

前言
本文是《AI与安全》系列文章的第三篇。在前文中,我们介绍了Attack AI的基础概念,即黑客对AI发起的攻击,主要可以分为三种攻击类型,破坏模型完整性、可用性和机密性的攻击。
其中破坏模型完整性主要分为两类攻击,针对模型的逃逸攻击和针对数据的数据投毒攻击。

在本文,我们将介绍破坏模型完整性的数据投毒攻击。
1 数据投毒攻击是什么
数据投毒/中毒攻击(Data Poisoning Attack)是什么?这里我们用几个例子来说明。

对于一辆无人驾驶汽车,不同于逃逸攻击直接构造对抗样本对模型和系统发起攻击,由于智能汽车的识别模型通常是基于历史数据进行训练定期生成的,那么黑客就可以产生一些实时的数据或者说一些黑客以前已经习惯于走这些道路的数据,把这些数据输入到云端或者智能汽车系统中,从而实现让智能汽车按照黑客想要的路径去前进,利用数据投毒的方式来攻击人工智能系统。
此外,当前市面上的问答式机器人/智能交互AI,如微软小冰、QQ小冰等,它们通过庞大的语料库来学习,还会将用户和它的对话数据收纳进自己的语料库里,因此我们也可以在和它们对话时进行“调教”,从而实现让其说脏话甚至发表敏感言论的目的。

在业务安全领域,阿里集团安全资深总监路全在CCF大会上也分享过一个数据中毒的例子 :
“阿里的有些端口每天会来很多爬虫。有些爬虫即使被杀掉了,还是不断的来。这就非常奇怪了,因为他是在浪费他的钱。
后来他们发现,这些爬虫其实也是在用一种非常聪明的方式污染模型,因为他除了有大量低级爬虫或者说低级流量外,他还有一部分高级的爬虫。他不怕低级的被模型识别和杀掉,但是他知道模型会被大量低级爬虫样本的特征所带偏,所以他实际上是用低级爬虫做诱饵,然后让高级爬虫帮他达到目的。”
2 数据中毒的根本原因
通过前面的例子,细心的小伙伴可能也发现了,数据中毒的根本原因,其实是传统机器学习方法并没有假设输入模型的数据可能有误,甚至有人会故意搅乱数据的分布。
通常情况下,如果我们通过时间滑窗的方式来生成模型,我们期望的是今天的数据和上周数据的平均分布是差不多的,或者说每周一的数据分布情况都差不多。基于这个假设,模型才成立。而这个假设恰好就让攻击者有机可乘了。

3 数据投毒攻击分类和解决方案
在这一部分,我们详细介绍数据投毒攻击的分类和对应的解决方案。
3.1-模型偏斜(Model skewing)
模型偏斜是指攻击者试图污染训练数据,来让模型对好坏输入的分类发生偏移,从而降低模型的准确率。
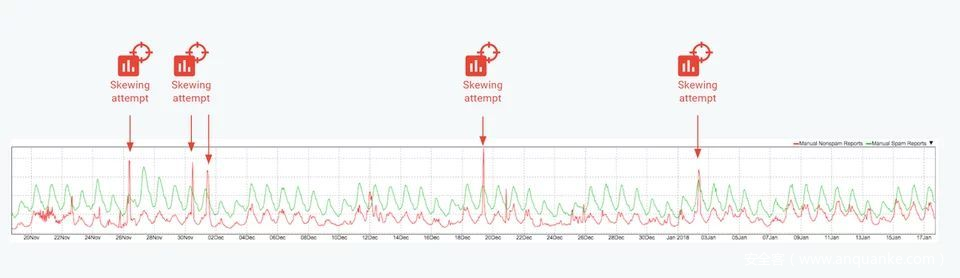
例如,Google反滥用研究团队的主管曾经介绍过发生在Google垃圾邮件分类器上的数据投毒攻击案例。一些最高级的垃圾邮件制造者试图通过将大量垃圾邮件提交为非垃圾邮件来使 Gmail 邮件分类器发生偏斜。
如图所示,2017 年 11 月底至 2018 年初,Gmail遭遇了至少 4 次大规模恶意攻击试图让分类器偏斜。
因此,在设计 AI 防御机制时,需要考虑以下事实:
攻击者一定会非常积极地将正常数据和异常数据之间的那条分界线转移到对他们有利的位置。
这种攻击的解决方案,通常有三种:
1、 使用合理的数据采样。需要确保一小部分实体(包括 IP 或用户)不能占模型训练数据的大部分。特别是要注意不要过分重视那些伪装成正常样本的恶意样本。这可能通过限制每个用户可以贡献的示例数量,或者基于报告的示例数量使用衰减权重来实现。
2、 将新训练的分类器与前一个分类器进行比较以估计发生了多大变化。例如,可以执行 dark launch,并在相同流量上比较两个模型的输出结果。还可以对一小部分流量进行 A/B 测试和回溯测试。
3、 构建标准数据集,分类器必须准确预测才能投入生产。 在标准数据集里包含一组精心策划的攻击和系统的正常数据。只有当模型在这个标准数据集上的效果达标的情况下,才能上线该模型。从而避免数据投毒攻击直接对生产环境上的模型造成负面影响。
3.2-反馈武器化(Feedback weaponization):
反馈武器化是指将用户反馈系统武器化,来攻击合法用户和内容。一旦攻击者意识到模型利用了用户反馈对模型进行惩罚(penalization),他们就会基于此为自己谋利。
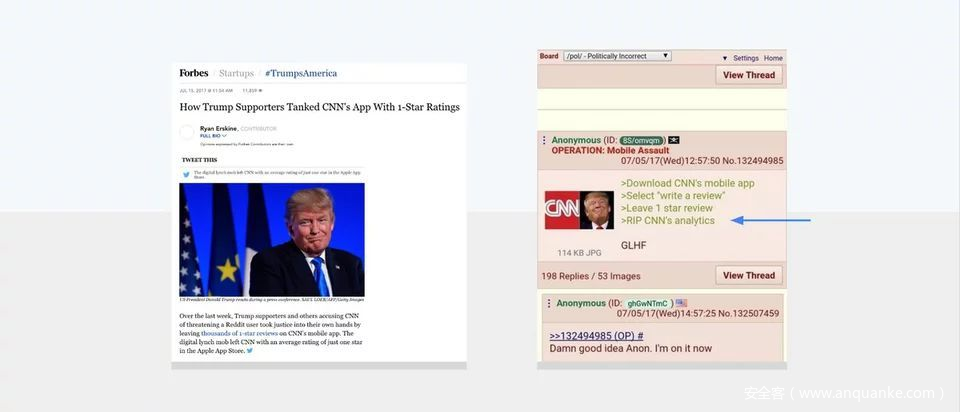
比如说如果我们想攻击一个交互系统,比如说智能客服,每次它回答问题后,下面会弹出一个服务评分选项。那只要我们持续地给正确答案打1星,错误答案打5星。如果背后的模型没有对数据投毒攻击有所防范,那这个智能客服模型就会被成功干扰。
因此,在构建系统时,需要考虑以下假设:
任何反馈机制都将被武器化以攻击合法用户和内容。
解决方案:
- 不要在反馈和惩罚之间建立直接循环。相反,在对模型进行惩罚前,应该确保评估反馈真实性,并将其与其他特征结合起来。
3.3-后门攻击(backdoor attacks)
在一部分文献里,后门攻击被列入了逃逸攻击或数据投毒攻击,在另一部分文献里,后门攻击被单独归为一类。在本文中,我们将后门攻击视作模型投毒攻击的一个子类。
模型后门(backdoor)是指通过训练得到的、深度神经网络中的隐藏模式。和逃逸攻击中直接让模型将一个物品识别错误不同,后门攻击是指当且仅当输人为触发样本(trigger)时,模型才会产生特定的隐藏行为;否则,模型工作表现保持正常。
针对机器学习中极其常用的MNIST手写数据集,有学者提出了通过数据投毒方法来注入后门数据集,并达到99%以上的攻击成功率,但不会影响模型在正常手写样本上的识别性能。
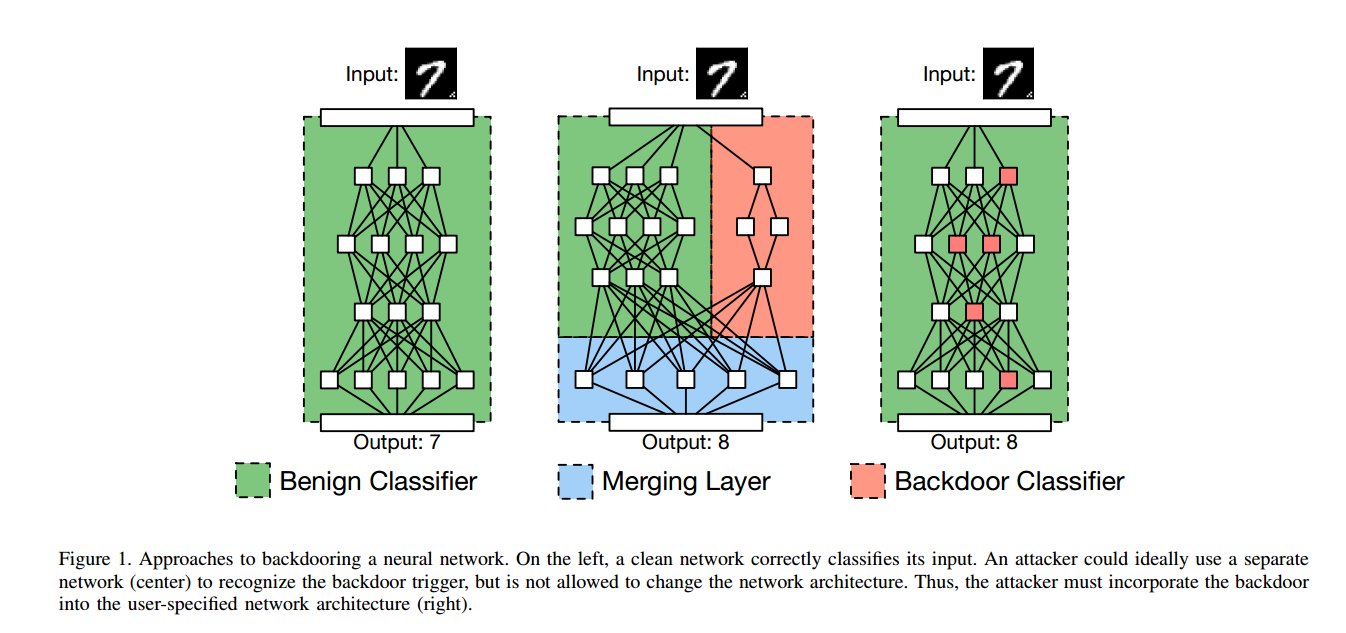
如上图所示,图左是一个正常的模型,图中是黑客期望的模型的样子(导致结果识别为8,而非7)。但黑客没有办法修改模型,所以他必须将后门合并进用户指定的网络架构里(右)
下面这张图 ,最左边就是原始的手写图片,中间和右边的图片分别被添加了后门(右下角的白点)。

对细节感兴趣的可以去读读这篇论文《BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain》
补充阅读
[1] Xiao H, Biggio B, Brown G, et al. Is feature selection secure against training data poisoning?[C]//International Conference on Machine Learning. 2015: 1689-1698.
[2] Li B, Wang Y, Singh A, et al. Data poisoning attacks on factorization-based collaborative filtering[C]//Advances in neural information processing systems. 2016: 1885-1893.
[3] Alfeld S, Zhu X, Barford P. Data Poisoning Attacks against Autoregressive Models[C]//AAAI. 2016: 1452-1458.
[4] Marsh D O, Myers G J, Clarkson T W, et al. Fetal methylmercury poisoning: clinical and toxicological data on 29 cases[J]. Annals of Neurology: Official Journal of the American Neurological Association and the Child Neurology Society, 1980, 7(4): 348-353.
[5] 陈宇飞, 沈超, 王骞,等. 人工智能系统安全与隐私风险[J]. 计算机研究与发展, 2019, 56(10).







发表评论
您还未登录,请先登录。
登录