

一、识别
基本概念上的分类分级,数据密级这些策略我就不谈了,假设大家都懂,不懂随便找点资料也能看明白。我们说一些技术工具上的事情,因为这些才是支撑上层策略体系的手段,没有技术只能靠人肉,对于大公司来说不现实。
1、发现
数据安全的第一步是数据发现,没有这个基础,后面所有的策略都会陷入数据的太平洋。数据发现和识别一路走到今天,大体上有这么几种:
人肉:人工梳理,适用于小数据场景。我以前对一切人肉方法都嗤之以鼻,后来在群里被大佬教育,不看场景说方案都是耍流氓,例如有个药厂,核心数据就是配方,就那几个产品,完全可以通过人肉来做,说的对。另外在某些阶段,人肉也有意义,比如之前压根没数据安全,历史存量是不是要梳理一波。但对大型企业,这个方法就有问题了,某运营商之前起了个大项目,做全集团的数据梳理和分级,结果如何大概也只能自己知道。数据是动态的,人肉运动搞得了一时而已。一个大型企业,每天产生的数据至少几十万起,你要让每个数据生产者正确的理解并标记密级是不现实的。
静态梳理:所谓静态,主要是在持久化存储上扫描识别,例如关系型DB、数仓ODS、终端、文件存储等。
动态识别:在流量、接口等各类行为上识别。
当然识别完了以后,还要有个可视化,知道敏感数据的所在位置和流向,观察是否符合预期。
2、分类分级
在哪里识别这件事不难,难在识别的对不对,也就是误报率。技术上结构化数据的正则匹配是个基础姿势,无论是AWS、Google还是阿里云的数据保护伞,基本上都以此为主+人工,在云上这些方法都是适用的,因为按照责任模型,你定义错了是你的问题,和云无关,云厂商又不要投入人力来帮你分类分级,给你个工具你自己用去吧,但甲方就走不通了。
所以目前延伸出很多技术,大体有正则、语义、指纹、统计、情景、机器学习等方法。方法各有优缺点,不同场景有不同的适用方法,不存在完美的解决方案。
3、数据血缘
数据血缘关系最初是用来判断上游血缘链路的,例如一个指标的生成出了问题,要根据血缘链路追溯上游,找到问题所在。又或者上游表发生变化时,需要评估对下游影响,需要根据根据下游血缘链路确定哪些下游任务受到影响。
血缘有表血缘,也有行级、列级血缘,这方面在大数据使用中都有一些对用的技术和实践,但在安全上并不完全能等同。一张表在经过若干次生产后,其敏感级别会产生变化,例如原来是一张用户订单明细,属于高敏感,但经过加工后的聚合数据只是一个特征,这在安全上是降级的。如果严格按照血缘关系来看,这也是属于高敏感,但这样传递下去,下游任何表都是高敏感,数据就没法再分析了。因此,数据需要血缘剪枝,根据一些规则,去除一些无需关注的下游。有些公司在这方面采用比较粗暴的方法,原始表什么敏感级别,血缘就是什么敏感级别,我认为这是不妥的。
本质上血缘是一个语意解析的事情,包括逻辑血缘(列),谓语血缘(行)。逻辑上又分准确血缘,模糊血缘,模糊是指不明确的计算逻辑推测出的血缘,比如用户自定义UDTF,transform脚本(所有输入影响所有输出)得到的血缘,这里还有更多的算子、多对一、多对多、函数、limit等就不再多说。还有一部分需要关心的是,由于历史上是先有大数据系统,再有安全,所以整个大数据系统上有各种开源组件组成,所以血缘关系要能够同时支持hive、mysql、spark、kylin、presto等组件,否则血缘断裂,审计跟踪不下去。
二、保护
保护上目前流行的做法无外乎认证、授权、加密、脱敏等,常规的内容我不再重复科普,说一些实战中要注意的问题。
1、认证
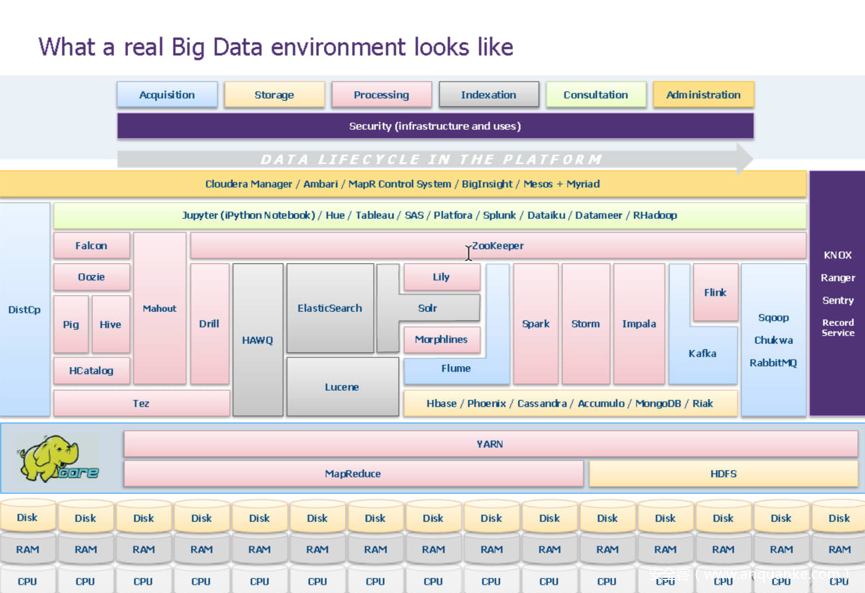
一般认证与kerberos,AD之类的结合看起来是常规动作,但还是刚才我提到的问题,先有大数据系统再有安全,所以认证层面要做到各个组件全打通。系统历史越久,轮子造的越多,这个债务越重。离线上有hive、spark、presto等,同时还有各类离线客户端,也包括关系型数据库mysql等。实时上有Kafka、storm、flink,各类sdk等。也就是说,如果你是新建系统,最好是把这些进行统一认证统一授权,不然将来做权限迁移的时候,又要考虑历史生产,又要考虑同步,做起来就很难受了。当然现在日子好过多了,有Sentry这样帮你做统一管理的工具。找了张厂商的图,找一下感觉:

一看到这图,对不熟悉的人来说会懵,没办法,大数据架构就是看起来会比较复杂。我稍微解释下:
外部数据流通过Flume和Kafka的机制进行身份验证,使用Sqoop拉取来自存量数据。BI使用Hue等接口和群集交互,或者用Impala提交作业。而这里所有组件都需要有统一认证。需要注意的是,这只是一个厂商,而在大规模实际生产中,组件情况比这个多的多。其中也用到了Sentry和HDFS访问控制列表来执行授权。
当然更真实的可能是下面这样,请你考虑对以下所有组件做统一验证和授权。
2、授权
开源授权体系里,主要是Sentry和Ranger两个项目,Cloudera用的是Sentry,是一种RBAC机制,华为的FusionInsight也是类似机制。先创建角色,将每个组件权限授予角色,在用户中添加角色。
Ranger是 PBAC,基于策略管理,Hortonworks用的Range。每个组件添加服务Service,然后添加自定义策略,再添加用户访问权限。
和统一验证一样,问题也是由于组件的多样性、历史存量问题,导致统一授权需要高速上一边开车一边换轮子。由于集群的每一个组件都有自己的授权模式,所以会导致整个复杂性增加,增加了很多漏洞。有问题的地方就有机会,所以一些厂商和开源组织在做统一验证和授权。
授权还有一个需要考虑的点,我前面举到例子,上海大区应该只看到上海区的数据,这就是行级权限的问题,在实际生产中有很多这种场景,也需考虑。
3、加密
加密按照架构有多种,从磁盘加密到块加密到文件加密。HDFS可以加密写入磁盘的所有数据,但这只是一个粗粒度,能够防止磁盘被盗或者被人copy,这个保护级别是全有或全无的方法,在企业内部应用中,磁盘被盗这种事情的几率不大,相对于应用级,这个保护的优先级也不高。在云中,由于信任模型的关系,是个必选。
应用级的细粒度加密是针对真正实际数据的保护,通过实际更改数据的值,即使数据被未授权读取,数据也能受到保护,比如可以对手机号码进行加密。因此在我看来,企业内的使用,应用字段级的加密比底层加密重要。
加密还有一个最大的挑战,就是线上系统和离线系统的不同加密方式。我们都知道线上DB需要做加密,通常是可逆的AES算法,但在数据进入离线后,由于DB和数仓完全两种不同的身份,DB的加密是面向服务的,数仓的加密是面向用户和生产组的,两者无法统一。这种问题有几个解决方式:
一是不解密,线上DB加密后,进到数仓不解密,只允许使用密文。这个方法会带来不同业务之间难以join,因为线上不同业务的密钥不同。
二是数仓作为一个服务统一调用解密服务,在DB加密,在数仓边界解密。我了解到华为是这种做法,但华为的数据体量相对BAT比较小(消息渠道未必可靠,仅供参考),而这个方法是在数据同步主链路上增加解密成本,当加密较为复杂情况时候,实时性和准确性很难保证,你要知道即使没有加解密,同步数据都有数据漂移,更何况还有加解密。加密复杂是什么意思呢,DB有些加密方法是字段级加密,每个字段一个密钥,这样解数据的时候,要有开发指定,要去调用密钥,所以风险比较大。
三是DB自行负责在数仓边界解密,数仓在内部用自己的方法再做加密。相比上面多了一个数仓加密的动作。至于amazon和Google,我没看到他们涉及数仓应用层加密。
四是采用token化+FPE方法,与加密有区别,token 化是指把数据同格式替换,例如手机号13911118888会被替换成139abcde888,保留了部分可读性和唯一性,这样在数仓内无需解密,即可进行数据匹配。当某些特殊情况下需要解密,由专门的服务提供脱离数仓的解密。而且我认为,对于手机号、银行卡等的解密需求,都是伪需求,没有什么情景是“真正”需要明文解密的。这种方法要求在全公司统一强制token化,安全部门必须足够强势,历史要清白,不然从以前的加密切换为token,涉及到双写、刷下游,很伤安全部人品。
4、共享
共享才是数据流动的核心,试想我前面提到的问题,在双方互不信任的前提下,如何做到数据共享流动创造价值?但目前说实话,可操作的方法不多,大概有几种。
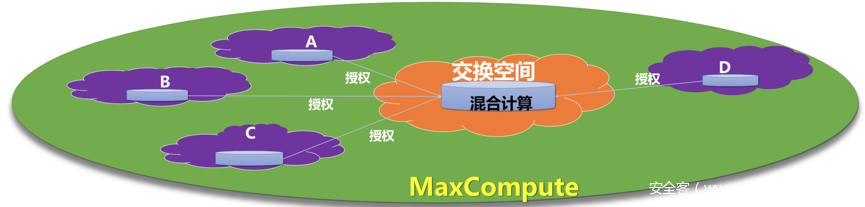
一是堡垒机形式,这方面阿里七星阵,或者有些公司的阳光屋安全屋都是这个方法,由于堡垒机限制了数据落地,加上安全META写不出去,因此形成了一个数仓内的安全交换仓。但这种方法也很显然存在问题,方法比较重,在大规模企业数据交换的时候,堡垒机、虚拟机的易用性会形成极大瓶颈,据我所知阿里七星阵当年也很难推广使用的下去,不知道现在的七星阵是不是有了什么变化,不过目前我看到阿里云上有一个说法:数据不搬家,可用不可见,意思是在交换空间计算后,需要经过授权才能搬走,这在云上是可行的。
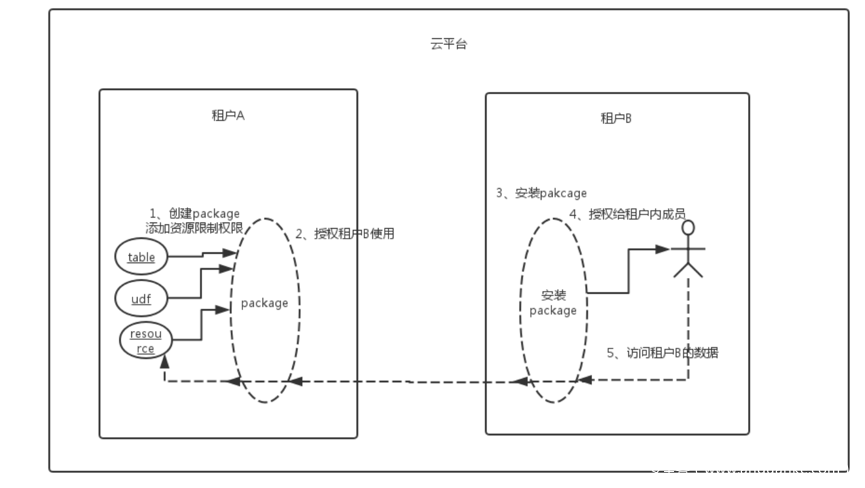
二是细粒度授权,我在阿里云博客上看到的方法,其分为package和Trusted两种模式,package如下图,数据需方需要获得package的权限、package是否可以安装、package内资源的访问限制三层校验。我没有实际操作过,问题是如防止租户B把数据写出去到其他地方?潜在的问题是,虽然我获得了供方授权,但并不意味着这个数据我可以随便拿到其他地方用。Trusted模式就不展开说了,见https://yq.aliyun.com/articles/61530?spm=a2c4e.11153940.blogcont78108.287.157733b6hpvMGo。
三是可用不可见,这个提法也是阿里提出来的(阿里还是厉害啊),我找不到原文了,但大概意思是说,数据是经过脱敏的,虽然你可以查询可以计算,但并不能获得明文,因此可用,但不可见。这种对部分场景是可用的,比如涉及到个人身份的敏感数据,但如果是复杂一些的场景,例如订单金额、地理位置的模型计算,这种方法就行不通了。
四是一些新方法,例如同态加密,只不过在工程实现上还有很大差距,存储也会极度膨胀,现阶段还难以扛起重任。
三、审计
数仓也是数据库的一种,市面上有很多数据库审计产品,但数据库审计的产品用在大数据上,恕我直言,都是垃圾,我觉得厂商应该把自己的审计产品线向大数据延伸了,老在数据库那点空间纠缠有啥意思。
作为数据最集中的数仓,一旦泄漏,情况最危险,而这种泄漏侦测的难度远大于传统审计方法,数仓里的sql语句是极为复杂的,要想从语句和代码里提炼出风险,那解析能力得有多强,话说解析能力这么强了,还干啥安全啊真是,生产场景更需要。
但并不是没有方法,我们换个名词,就不一样了,UEBA、态势感知,各位觉得如何,明显高大上了吧。借用BeyondCorp的理论,风险从用户、环境、行为的角度来去看,这样比从sql里的大海捞针,明显有效果。实际上这里的风险发现,很多手法上和风控是一脉相承的,只不过一个是面向黑产,一个是面向租户。
用户风险,是指那些可能高危的用户群,例如BD,HR,财务等,BD为啥是高风险呢,你猜啊。在一个规模公司里,如果你的数仓审计,发现不到BD干的那些事情,我认为就是不及格。用户风险还包括关系圈,与黑产、与竞对、与物流、资金流、信息流的关系,都可以代表某种程度的风险,甚至直接指向泄漏。
环境风险也好理解,设备、网络、指纹等,所以要在审计上关联出这些丰富字段来辅助报警,我举个例子,同一设备两个不同IDE用户,7个不同大区的BD聚集在竞对LBS等等,都是可以从环境延伸出来的规则。这方面多和风控同学学习。
行为风险,则是操作上的各种风险了,这里的难点其实在于日志打点,什么操作是高危的,就要有打点,高危操作后续的关联动作,可以延伸出规则。更大一些,则和全局日志关联,结合权限、资产,能够得出操作风险。
用户、环境、行为的结合,能够得出最终结论。换句话说,能不能审的出来问题,主要看你拿了多少有价值数据,其次才是规则模型。再往后再能谈到覆盖率、准确率、召回率这些指标。
我面试过很多人,问到他们审计的情况,大概都是一年发现个一两例这种级别,嗯,约等于零。你要知道在一个大型企业里,跃跃欲试并且屡屡得手的情况,其实是很多的,只是你看不见而已。
关于审计这部分比较敏感,也不再多说,给大家提供一些思路而已。
六、总结
前面说了很多,我把要点总结一下,以下只针对大规模企业,希望对大家有所帮助:
1、 大数据安全目前没有好的方法论,都是摸索前行。
2、 数据分类分级很重要,但前提是非结构化自动识别能力达到可用状态。
3、 统一验证和授权,越早做越好,难点在于半道上的安全。
4、 数据加密的难点在于线上db和离线的统一。
5、 数据共享技术亟待突破。
6、 审计要用新思维。
7、 数据安全即是当前热点,也是技术侧即将爆发的前夜。







发表评论
您还未登录,请先登录。
登录