投稿
投稿





一、前言
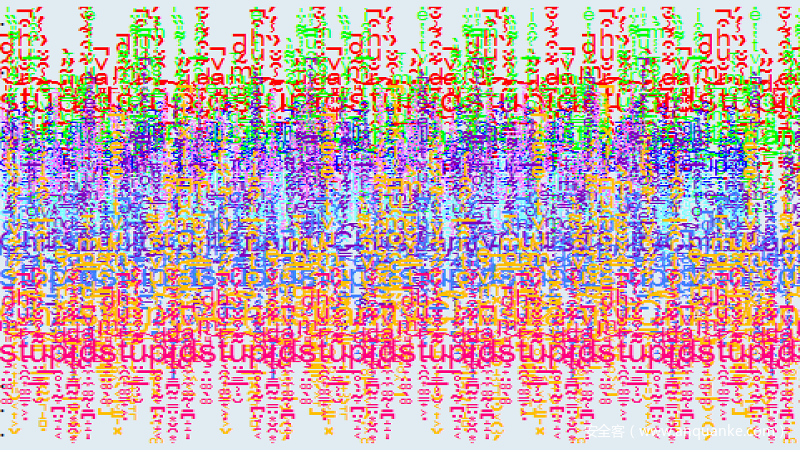
首先观察如下语句:
̀̀̀̀̀́́́́́̂̂̂̂̂̃̃̃̃̃̄̄̄̄̄̅̅̅̅̅̆̆̆̆̆̇̇̇̇̇̈̈̈̈̈̉̉̉̉̉̊̊̊̊̊ͅͅͅͅͅͅͅͅͅͅͅalert(̋̋̋̋̋̌̌̌̌̌̍̍̍̍̍̎̎̎̎̎̏̏̏̏̏ͅͅͅͅͅ1̐̐̐̐̐̑̑̑̑̑̒̒̒̒̒̓̓̓̓̓̔̔̔̔̔ͅͅͅͅͅ)̡̡̡̡̡̢̢̢̢̢̛̛̛̛̛̖̖̖̖̖̗̗̗̗̗̘̘̘̘̘̙̙̙̙̙̜̜̜̜̜̝̝̝̝̝̞̞̞̞̞̟̟̟̟̟̠̠̠̠̠̣̕̕̕̕̕̚̚̚̚̚ͅͅͅͅͅͅͅͅͅͅͅͅͅͅͅ
这是Edge浏览器上一条有效的JavaScript代码,如何实现这一点呢?
当Twitter将推文的字符个数限制从140增加到280时,当时我想试一下哪些unicode字符可以在这种限制条件下使用,这应该是非常有趣的一件事情。我发了一则推文,中间包含一些有趣的字符,可以导致Twitter出现渲染错误,这种字符就是所谓的Zalgo字符。以这件事情为契机,我开始思考如何自动识别这些字符。我们并不能使用DOM来检查某些字符的行为比较异常,需要使用屏幕截图来查看浏览器所看到的内容。刚开始我使用的是JavaScript以及canvas来截图,但得到的图片与浏览器中显示的实际图片并不匹配,因此我需要使用另一种方法,而Headless Chrome正是我苦苦寻找的解决方案。我使用的是puppeteer,这是一个NodeJS模块,我们可以借此控制Headless Chrome并截取屏幕。
二、生成字符
为了生成Zalgo文本,我们可以重复单个字符,也可以组合两个字符然后多次重复第二个字符。比如,如下码点(code point)可以在自我重复时产生不好的视觉体验,而实际上它们大多都是unicode组合字符:
834,1425,1427,1430,1434,1435,1442,1443,1444,1445,1446,1447,1450,1453,1557,1623,1626,3633,3636,3637,3638,3639,3640,3641,3642,3655,3656,3657,3658,3659,3660,3661,3662
比如,如下JavaScript代码可以使用上面的某个字符来生成非常难看的文本:
<script>document.write(String.fromCharCode(834).repeat(20))</script>
输出结果为: ͂͂͂͂͂͂͂͂͂͂͂͂͂͂͂͂͂͂͂͂
这里比较有趣的是,多个字符可以组合在一起并产生不同的效果。以311以及844字符为例,使用相同技术将这两个字符组合在一起,会得到不同的爬升效果:
<script> document.write(String.fromCharCode(311)+String.fromCharCode(844).repeat(20)) </script>
得到的效果为: ķ͌͌͌͌͌͌͌͌͌͌͌͌͌͌͌͌͌͌͌͌
三、构造Fuzzer
Fuzzer其实构造起来非常简单。我们需要一个能正确渲染字符的网页,加入一些CSS使页面足够宽,这样合法字符可以移动到屏幕右侧,我们就可以检查渲染页面左侧、顶部以及底部的区域,将fuzz这个div元素移到页面中央。
举个例子,fuzzer中渲染的字符“a”以及字符“b”如下图所示。为了帮助大家理解fuzzer的操作过程,我把fuzzer检查的区域标注出来,具体如下:

而字符ķ以及 ͂的屏幕图像如下所示(这两个字符的码点分别为311以及834)。在fuzzer看来这两个字符会产生较为有趣的效果,因为生成的文本位于上方区域。

<style>
.parent {
position: absolute;
height: 50%;
width: 50%;
top: 50%;
-webkit-transform: translateY(-50%);
-moz-transform: translateY(-50%);
-ms-transform: translateY(-50%);
-o-transform: translateY(-50%);
transform: translateY(-50%);
}
.fuzz {
height: 300px;
width:5000px;
position: relative;
left:50%;
top: 50%;
transform: translateY(-50%);
}
</style>
</head>
<body>
<div class="parent">
<div class="fuzz" id="test"></div>
</div>
<script>
var chars = location.search.slice(1).split(',');
if(chars.length > 1) {
document.getElementById('test').innerHTML = String.fromCharCode(chars[0])+String.fromCharCode(chars[1]).repeat(100);
} else {
document.getElementById('test').innerHTML = String.fromCharCode(chars[0]).repeat(100);
}
</script>
上述JavaScript代码会从查询字符串中读取1到2个字符编号,然后使用innerHTML以及String.fromCharCode输出这些字符。当然,这些代码会在客户端执行。
然后,我在NodeJS中用到了png以及puppeteer库。
const PNGReader = require('png.js');
const puppeteer = require('puppeteer');
接下来构造两个函数,检查某个像素是否是白色像素,是否位于我期待的区域中(即顶部、左侧以及底部)。
function isWhite(pixel) {
if(pixel[0] === 255 && pixel[1] === 255 && pixel[2] === 255) {
return true;
} else {
return false;
}
}
function isInRange(x,y) {
if(y <= 120) {
return true;
}
if(y >= 220) {
return true;
}
if(x <= 180) {
return true;
}
return false;
}
fuzzBrowser函数是一个异步函数,可以截取屏幕,使用png库读取png文件。该函数会将有趣的字符输出到控制台(console)以及chars.txt文本文件中。
async function fuzzBrowser(writeStream, page, chr1, chr2) {
if(typeof chr2 !== 'undefined') {
await page.goto('http://localhost/visualfuzzer/index.php?'+chr1+','+chr2);
} else {
await page.goto('http://localhost/visualfuzzer/index.php?'+chr1);
}
await page.screenshot({clip:{x:0,y:0,width: 400,height: 300}}).then((buf)=>{
var reader = new PNGReader(buf);
reader.parse(function(err, png){
if(err) throw err;
outerLoop:for(let x=0;x<400;x++) {
for(let y=0;y<300;y++) {
if(!isWhite(png.getPixel(x,y)) && isInRange(x,y)) {
if(typeof chr2 !== 'undefined') {
writeStream.write(chr1+','+chr2+'n');
console.log('Interesting chars: '+chr1+','+chr2);
} else {
writeStream.write(chr1+'n');
console.log('Interesting char: '+chr1);
}
break outerLoop;
}
}
}
});
});
}
然后构造一个异步匿名函数,循环处理目标字符并调用fuzzBrowser函数。在测试多个字符组合场景时,我排除了会导致副作用的单个字符。
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const singleChars = {834:1,1425:1,1427:1,1430:1,1434:1,1435:1,1442:1,1443:1,1444:1,1445:1,1446:1,1447:1,1450:1,1453:1,1557:1,1623:1,1626:1,3633:1,3636:1,3637:1,3638:1,3639:1,3640:1,3641:1,3642:1,3655:1,3656:1,3657:1,3658:1,3659:1,3660:1,3661:1,3662:1};
const fs = require('fs');
let writeStream = fs.createWriteStream('logs.txt', {flags: 'a'});
for(let i=768;i<=879;i++) {
for(let j=768;j<=879;j++) {
if(singleChars[i] || singleChars[j]) {
continue;
}
process.stdout.write("Fuzzing chars "+i+","+j+" r");
await fuzzBrowser(writeStream, page, i, j).catch(err=>{
console.log("Failed fuzzing browser:"+err);
});
}
}
await browser.close();
await writeStream.end();
})();
四、ZalgoScript
前不久我发现了Edge上存在一个有趣的bug,简单说来,就是Edge会错误地将某些字符当成空白符,因为某些unicode字符组合在一起就会出现这种行为。那么如果我们将这个bug与Zalgo结合在一起会出现什么情况?这样做我们就可以得到ZalgoScript!首先我生成了一份字符列表,Edge会将该列表中的所有字符都当成空白符(有很多这样的字符,大家可以访问Github了解完整列表)。我决定fuzz 768-879之间的字符(fuzzer代码默认情况下已经包含该范围),根据fuzzer的结果,837字符与768-879之间的字符组合在一起会得到非常难看的视觉效果。这个思路很棒,我可以遍历这个列表,将字符结合在一起,生成既是Zalgo文本又是有效的JavaScript的输出结果。
a= [];
for(i=768;i<=858;i++){
a.push(String.fromCharCode(837)+String.fromCharCode(i).repeat(5));
}
a[10]+='alert('
a[15]+='1';
a[20]+=')';
input.value=a.join('')
eval(a.join(''));
这也是我们如何生成本文开头提到的 ̀̀̀̀̀́́́́́̂̂̂̂̂̃̃̃̃̃̄̄̄̄̄̅̅̅̅̅̆̆̆̆̆̇̇̇̇̇̈̈̈̈̈̉̉̉̉̉̊̊̊̊̊ͅͅͅͅͅͅͅͅͅͅͅalert(̋̋̋̋̋̌̌̌̌̌̍̍̍̍̍̎̎̎̎̎̏̏̏̏̏ͅͅͅͅͅ1̐̐̐̐̐̑̑̑̑̑̒̒̒̒̒̓̓̓̓̓̔̔̔̔̔ͅͅͅͅͅ)̡̡̡̡̡̢̢̢̢̢̛̛̛̛̛̖̖̖̖̖̗̗̗̗̗̘̘̘̘̘̙̙̙̙̙̜̜̜̜̜̝̝̝̝̝̞̞̞̞̞̟̟̟̟̟̠̠̠̠̠̣̕̕̕̕̕̚̚̚̚̚ͅͅͅͅͅͅͅͅͅͅͅͅͅͅͅ语句的具体方法。
我已经将visualfuzzer的代码公布在Github上。
如果你喜欢这方面内容,你可能也会对非字母数字形式的JavaScript代码感兴趣。