

1. 前言
自2016年以来,我们一直在研究符号执行和二进制反混淆,以便:(1)测试和改进我们的二进制保护器(Epona) 。(2)改进我们的DSE(动态符号执行)框架( (Triton)。上周,我们在DIMVA 2018上发布了这项研究的一部分,重点是关于攻击虚拟化的软件保护,特别是当哈希函数被虚拟化以保护完整性检查、识别等。在这项研究中,我们依赖的是一个开源的保护器(Tigress) 并提供了攻击的脚本和结果以及Tigress challenge的一些解决方案。
论文中详细阐述了一切,但我们将在这篇博客中总结我们的方法的要点和结果。
2. 我们的方案
我们的方法依赖于关键的直觉,即虚拟化跟踪结合了来自源程序行为的指令和来自虚拟机处理的指令。如果我们能够区分这两个指令子集,我们能够避免来自虚拟机处理的指令,并且只保留源程序行为的一部分指令。为了做到这一点,我们需要识别虚拟机的输入,并且我们都要污染并标记这些输入。然后,我们执行由受污染的信息引导的动态符号执行,并将未被污染的所有内容具体化。这意味着我们具体化了与VM的输入无关的所有东西,因此,我们只保留了原始程序行为的一部分的指令——换句话说 ,我们避免了使用基于污染的具体化策略的虚拟机处理的一部分的指令。 在该步骤中,我们只能对一个路径进行虚拟化,因此,为了使整个程序行为去虚拟化,我们基于第一个符号执行来执行动态符号搜索,然后,我们构建一个基于符号搜索的符号表达式的路径树。 现在我们已经将整个程序行为作为符号表达式(没有虚拟机处理),我们将符号表示转换为LLVM-IR表示,然后在没有虚拟化保护的情况下重新编译一个新的二进制文件。
3. 实验
为了评估我们的方法,我们做了两个实验, 第一种设置为在受控的情况下,第二种设置在不受控的情况下即Tigress challenge ,然后我们定义了三个标准:
- 精度
- 准确:在语义上,代码是否与原始代码等价?
- 简洁:代码的大小与原始代码的大小相似吗?
- 效率(可量测性 ):RAM/Time 多少?
- 健壮性 : w.r.t.保护:具体的保护措施对我们的分析的影响比其他的更大吗?
3.1 受控制实验设置
在受控设置中,我们获得了20种哈希算法和46种不同的Tigress保护(它们都与虚拟化有关,比如不同类型的调度程序、操作数.),然后我们用不同的保护来编译这些哈希算法,从而给出了920个受保护样本的数据集。 目的是使用我们的方法(这里的脚本)去虚拟化这些样本, 并将结果(根据以前的标准)与原始版本进行比较。结果表明,对于大小接近原始样本的所有样本,我们在语义上都是正确的,甚至在某些情况下小于原始样本(见下表(b))。

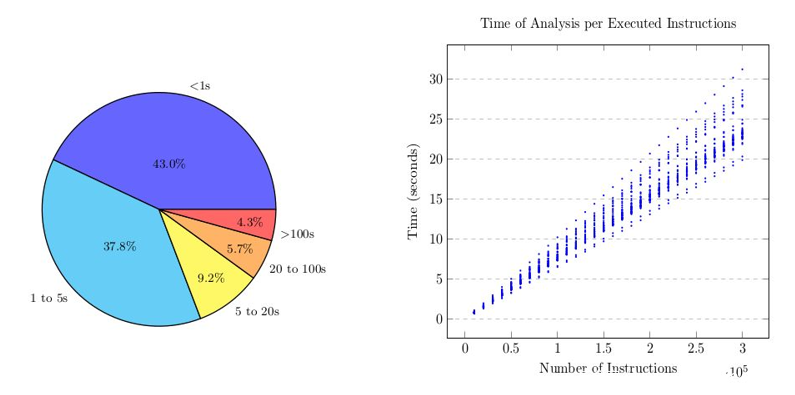
关于我们方法的效率,我们根据执行指令的数量进行线性分析。 我们在不到5秒的时间内成功地对大部分样品进行了虚拟化(参见下图), 最糟糕的样本耗时超过100秒,基本上是包含两级虚拟化的样本,涉及大约5000万条指令。
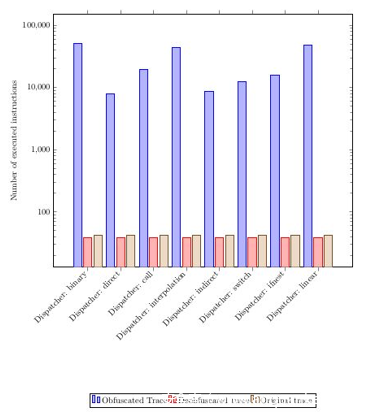
然后,关于我们的方法的健壮性,我们注意到我们的方法的简洁性并不依赖于应用的保护。例如,如果我们使用46种不同的保护(以及46种不同的受保护二进制文件)虚拟化MD5哈希算法,然后我们应用我们的方法来虚拟化这46种不同版本的受保护MD5算法,我们得到46个具有相同版本的虚拟化版本,它们都具有相同的简洁性。下图表示各种调度程序的同一程序的原始(棕色),受保护(蓝色)和虚拟化(红色)版本的指令数。我们可以很快看到受保护版本(蓝色)的指令数量根据调度程序的不同而有所不同,但经过我们的分析,无论调度程序使用了什么,我们都恢复了相同数量的指令(红色),这些指令接近于 原始版本的说明(棕色)。 可以在论文中查看更多详细信息和指标结果。
3.2 不受控的实验设置(Tigress challenges)
我们也进行了Tigress challenges这个挑战,挑战包括35个具有不同混淆程度的虚拟机(参见下表)。所有挑战都是一致的:有一个虚拟化的散列函数f(x)—>x’,其中x是一个整数,目标是尽可能接近恢复原始散列算法(所有算法都是自定义的)。根据他们的挑战状况,之前只解决了挑战0000,2016年10月28日,我们发布了一个挑战0000到0004的解决方案, 并在2017年SSTIC上做了演示(每个挑战包含5个二进制文件,产生25个虚拟机代码)。 我们不分析JIT二进制文件(0005和0006),因为我们的实现目前不支持JIT。
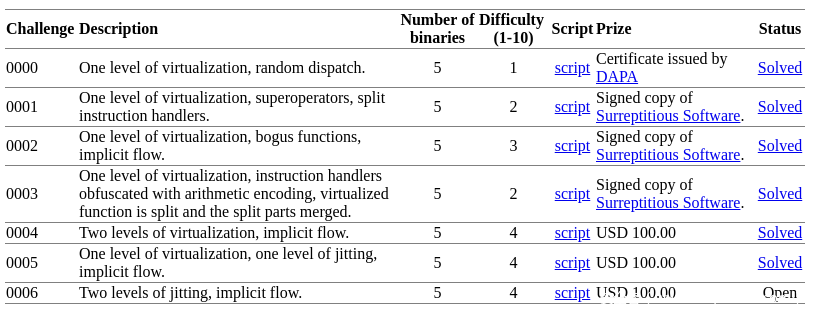
我们能够以正确、准确和有效的方式自动解决上述所有公开挑战,这表明我们在受控实验中观察到的良好结果扩展到了不受控制的情况。 已通过随机测试和手工检查对校正进行了检查。最困难的挑战系列是0004,有两个虚拟化级别。 例如,第0004-3号挑战包含1.4亿条指令,2小时内减少到320条(见下表)。

4. 限制和移植
我们的主要限制之一是,我们的方法是针对具有少量受污染路径的程序,这对于哈希算法来说不是问题,但对于其他虚拟化程序(如恶意软件)来说可能是一个很强的限制。然后,我们的DSE模型(即Triton)不支持用户依赖的内存访问。 然后,多线程、浮点算法和系统调用超出了符号推理的范围。 此外,由于我们的方法基于动态分析,因此展开循环和递归调用,这可能会大大增加非虚拟化代码的大小。
潜在的防御措施可能是攻击我们的方法,比如杀掉污点或者尽可能地传播它来影响我们的精确性。它也有可能杀死我们的动态符号搜索,添加一些依赖于污染数据(VM的输入)的哈希条件,如之前的博文中所述。 例如: if (hash(tainted_x) == 0x123456789) 这儿hash()是一种加密哈希算法。 如果我们不能搜索整个程序的行为,它将导致程序的不正确的非虚拟化版本。
另一个有趣的防御措施是保护虚拟机的字节码,而不是保护其组件。因此,如果虚拟机被破坏,攻击者就会得到混淆的伪代码。 例如:这个字节码可以被转换成不可读的 Mixed Boolean Arithmetic (MBA)表达式。
审核人:yiwang 编辑:边边







发表评论
您还未登录,请先登录。
登录