

本文所说的大数据安全,是指大规模多租户数据仓库,DLP、应用安全之类的传统范围不在此内。你可以理解为类似阿里的ODPS,AMAZON的redshift之类,也可以理解为Hadoop的生态技术栈集合,或者粗暴一点理解为超大规模数据库的集合。在这堆数据库上面,有数据开发人员,数据分析人员,运营人员甚至各种业务人员,在从数据里试图洞察业务。为了更好的观测业务,由此又衍生了机器算法平台、实时计算、离线计算、数据报表系统、数据模型、各类持久存储中间件等。
一、业务挑战
那么问题来了,这么大的数据集群,这么多数据表,这么多应用,这么多用户,如何保障安全?举例子增加一些体感吧:
1、 张三是上海地区的销售经理,按道理是应该只看上海的数据,这在数据表层面是一个行级控制的需求。但问题来了,他又需要知道北京地区的总体情况,以便做参照,这又需要一个北京的聚合权限。没过多久,张三由于业绩下滑,被调动到安徽区做经理了,之前的权限就要考虑回收,同时要给赋新的权限。这个过程中各种权限的细颗粒,你怎么做。
2、 公司要给总裁一个全业务的财务报表,报表中的部分指标,由20多个业务线生成,每个业务线又根据销售、促销、成本等进行了分类汇总。现在这个报表是公司高度机密,请你保护起来,但这张表的生产过程涉及到3000多个底层表和6000多人权限,另外还有8000多张血缘关系表。你怎么做。
3、 A事业部刚成立,为了展业,向成熟B事业部申请用户数据进行画像促销分析,B事业部同意后赋数据权限。A事业部拿到数据后,画像加工的不错,引起C事业部兴趣,因此向B申请了数据。但C事业部不慎出现泄漏,造成A事业部在市场上被对手定向打击,销售额下滑。这件事情,谁该负责,数据以后还要不要共享,你怎么做。
大概举了一些表面应用的例子,这些还不涉及到底层基础安全。而实际业务开展过程中,情况要比这个更复杂,当业务和人员规模到了BAT级,这件事情的挑战性也几何级数增加。
二、 关于方法论
在这几年的工作过程中,我一直试图去寻找一个方法论,能够从逻辑上对这些问题进行分类,然后有一个治理的思路。
1、数据安全生命周期理论
最“古典”的模型是数据安全生命周期,从采集到存储等等一系列环节的安全保障,然而我无法信服,因为它并不能解决我实际工作上的问题。首先数据安全生命周期在我看来是一个割裂的体系,将一个数据流动环节拆解为若干,然后进行不同保护,但很多逻辑又无法拆的很清楚。
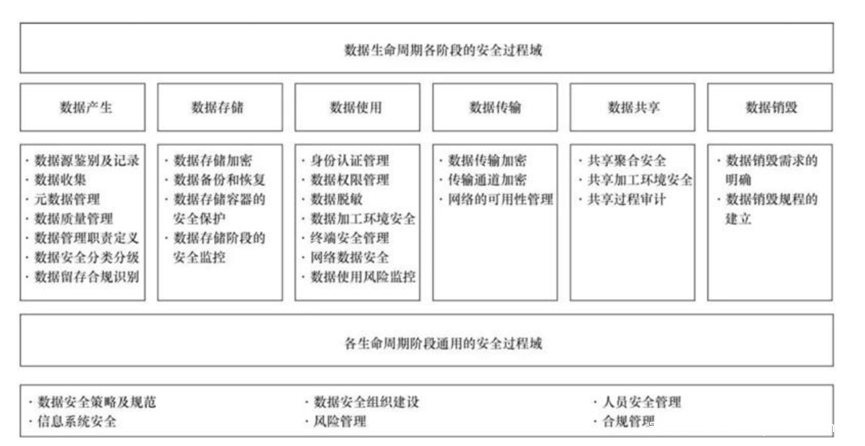
比如数据分级这件事,到底该在哪个环节,理论上说是在采集环节,但实际上我在数据处理的时候,数据产生了变化,级别也该不同了,所以我是不是要回到数据采集阶段去做分级?
我再换个问题,数据加密按照传统说法是在存储环节,但加密分为很多种,从磁盘加密到文件块加密到应用加密再到字段加密,字段加密在很多场景下并不影响使用分析啊,怎么就只能在存储做加密呢,要么就是我理解错了,要么就是这方法论有问题。
这些无法把逻辑拆清楚,实际上问题是:某个手段贯穿整个/部分周期,不是割裂在某个环节内。但这些其实都不是最关键的问题,最关键的是,别人问你,数据安全该怎么做,你说有6个周期4个保障5个级别,行了你走吧,我不想继续听你说了。没有一个简单清晰的东西,别人会觉得你说了半天,说的是个啥?听不懂。拿我前面举的财务报表例子,老板让你保证安全,你说我得先从采集开始,再到存储处理交换等一堆环节,听起来就很不友好,要搞很久的样子,要不老板再给你500年时间来完善一下?
好的方法论,一定是简单清晰,逻辑自洽的,超过3个别人都不大记得住。所以数据安全生命周期,安全团队内部自己说一说可以,放到外行那里去,很难听懂。
2、某咨询机构治理框架
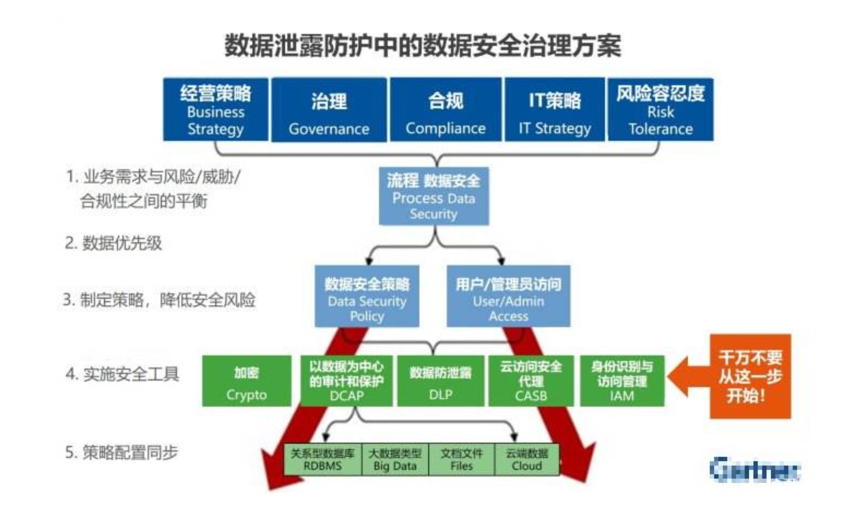
哪家就不说了,这张图表达了他的完整理念。看起来就是国外大咨询机构的范儿,先从策略再到治理、合规等,然后再有工具,最后再同步。有个笑话说,怎么把大象关到冰箱里?先打开门,把大象塞进去,然后再关上门,对不起我也不知道为什么要说这个笑话。
其实这张图,我只对安全工具这部分有点兴趣,不过这些工具之间有啥逻辑关系吗?如果只是罗列的话,我还能列出分类分级扫描器、ETL脱敏、查分隐私等一堆呢。其他的所谓风险平衡、制定策略这些都老生常谈了,都列出来大概显得更完整吧。
对了,上次参加一个安全会议,有个老师一针见血,咨询公司的报告嘛,靠这个收钱的。老师你这么说可不对啊,今天天气还不错啊,就是有点冷。
3、其他方法论
其他的也有一些,例如很早之前国内提出的“看不到,拿不走,用不了”,或者非数据安全的PDR模型,数据安全治理模型,就不展开说了,要么是场景偏单一,为了卖产品创造出来的理论。要么理想化,实际应用难以落地。要么说了一堆大而全,缺少分层归纳的逻辑,更像是个框架。
国外其他的也给大家看下,这个是某厂商的,是针对数仓的,将其分为边界、数据保护、访问控制、可视化,逻辑也不是很清楚,但把一些重要技术进行了归类,为什么这样分,因为人家产品线就这些啊。
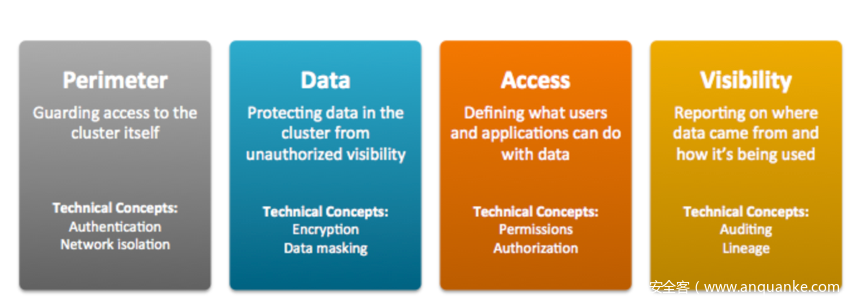
微软的提法是:认证、授权、网络隔离、数据保护和审计,也和上面厂家差不多。
再有一家,是类似于以前大4A的体系,当然也不完整,缺少了在应用环节流动的考虑。

4、业界大佬看法
回到初心,数据安全的目的是什么?我理解是安全促进数据流动,让数据产生更大价值。这一点大佬方兴思考的很清楚,我也认同,DT时代的核心是数据流动,不能只用资产的角度来进行数据保护,而是要从流动视角看数据安全,因此方兴提出的概念是下图这样。从流动视角保护数据安全我是深以为然的,上层是治理,也可以理解为策略。下面是识别、控制,但到了基础信息层又让我困惑了,逻辑上来说,基础信息和识别控制不是一个层次上的概念。
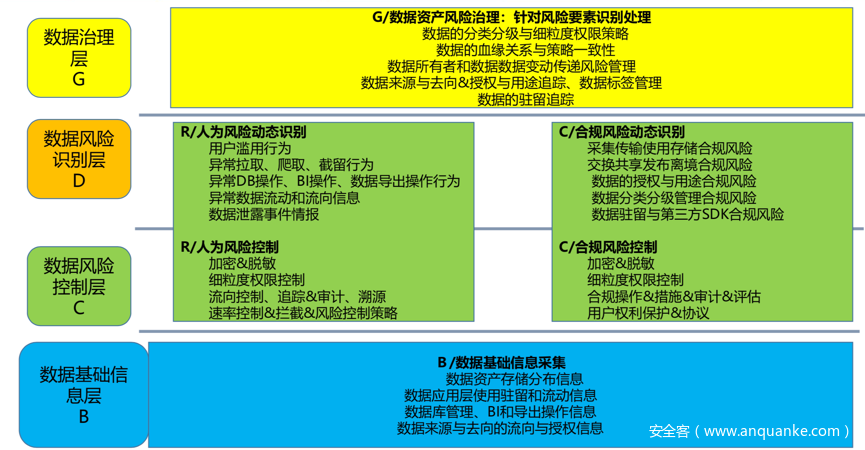
虽然我不完全认,但我还是要捧一句,这大概是我看到唯一的,用数据流动的概念来考虑安全问题的思想。那你说数据安全生命周期难道不是数据流动思想吗,他也是从采集到后面各环节,也是跟着流动在考虑安全啊。这里的区别在于流动风险和环节风险是有区别的,单一环节做了数据分级,到后面应用数据级别会变化的,假设1000个用户手机号,在采集环节是敏感个人信息,但是在后面ETL加工后,只是变成了一个400活跃用户,600不活跃用户的统计,那这个敏感级别是不是产生变化了?对应的保护是不是要降级?又或者你对这个手机字段做了加密,但其他字段信息,再和另外的数据关联时,能够还原出来对应手机号,这个风险是不是要统一考虑?
三、我自己的看法
大家说了,你说这个不好那个也不好,要不你给个好的?带着这个问题,我看了国外很多文章、实践、规范,连厂商吹牛的白皮书也看了。大体上对这个问题的回答,我只能回答,业界没有一个让我完全信服的,当然这是有原因的:本身大数据领域刚兴起没几年,更早之前的Hadoop甚至完全都不考虑安全的问题,也就这两年开始增加了一些基础安全特性。前几天阿里达摩院对2019十大科技趋势预测还提到,数据安全技术加速涌现。Google也在量子加密、同态加密上暗暗下功夫,Apple在实践差分隐私。这些都说明,数据安全本身处在变革前夜,在天没亮之前,让人知道这件事究竟怎么做,方法论是什么,是困难的,方法论一定是在多次实践中总结出来的。
我自己看数据安全,是从识别、保护、审计三个角度归类,当然你说上面加个数据治理或者统一集中管理的帽子也可以。但我说的不一定对,只代表我自己的思考。于是形成下面这样:
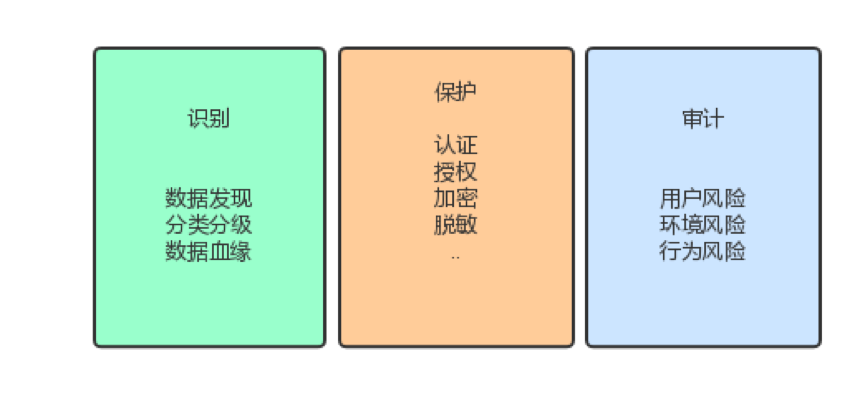
逻辑上是先识别出要保护的数据,然后对应保护措施,最后是基于风险的审计。识别和审计过程,对用户是透明无感知的,不打扰。保护环节则是一些基础认证+数据保护,这样在高密数据基础保护的前提下,实现了轻打扰,减少数据流动环节中的障碍。但这对审计环节要求很高,就是你能不能从审计这里发现问题,形成震慑,达到“莫伸手,伸手必被捉”,这个环节保障不了,就只能从管控手段加强。
之前和一个Facebook的同学聊,他们的数据安全怎么做的,实际上他们也在工作中没有遇到太多数据使用上的障碍,但一旦被发现,又解释不清,结果就是立刻打包走人。这也是形成我现在整体思路的一个输入。
另外一个输入是,公司大了会有很多不同的业务单元,这些业务单元之间会打着“安全”的名义,在数据流动上形成部门墙,因为不安全,所以不能给你数据。数据流动的好不好,能否产生价值,这背后有很多因素,例如你要的数据我要投入人力对接需求,加工,还要对数据质量负责,这对我毫无产出,但我用“安全”摆到台面上说。所以这种大公司情境下,如果继续在管控手段上加码,则进一步阻塞,做得越重,数据流动越有障碍。理想的情况是,数据安全有一些低打扰的数据共享方法,例如“可用不可见”这种,只不过现在还没有合适的方法大规模使用,所以我说现在处在前夜。







发表评论
您还未登录,请先登录。
登录