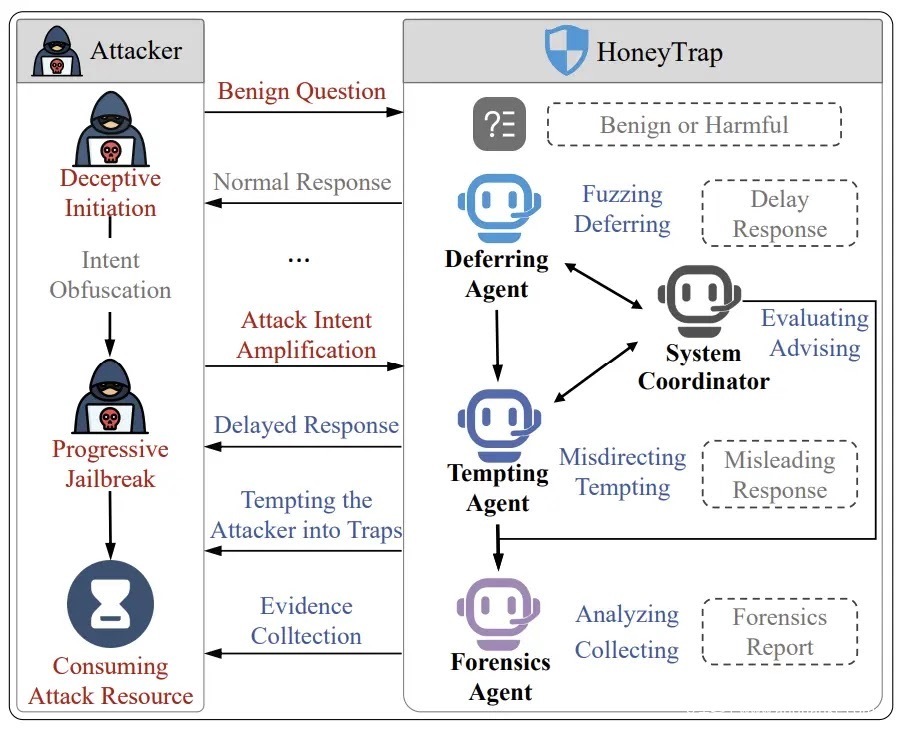
- 误导控制器(Misdirection Controller):生成表面看似有用的欺骗性回复,巧妙诱导攻击者产生 “攻击正在推进” 的错觉,却始终无法获取关键信息。
- 系统协调器(System Harmonizer):承担全局调度职能,基于对攻击进展的实时分析,动态调整防御强度,实现防御策略的灵活适配。
- 取证追踪器(Forensic Tracker):持续监控所有交互过程,捕捉攻击者的行为模式,识别新型攻击特征,进而优化迭代防御策略。
实验验证结果表明,该框架的防御效果十分显著。在 GPT-4、GPT-3.5-turbo、Gemini-1.5-pro 以及 LLaMa-3.1 四款主流大语言模型上的测试显示,与现有防御方案相比,蜜罐陷阱能将攻击成功率平均降低 68.77%。
尤为关键的是,这款框架能够大幅消耗攻击者的资源成本。
测试数据显示,其误导成功率提升了约 118%,同时攻击者的资源消耗增加了 149%。这些数据充分说明,蜜罐陷阱并非简单地拦截攻击,而是在不影响合法用户服务体验的前提下,策略性地消耗攻击者的资源。
该系统在正常对话场景下能够维持高质量的响应水准,在保障用户体验的同时,同步强化安全防御能力。
这一双重优势,让蜜罐陷阱成为一套务实且可落地的解决方案,能够帮助各类机构抵御不断演变的越狱攻击威胁。







发表评论
您还未登录,请先登录。
登录