
攻击者可能会使用各种技术来欺骗自动语音验证系统( automatic speaker verifification),以使其接受他们为真实用户。同时,反欺骗方法旨在使系统能够抵御此类攻击。 在这项工作中提出了重放攻击检测系统-注意力过滤网络(Attentive Filtering Network),它由一个基于注意力的过滤机制和一个基于ResNet的分类器组成,该机制可在频域和时域上增强特征表示。 该网络能够可视化自动获取的特征表示,这有助于欺骗检测。注意力过滤网络在数据集上获得的EER评估为8.99%。
0x01 Absert
近年来,随着语音助手和智能家居设备的出现,自动语音验证(ASV)系统已变得越来越普遍。但是,这些系统可能容易受到表示攻击的影响,即欺骗攻击。欺骗者可能会通过模仿真实用户的语音特征等方式来欺骗ASV系统以使其接受为目标语音。为了确保ASV技术的持续可靠性,有必要制定对策以防止这种欺骗攻击。欺骗攻击有四种类型:模拟,重放,语音合成和语音转换。
先前工作通常可以分为三类:高斯混合模型(GMM)和基于i-vector的系统;基于高斯混合模型的系统;基于高斯混合模型的系统。基于深度神经网络的系统。
这里的工作目标是开发一种深度学习系统,该系统利用时域和频域中的判别功能进行欺骗检测。其动机是欺骗攻击的线索可能会随时间变化,并且只能部分地观察到,例如可能出现在口语单词之间的噪音或语音的高频成分中。但是不确定这些线索可能嵌入到特征空间中的何处,因此需要一种能够自动获取和增强区分时间和频率特征的系统,以帮助检测欺骗攻击。通过设计基于注意力机制的过滤器以在基于ResNet的分类器之前取消或增强功能来实现此目的。
在设计基于注意力机制的过滤器时,从三项先前的研究中获得了启发。刺激训练(Stimulated training)通过在神经网络声学模型训练中,通过叠加一个电话集,以可解释的方式分组。这激发了研究在模型训练中应用注意力机制的方法。卷积注意力网络根据语音频谱图和嵌入的单词序列计算注意力矩阵,并将其与分类符之前的频谱图相乘。这项工作启发了在分类器之前应用注意力机制。残差注意力网络(convolutional attention network)应用了一个自下而上的前馈过程和自上而下的注意力反馈。这项工作启发了在过滤器中采用类似的过程。
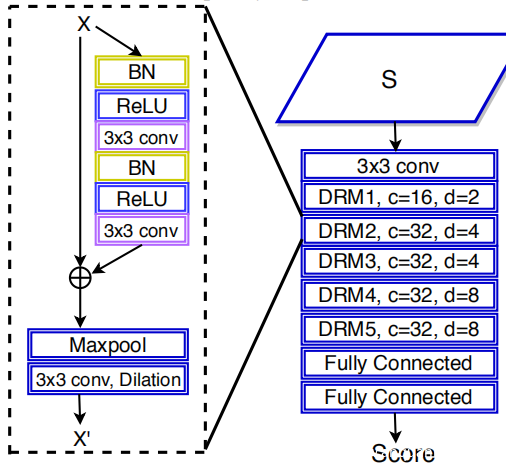
本文基于ResNet的分类器(称为扩散残差网络(DRN))使用卷积层而不是完全连接的层,并且通过添加膨胀因子来修改残差单元。过滤器和分类器共同构成了提出的方法:注意力过滤网络(AFN)。
0x02 Attentive Filtering Network
A.特征工程
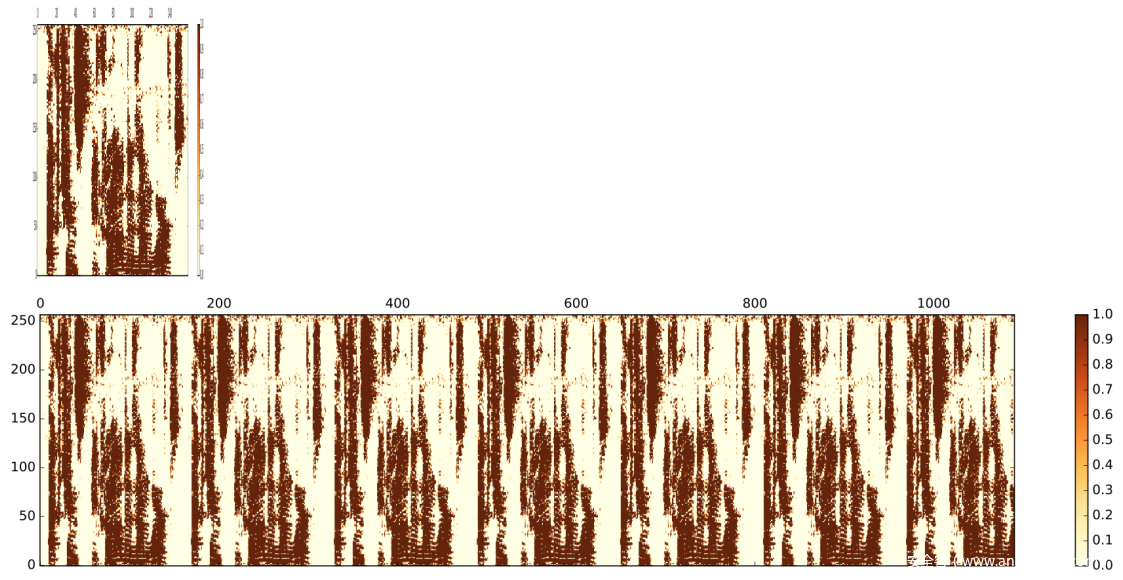
根据通过快速傅立叶变换获得的对数功率大图谱(logspec)创建了统一的时频图,作为网络的输入。 logspec的维数是257,保留所有帧而不应用语音活动检测,并使用3秒的滑动窗口应用均值归一化。通过重复所有特征并将所有话语扩展到最长话语的长度来创建统一的时频图,如上图所示。所有话语的时频图的维数为257(频域)乘以1091 (时域)。这种特征工程方法的好处是不需要截断特征,并且由于它是话语级特征表示,因此不需要帧级分数组合。
B.扩张残差网络
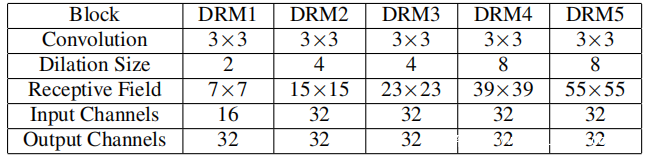
扩张(dilation)的残差网络由五个扩张的残差模块(DRM)组成,如下图右侧所示。每个DRM都有一个基于3×3 CNN的残差单元,其后是最大池化层和扩张的卷积层,如下图左侧所示。
在DRM中包括扩张的卷积层的动机来自以下观察结果,特别是,训练集很小,评估集包含的条件与训练和开发集中的条件完全不同。因此,防止过度拟合是获得良好性能的重要因素,而在不损害模型能力的情况下减少小数据集过度拟合的影响的一种想法是在卷积中包含扩张。扩张卷积运算* d定义为:
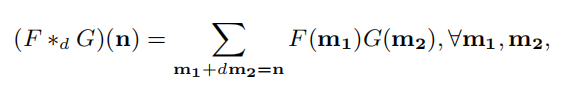
其中F是特征图,G是核,d是扩张率,m1,m2和n是向量。借助扩张的卷积,网络的接受域随层深度呈指数增长,从而可以整合更广泛和全局环境中的知识。最大合并层允许减少特征图的空间尺寸。
C.注意力过滤
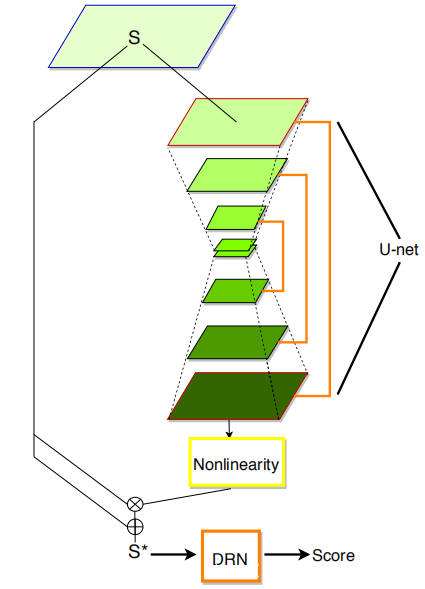
注意力过滤(AF)选择性地在频率和时域中累积区分性特征。 AF通过注意力热力图As来扩张每个输入的特征图S。然后,将增强的特征图S *视为DRN的新输入,如上图所示。对于S,AF描述为:
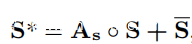
其中F和T是频率和时间维,◦是元素乘法运算符,+是元素加法运算符。As被描述为:
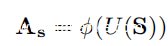
其中φ是诸如sigmoid或softmax的非线性变换,U是类似U-net的结构,由一系列下采样和上采样操作组成,而S是输入。如使用最大池进行下采样,使用双线性插值进行上采样。此外,在相应的自下而上和自上而下的部分之间添加了跳过连接,以帮助学习注意力权重。
本文提出的模型中的注意力权重是直接在特征域中学习的,而不是在卷积域中学习的。这样做的原因是,首先,ASVspoof2017数据集比ImageNet小得多,并且方法可能无法适应可用的训练数据量。其次,更重要的是,输入特征级别的注意力热图比随后的卷积级别更容易解释。
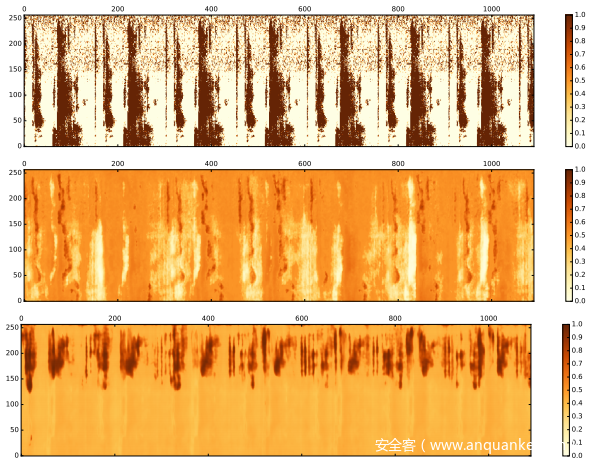
上图显示了使用和不使用S时学习到的注意力热图。可以清楚地看到,当使用S训练注意力热图时,注意力集中在语音段的高频成分上。直观的解释是,通过充分利用DRN形成S,AF可以专注于学习注意力权重,而不是学习S的摘要。还可以看到,使用S,AF可以选择性地参与并增强高频段而且还包括任何时间段和频率段。
D.优化
AF和DRN是注意力过滤网络工作的两个组成部分,并且对网络进行了端到端的培训。使用Xavier初始化初始化Attentive过滤网络,并使用AMSGRAD的Adam对其进行优化。还根据每个训练时期后在开发集上测得的均等错误率(EER)进行了模型选择,因为这样做会产生更好的结果。
0x03 Experiments
A.基准系统
CQCC-GMM:CQCC是使用常量Q变换(一种感知动机的时频分析工具)派生的,并且已被证明对欺骗对策特别有效。对于每个语音,从两个模型都获得对数似然度分数,并且将最终系统分数计算为对数似然比。
i-vector:i-vector 将可变长度的语音记录打包成固定尺寸的嵌入。尝试了具有100维i矢量的64混合通用背景模型(UBM)和具有200维i矢量的128混合UBM。 i-vector提取器接受了来自ASVspoof 2017训练集中的30维CQCC功能的训练。还对说话者级别的i向量进行了长度标准化。然后,在每个类别中对这些i向量进行平均,从而为真实语音提供一个i向量表示,并为欺骗性语音提供另一个i向量表示。为i-vector使用了两个简单的分类器:高斯线性生成模型和余弦相似度。
LCNN:提交给的最佳系统是基于LCNN,其中CNN使用了最大特征映射激活。根据规范重新实现了用于音频重放攻击检测的LCNN,并在ASVspoof 2017版本2.0数据集上对其进行了测试。
B.实验装置
这项工作中的所有实验均在ASVspoof 2017数据集的2.0版中进行。数据集在训练集中具有1507个重播和1507个真实文件,在开发集中具有950个重放和760个真实文件,而在评估集中具有12008个重放和1298个真实文件。仅使用训练集来训练系统。开发集用于验证期间的模型选择和调整系统融合的逻辑回归。
在本文中,将提出的系统与ASVspoof 2017数据集的2.0版和1.0版之前的工作进行了比较。关于实现,注意力过滤网络已在PyTorch中实现,模型的实现和训练可在github存储库中找到(github.com/jefflflai108/Attentive-Filtering-Network)
系统融合结合了不同模型的优势,以提高整体性能。在这项工作中使用BOSARIS工具包进行分数融合。首先使用开发集将网络的输出标准化。然后,进行逻辑回归以得出融合权重和偏差
C.单系统实验结果
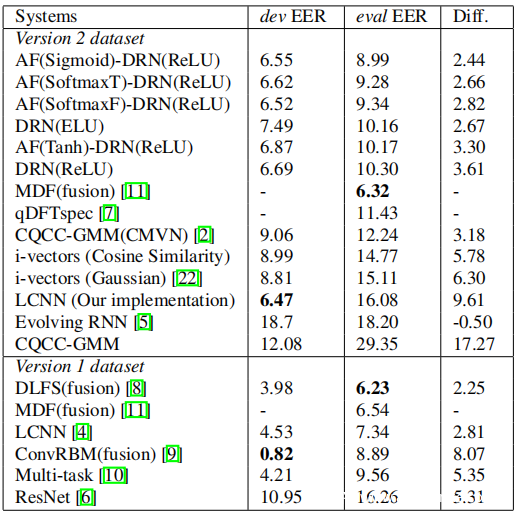
上表在等错误率(EER%)方面比较了各种系统。总体而言,提出的网络在2.0版数据集上取得了有竞争力的结果。具有ReLU激活功能的DRN系统在评估集上达到10.3 EER,具有ELU激活功能的DRN系统达到10.16 EER。通过在DRN中添加AF,可以进一步降低EER。检查不同的非线性激活函数的效果,使用Sigmoid的AF可获得8.99 EER,其后是SoftmaxT的9.28,SoftmaxF的9.34和Tanh的10.17。该表还显示了评估集和开发集上EER之间的绝对差值。这表明模型可能过度适合训练样本的程度。发现建议系统的这些差异很小,这表明即使从给出的不平衡小数据集中,模型也能很好地概括。
D.使用融合的实验结果
下图显示了不同实体非线性变换的注意力热图。看到SoftmaxT和SoftmaxF实施稀疏激活,而Sigmoid显示了多个时间和频率区间的激活。可以通过非线性如何缩放每个特征维来简单地解释激活的差异。 Sigmoid独立地缩放每个维度,而Softmax依赖地缩放每个维度,这意味着仅激活了几个维度,而大多数维度被抑制(如图所示,大多数值接近0)。 Softmax非常适合分类任务,但不适用于上下文,因为在每个上下文中,每个维度的规模对于检测重放攻击很有用。
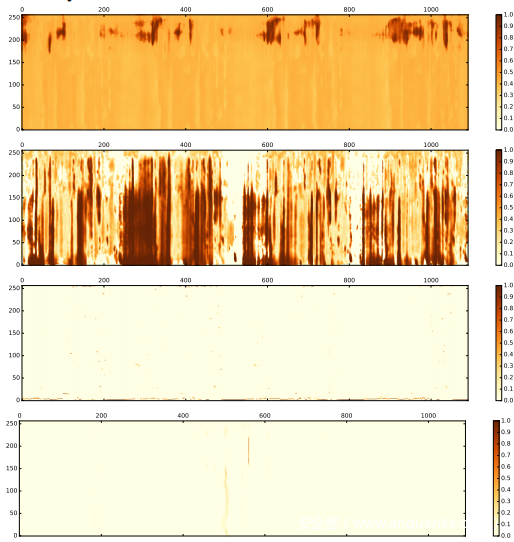
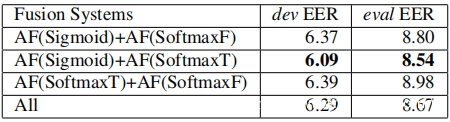
上图还表明,AF中的不同非线性激活功能采用了任务的不同方面,并且由于它们可能是互补的,因此决定使用Sigmoid,SoftmaxF和SoftmaxT激活函数融合多个AF系统。下表给出了融合系统的结果。不出所料,各个AF系统是互补的,将它们融合在一起可进一步降低EER。通过将两个AFN的输出与Sigmoid和SoftmaxT非线性融合,可以得到dev和eval的最佳结果分别为6.09和8.54。
0x04 Conclution
本文介绍了用于对抗音频重放的系统。注意力过滤网络由注意力过滤和扩张的残差网络组成,后者主要负责并增强输入特征的表示。在ASVspoof 2017版本2.0数据集上进行的实验表明,该模型在重方攻击检测中是有效的,此外,可视化注意力热图还为网络的功能增强行为提供了证据。最好的单一系统获得了具有竞争力的8.99%评估EER,最好的融合系统提供了8.54%的评估EER,相对于增强的基准系统而言,相对提高了30%。







发表评论
您还未登录,请先登录。
登录