

前言
完整性主要体现在模型的学习和预测过程完整不受干扰,输出结果符合模型的正常表现上。这是研究人员能相信AI模型的输出结果的根本,也是AI模型最容易受到攻击的地方。
针对AI模型完整性发起的攻击通常称为“对抗攻击”。 对抗攻击通常分为两类,一类是从模型入手的逃逸攻击,一类是从数据入手的数据中毒攻击。

在本文我们首先对逃逸攻击进行介绍。
1 逃逸攻击(Evasion Attacks)
逃逸攻击(Evasion Attacks)是指攻击者在不改变目标机器学习系统的情况下,通过构造特定输入样本以完成欺骗目标系统的攻击。

如上图所示[1],攻击者可以为下面这张熊猫图片增加少量干扰,让google的图片识别系统将其判断为长臂猿。
这其中的根本原因,在于模型没有学到完美的判别规则。虽然图片识别系统一直试图在计算机上模仿人类视觉功能,但由于人类视觉机理过于复杂,两个系统在判别物体时依赖的规则存在一定差异。比如说我们可能是通过熊猫的黑眼圈,黑耳朵,黑手臂还有熊脸判断出它是一个熊猫,但图片识别系统可能只是根据它躺在树枝上的这个动作,就将其判断为了长臂猿。因此完美的判别规则和模型实际学到的判别规则之间的差距,就给了攻击者逃脱模型检测的可趁之机。
试想,如果模型真的和人所使用的判别规则一模一样,比如一样是通过黑眼圈,黑耳朵,黑手臂还有熊脸判断出它是一个熊猫,那么这个模型就不存在被逃逸攻击的可能性了。因为一旦模型判断失败,那么人类同样会判断失败。
1.1 逃逸攻击的应用场景
逃逸攻击目前已经受到了广泛的关注,并被应用到了大量场景上,如攻击自动驾驶汽车、物联网设备、语音识别系统等,可以说“哪里有AI,哪里就有逃逸攻击”。下面是三个极具代表性的例子。
让自动驾驶汽车错误识别路边标示[2]

在原停止标志图像(左边)中,停止标志可以被成功地检测到。在中间图像,在整个图像中添加了小的干扰,停止标志不能被检测到。在最后一个图像中,在停止标志的符号区域添加小的干扰,而不是在整个图像,停止标志被检测成了一个花瓶。
让人脸识别系统错误识别人脸[3]

来自CMU的一篇论文,通过给人们佩戴专门设计过的眼镜架,便可以骗过最先进的面部识别软件。一副眼镜,不单可以让佩戴者消失在人工智能识别系统之中,而且还能让AI把佩戴者误以为是别人。考虑到人脸识别系统现如今应用范围之广,一旦该手段被恶意势力所利用,后果必然不堪设想。
攻击语音识别系统[4]
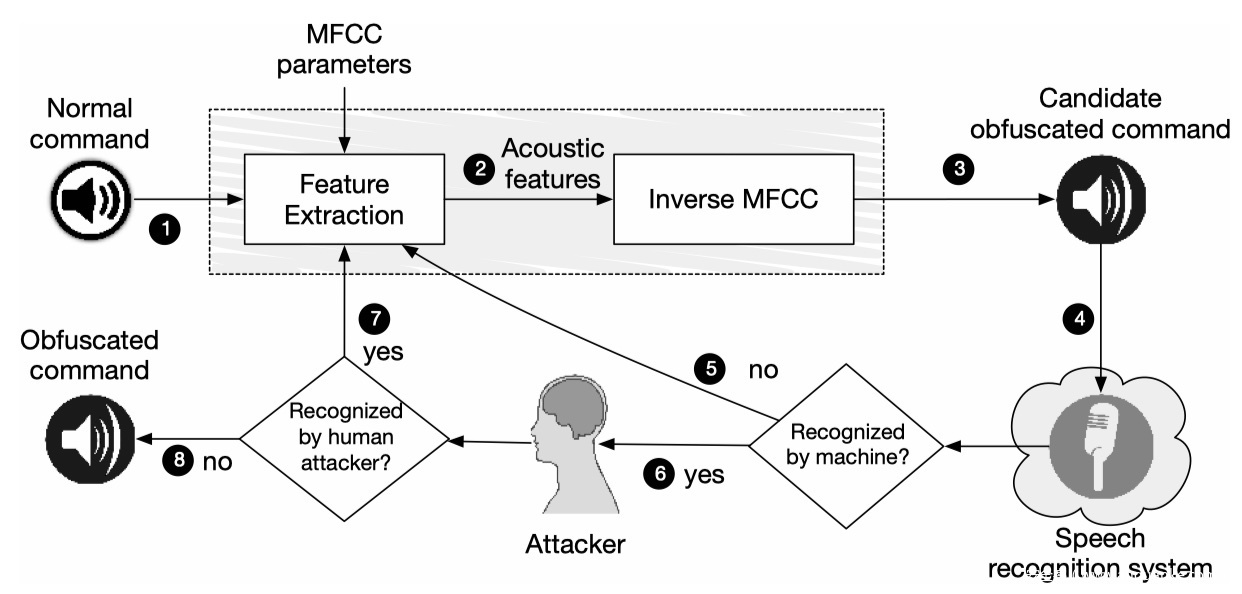
从正常命令倒推产生混淆的音频命令(如一段人类无法辨认的噪音),从而在三星Galaxy S4以及iPhone 6上面被正确识别为相对应的语音命令,变为让手机切换飞行模式、拨打911等。
1.2 逃逸攻击的攻击模式
大致了解了逃逸攻击的攻击场景之后,让我们来更深入地学习一下逃逸攻击吧。
逃逸攻击有多种分类方式,最常见的分类方式主要有以下两种。
-
根据攻击者是否了解模型——
-
白盒攻击:攻击者能够获知机器学习所使用的算法,以及算法所使用的参数。攻击者在产生对抗性攻击数据的过程中能够与机器学习的系统有所交互。
-
黑盒攻击:攻击者并不知道机器学习所使用的算法和参数,但攻击者仍能与机器学习的系统有所交互,比如可以通过传入任意输入观察输出,判断输出。
-
-
根据是否有攻击目标——
-
无目标攻击(untargeted attack):对于一张图片,生成一个对抗样本,使得标注系统在其上的标注与原标注无关。换而言之,只要攻击成功就好,对抗样本的最终属于哪一类不做限制。
-
有目标攻击(targeted attack): 对于一张图片和一个目标标注句子,生成一个对抗样本,使得标注系统在其上的标注与目标标注完全一致。换而言之,不仅要求攻击成功,还要求生成的对抗样本属于特定的类。
-
比如之前的熊猫例子,如果我只需要模型无法识别出这是一只熊猫,系统把它识别成猩猩兔子都可以,就叫做无目标攻击。如果我不仅需要系统将其识别为一只熊猫,还需要系统将它识别为我指定的一个东西,比如说我想让他将熊猫识别为长臂猿,这就叫做有目标攻击。
1.3 逃逸攻击的研究方向
在逃逸攻击领域,目前主要有两类研究方向:
-
设计更具攻击性的对抗样本去作为神经网络鲁棒性的评估标准(如FGSD、IFGSD、Deepfool、C&W等)
-
研究针对对抗样本攻击的防御方法,提升NN模型的鲁棒性(如对抗训练、梯度掩码、随机化、去噪等)
下面我们依次来介绍这两类研究方向的相关算法。
1.4 常见对抗样本生成方式
1.4.1 基于梯度的攻击
基于梯度的攻击是最常见也是最容易成功的一种攻击方法。它的核心思想可以用一句话来概括:以输入图像为起点,在损失函数的梯度方向上修改图像。
执行此类攻击主要有两种方法:
-
一次攻击(One-shot Attacks):攻击者在梯度方向上迈出一步,如FGSM、 T-FGSM
-
迭代攻击(Iterative attacks):攻击者在梯度方向迈出多步,逐渐调整,如I-FGSM
FGSD(Fast gradient sign method)[5]
这是一种基于梯度生成对抗样本的算法,其训练目标是最大化损失函数 以获取对抗样本,其中 是分类算法中衡量分类误差的损失函数,通常取交叉熵损失。最大化 即时添加噪声后的样本不再属于 类,由此则达到了上图所示的目的。在整个优化过程中,需满足 约束 ,即原始样本与对抗样本的误差要在一定范围之内。
![]()
其中sign()是符号函数,括号里面是损失函数对x的偏导, x是输入的图片(原始图片), 是生成的对抗样本,J是分类器的损失函数,y是输入的图片x的标签。
如对于最常见的这个熊猫图而言,这个公式就可以被形象得翻译成如下图所示。

Targeted fast gradient sign method (T-FGSM):
与FGSM类似,T-FGSM还是在计算梯度,但这个算法的不同之处在于,它梯度下降的方向是朝着目标对象的,也就是说,在梯度下降的过程中,我们在努力朝自己期望的标签的方向前进。公式如下:

I-FGSD(Iterative gradient sign Method)[6]:
前面的FGSD和T- FGSD都是一次攻击(One-shot Attacks),而I-FGSD则是迭代攻击(Iterative Attacks)的一个例子,在这个算法里,攻击者以一个小的脚步 多次应用快速迭代法:
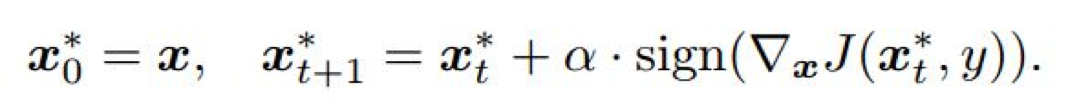
其中为了使得到的对抗样本满足 ( 或 )约束,通常将迭代步长设置为 ,T为迭代次数。
下图展示了IFGSD以不同的生成的对抗样本,未添加噪声前,样本被判定为53.98%的可能性为一个洗衣机,而添加噪声后,判定为洗衣机的概率变小,分类模型将其分类为保险箱,甚至音响。

实验表明,I-FGSD在白盒攻击上,效果比FGSM和T-FGSM好。但在黑盒攻击上,one-shot攻击的效果比迭代攻击的效果好,部分原因是迭代的方式容易过拟合。
1.4.2 超平面分类思想
除了基于梯度的对抗样本生成思想以外,我们还可以基于超平面分类的思想来生成对抗样本.
Deepfool[9]:
Deepfool是基于超平面分类思想的一种对抗样本生成方法。了解过SVM的人,应该都对超平面分类思想不陌生。事实上,在二分类问题中超平面是实现分类的基础。那么要改变某个样本的分类,最小的扰动就是将x挪到超平面上,让这个距离的代价最小,就是最小的扰动。这里为了便于描述,我们拿线性二分类问题入手,多分类问题也是类似解法,就不赘述了。
如下图所示,假设有原始样本x,标签为y,我们期望通过对原始样本添加人类不容易发觉的噪音 ,生成对抗样本 ,使分类器所生成的对抗样本的标签判定为 ,其中 ,这里的目标是找到最小的。 为该问题的分类面,
,其中
是一个线性二分类器
。
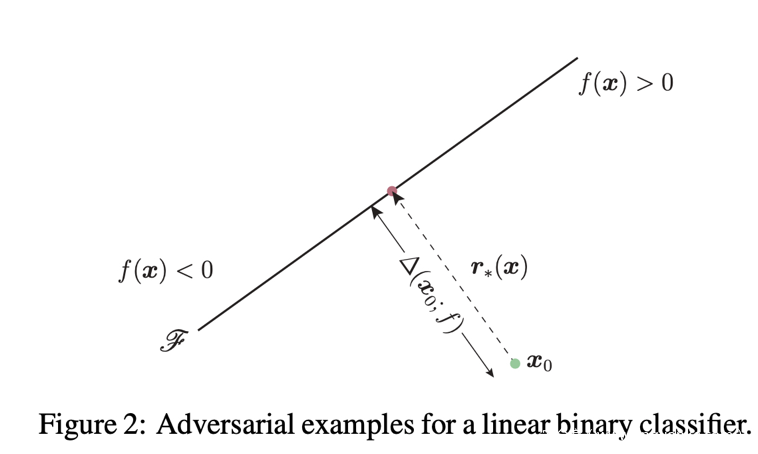
要使 被分为另外一类,最简单的扰动即方向垂直于分类面,大小为
的扰动。
根据上式,可以很容易地计算得到 ,但是这个扰动值只能使样本达到分类面,而不足以越过,故最终的扰动值为 , ,实验中一般取0.02。
1.4.3 总结
下表是对上面我们提到的算法的一个简单总结。
| 含义 | 优点 | |
|---|---|---|
| FGSD(Fast gradient sign method) | 基于梯度生成对抗样本的算法 | 黑盒攻击表现优秀,白盒攻击表现较差 |
| IFGSD(Iterative gradient sign Method) | 对FGSD的一种推广,以一个小的脚步 α多次应用快速迭代法 | 白盒攻击表现优于FGSM和T-FGSM,黑盒攻击表现较差 |
| Deepfool | 用于白盒攻击,超平面分类思想 | 扰动大小和计算时长有优势 |
| C&W | 迭代攻击算法,使用一个变量w辅助寻找最小扰动r | 进行有目标的攻击 |
| Optimization based method | 在能达到攻击目的的前提下,最小化对抗样本和原始样本之间的距离 |
1.5 常见防御方式
介绍了如何生成对抗样本,接下来我们来看一下从防御层面我们能做什么。如下图所示,主要有三个思考角度:改变输入,改变网络和添加外部防御。
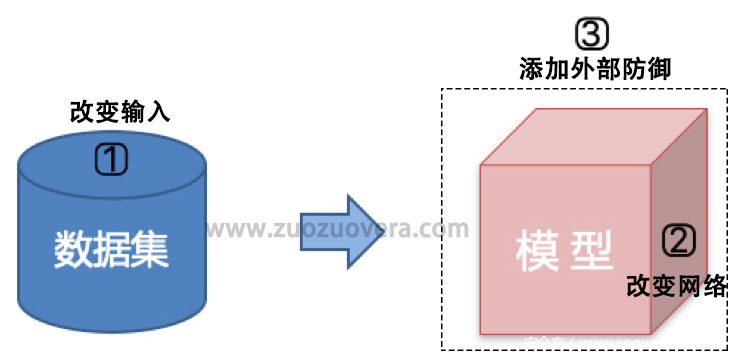
常见防御方法:
-
对抗训练:训练集除了真实数据集外,还有加了扰动的数据集
-
梯度掩码:隐藏原始梯度
-
随机化:向原始模型引入随机层或者随机变量。使模型具有一定随机性,全面提高模型的鲁棒性,使其对噪声的容忍度变高。
-
去噪:数据输入模型前,先对其进行去噪
1.5.1 对抗训练[10]
对抗训练防御的主要思想是:在模型训练过程中,将对抗样本一并加入到训练样本中,组成新的对抗样本,如此随着训练次数增多,模型的准确率会增加,模型的鲁棒性也会增加。
比如说,我们要训练一个模型来识别标签 ,输入输出关系为 , 是sigmoid函数 。根据下式作梯度下降:
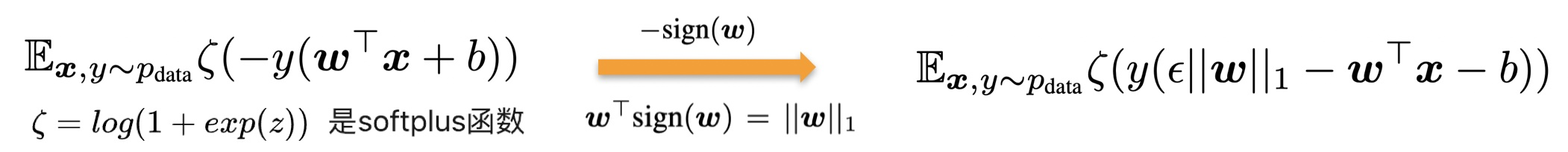
注意这里-sign(w)是梯度,将上式中的x换成加了扰动的x,就可以得到右边的式子。这里看起来很像L1正则化,但不同的是。这里的惩罚项是加在激活函数里,而不是加到损失函数里。这也意味着,随着激活函数趋于饱和,模型有足够的信心进行预测时,惩罚项会逐渐消失。增加惩罚项也会有不好的影响,可能会使欠拟合更加恶化。
1.5.2 梯度掩码/隐藏(Gradient Masking)[11]
前面我们说过,大部分“对抗样本”都是基于模型梯度来构建的。比如说对于一个图像识别模型,当我们给了它一张熊猫的图,它最终将其分类为熊猫时,实际上是在说:“这个图片在熊猫这个类别上的置信度最高”。换而言之,这张图片其实在“长臂猿”等其他类别也是有着置信度的,只是这个置信度很小而而已。因此攻击者只需要反复测试超平面的哪一个方向会导致长臂猿的置信度增加,然后朝这个方向“推一把”,添加一些扰动,那么这张经过修改的新图片就会被错误识别为“长臂猿”了。
我们从防御的角度来思考,如果我们的模型只输出熊猫,不输出其他信息,不透露给攻击者有用的信息,那么攻击者便无法得知应该在图片哪个方向上“推一把”,就能够阻挠攻击者发起的对抗攻击了。
但实际上,这是一个“治标不治本”的办法,因为模型并没有变得更稳定,我们只是提高了攻击者弄清楚模型防御弱点的难度。
此外, 攻击者也可以自己训练一个拥有梯度的光滑模型来制作“对抗样本”,然后将这些“对抗样本”放进我们保护的非平滑模型里,从而实现对模型的破解。
1.5.3 防御性蒸馏[12]
防御性蒸馏是Papernot等人训练深度神经网络的蒸馏法提出来的一个防御方法。
首先简单的介绍一下蒸馏法的原理。在机器学习领域中有一种最为简单的提升模型效果的方式:在同一训练集上训练多个不同的模型,然后在预测的时候使用平均值来作为预测值(集成学习)。但是这种组合模型需要大量计算资源,特别是当单个模型都非常复杂的时候。
有相关的研究表明,复杂模型或者组合模型中的“知识”可以通过合适的方式迁移到一个相对简单模型之中,进而方便模型推广(迁移学习)。这里所说的“知识”就是模型参数,简单说就是,我们训练模型是想要学到一个输入向量到输出向量的映射,而不必太过于关心中间的映射过程。
那么防御性蒸馏也是同理,我们希望将训练好的复杂模型推广能力“知识”迁移到一个结构更为简单的网络中,或者通过简单的网络去学习复杂模型中“知识”,从而避免攻击者直接接触到我们的模型。
防御的具体思路是:
-
首先根据原始训练样本 X 和标签 Y 训练一个初始的深度神经网络,得到概率分布 。
-
然后利用样本 X 和第一步的输出结果 (作为新的标签)训练一个架构相同、蒸馏温度 T 也相同的蒸馏网络,得到新的概率分布 ,再利用整个网络来进行分类或预测,这样就可以有效的防御对抗样例的攻击。流程如下图所示:
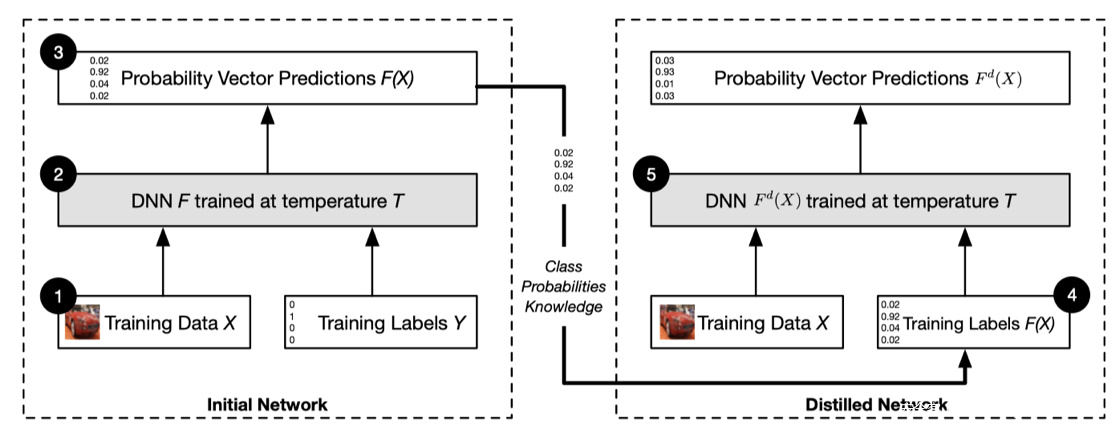
效果:
-
使得通过梯度生成的对抗样本的攻击性大大降低,并且对原始任务的准确性没有很大的影响
-
蒸馏温度越高,网络的平均梯度越小,生成具有足够攻击性的对抗样本越困难,间接地提升了模型的鲁棒性
-
本质上没有解决模型对于对抗样本鲁棒性差的问题。因此,其只能有效的抵抗白盒攻击,对黑盒攻击则无能为力
-
仅适用于基于概率分布的DNN模型,不适用于建立通用的强鲁棒性的DNN模型
1.5.4 随机化Randomization[13]
前面我们介绍过,对抗攻击从生成过程来看可以分为单步攻击(只执行一步梯度计算)和迭代攻击(进行多次迭代进行攻击)。
从效果来看,迭代攻击生成的对抗样本容易过拟合到特定的网络参数,迁移性较弱。而另一方面,单步攻击(如FGSM)具有更好的迁移能力,但是攻击性较差,可能不足以欺骗网络。正是因为迭代攻击的泛化能力不强,所以我们可以考虑低级图像变换(如调整大小、填充、压缩等)的方法来破环迭代攻击生成的对抗扰动的特定结构,从而起到很好的防御效果。如果这里的变换手段是随机变换,那么攻击者就无法确认变换方式,所以甚至可能抵御白盒攻击。此外,这种随机变换的方式与对抗训练的方式完全不同,我们可以考虑把两个防御方法结合起来使用,将有希望有效防御单步和迭代攻击,包括白盒和黑盒攻击。
此外,因为这个防御方法只是对输入样本进行了一个随机转换,没有网络参数,所以不需要重新训练或微调模型,提高了这个方法的实用性。
如下图所示,论文里主要添加了两个随机层。
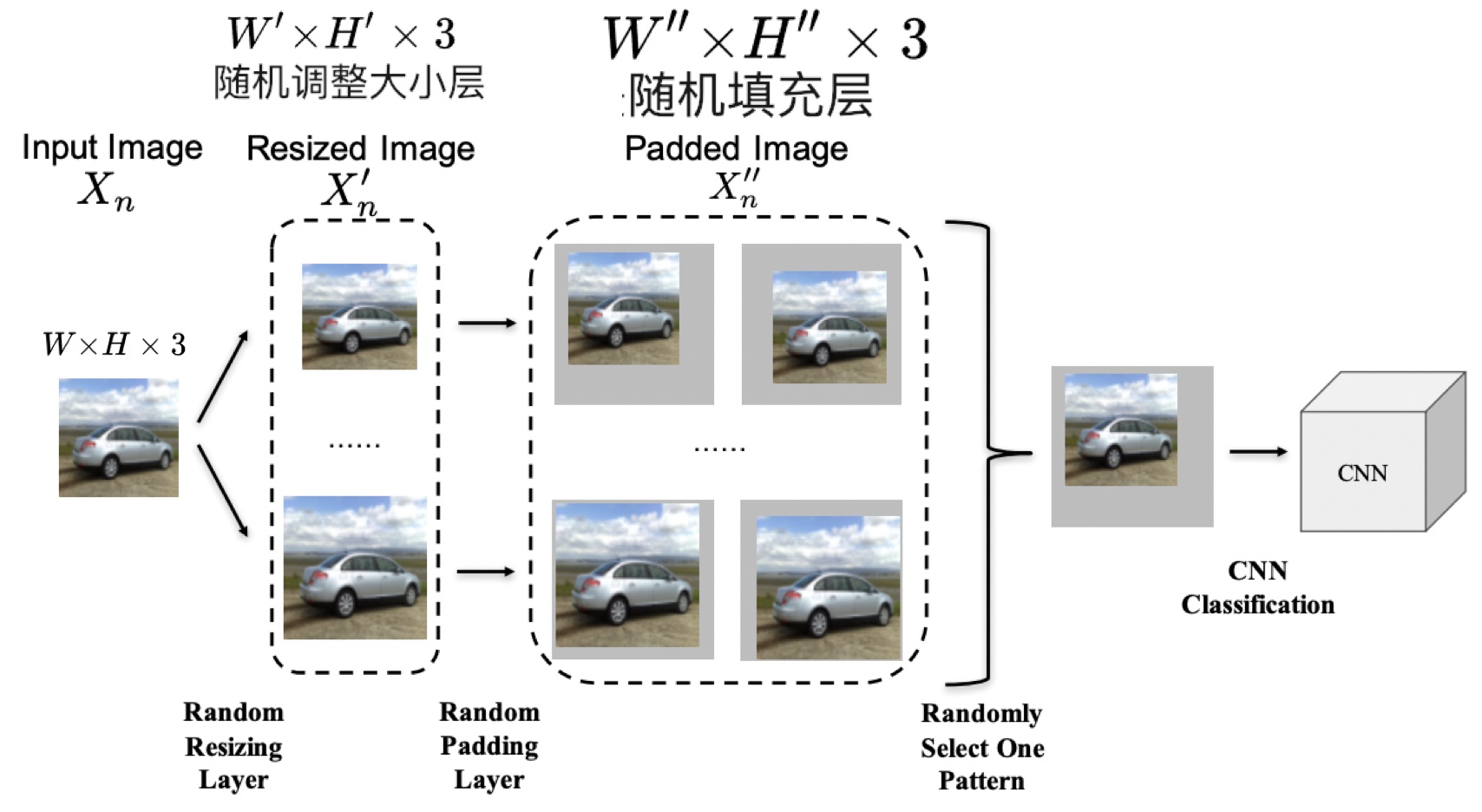
第一个随机层是随机调整大小层。假设原始图像的大小为 ,我们可以通过随机调整大小层 将调整为一个新的图像 ,大小为 。注意,这里的 和 都要控制在一个合理的小范围内,否则干净图像的分类性能会显著下降。
第二个随机层是随机填充层,以随机的方式在调整大小后的图像周围填充零像素点。具体地,就是将 填充为 ,而填充后的图像尺寸,即为分类器的输入尺寸,所以填充后的大小是固定的 。对照着上图来看填充过程的话,如果在左边填充 列零,那么就要在右边填充 列零,上下同理。这样的话,一共有 种填充方式。
将原始图像经过上述两个随机层转换后,再传递给CNN进行分类。
在论文里,作者假设了三种攻击场景(香草攻击、单模式攻击、集合模式攻击)来测试这个方法的防御性能。
(1)香草攻击(vanillaattack): 攻击者不知道随机层的存在,目标模型就是原始网络。
(2)单模式攻击:攻击者知道随机层的存在。为了模仿防御模型的结构,选择目标模型作为原始网络+随机化层,只有一个预定义模式。
(3)集合模式攻击:攻击者知道随机化层的存在。为了以更具代表性的方式模仿防御模型的结构,目标模型被选择为具有预定义模式集合的原始网络+随机化层。
效果:
-
三种攻击场景(香草攻击、单模式攻击、集合模式攻击)下,防御模型性能普遍优于目标模型
-
当攻击者不知道随机层存在时,随机层防御的效果最佳
-
当攻击者知道有随机层的存在,但由于随机模式众多,不可能考虑所有的随机模式,所以防御依然有效果
1.5.5 去噪[14]
第四种方法是去噪,思想非常简单,既然攻击者是通过增加噪音来生成的对抗样本,那么我们只要把样本中的噪声去掉,尽可能将其恢复成原始样本不就好了吗?
这篇文章里,作者尝试使用了两个不同架构的神经网络作为去噪器来进行去噪。一个是 Denoising Autoencoder(DAE),另一个是 Denoising Additive U-Net(DUNET),两者结构如下图所示。其中表示原始图片,表示去噪后的图片。作者的去噪器(PGD)的损失函数为 ,表示原始图片和去噪后的图片的差异,最小化损失函数就可以得到尽可能接近原始图片的去噪后图片。
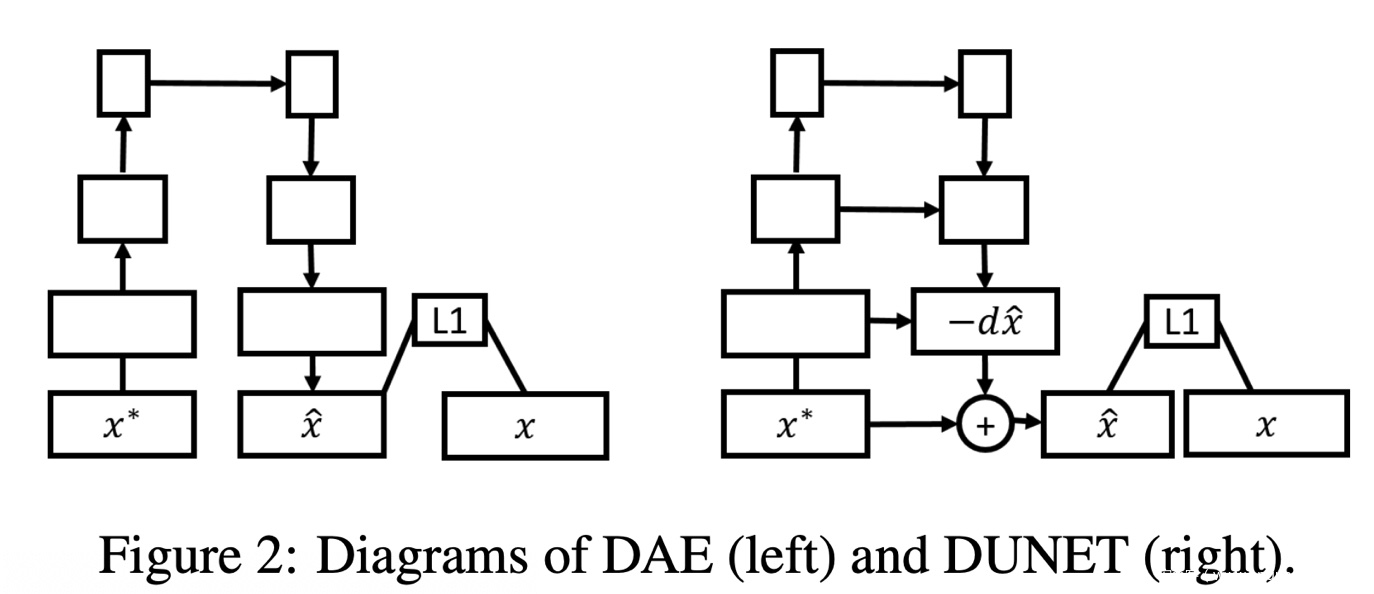
但是这种去噪器在实验过程中,出现了一个现象,就是输入经过去噪以后,正确率反而有点下降。这主要是因为去噪器不可能完全消除扰动,剩下的微小扰动在预训练好的卷积网络模型中逐层放大,对卷积网络的高维特征产生了较大的扰动,最终导致网络分类错误。
针对这个问题,作者又提出了一种以高级表示为导向的去噪器(HGD),结构如下图所示:
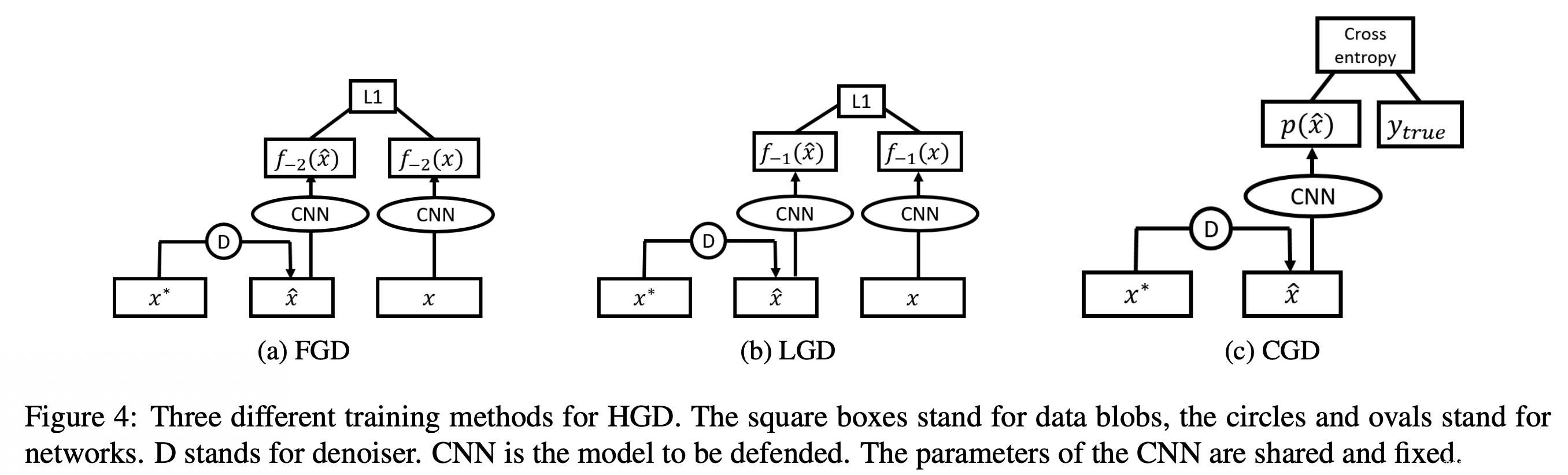
从图中可以看出。HGD与PGD最大的区别在于不再以去噪后图片与原始图片的差异 作为损失函数,而是将去噪后的图片和原始图片都输入到预训练好的深度神经网络模型中,将最后几层的高级特征的差异 作为损失函数来训练去噪器,这样就避免了PGD的扰动逐层放大的问题。
效果:
-
两种网络结构在处理干净图片时准确率都有所下降。
-
PGD的差异随着网络逐层放大,最后快接近于未经过去噪的对抗样本,HGD的误差较小,变化不是很大。
-
HGD能在特征层面有效的抑制扰动,在黑白盒攻击面前都有很强的鲁棒性。
但同时这个方法也存在着一定的缺陷:
-
依赖于微小变化的可测量,问题没有完全解决
-
除非对手不知道HGD的存在,否则还是可能受到白盒攻击
结语
在本文中,我们对逃逸攻击进行了详细的介绍,主要分为应用场景、攻击模式、研究方向、常见对抗样本生成方式和常见防御手段5个方面。逃逸攻击是最近快速崛起的一个研究方向,对工业界和学术界都有着很重大的意义。但因为逃逸攻击的研究成果众多,故作者在这里只是起到抛砖引玉的作用,欢迎大家共同交流进步。
在下一篇文章里,我们将聚焦破坏模型完整性的另一种攻击方式,数据中毒攻击。
References
[1] Szeged C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[J]. arXiv preprint arXiv:1312.6199, 2013.
[2] Lu J, Sibai H, Fabry E. Adversarial Examples that Fool Detectors[J]. arXiv preprint arXiv:1712.02494, 2017.
[3] Sharif M, Bhagavatula S, Bauer L, et al. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016: 1528-1540.
[4] Carlini N, Mishra P, Vaidya T, et al. Hidden Voice Commands[C]//USENIX Security Symposium. 2016: 513-530.
[5] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
[6] Kurakin A, Goodfellow I, Bengio S. Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533, 2016.
[7] <EYD与机器学习>:对抗攻击基础知识(一). https://zhuanlan.zhihu.com/p/37260275.
[9] Moosavi-Dezfooli S M, Fawzi A, Frossard P. Deepfool: a simple and accurate method to fool deep neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 2574-2582.
[10] Goodfellow M, Jones A L. Laceyella[J]. Bergey’s Manual of Systematics of Archaea and Bacteria, 2015: 1-4.
[11] Papernot N, McDaniel P, Goodfellow I, et al. Practical black-box attacks against machine learning[C]//Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security. ACM, 2017: 506-519.
[12] Papernot N, McDaniel P, Wu X, et al. Distillation as a defense to adversarial perturbations against deep neural networks[C]//2016 IEEE Symposium on Security and Privacy (SP). IEEE, 2016: 582-597.
[13] Xie C, Wang J, Zhang Z, et al. Mitigating adversarial effects through randomization[J]. arXiv preprint arXiv:1711.01991, 2017.
[14] Liao F, Liang M, Dong Y, et al. Defense against adversarial attacks using high-level representation guided denoiser[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1778-1787.







发表评论
您还未登录,请先登录。
登录