越来越多的商业产品使用AI/ML算法来检测威胁和漏洞,但大家的使用体验往往与厂商宣称的AI模型的高指标不符,与传统方案比起来,似乎也没什么太大的区别。
笔者也训练过一些安全类模型,其在线上表现情况,明显比测试情况要差。为什么会出现这种情况呢?本文将对此问题进行深入探讨。
“准确率”不准确
准确率(ACC)是评价模型的重要指标,意为正确分类的样本数量与总样本数的比例。这里把恶意样本定义为正样本,正常的样本(非恶意样本)定义为负样本。
TP:(True Postive) 实际为恶意样本,并且被正确检测为恶意样本的数量。
TN:(True Negative) 实际为正常样本,并且被正确检测为正常样本的数量。
ALL:全部的样本数量
那么准确率的定义是:
ACC = (TP+TN )/ALL
如果你要识别各种动物的模型,你能很容易的从互联网上抓取大量动物图片,并使各种动物比例保持1:1。放到线上,用户上传的各类动物的图片比例也基本保持一致,至少不会有数量级的差别。这种情况下,测试集中各种动物比例保持为1:1,测得的ACC值是有参考价值的。
但是在安全领域不同,正常的样本很容易获取,但恶意样本数量极少。
当一个数据集里,正常样本远大于恶意样本时,有:TN >> TP 推导出 TN/ALL >> TP/ALL 。
根据计算ACC的公式
ACC = (TP+TN )/ALL = TP/ALL + TN/ALL
由于TN/ALL >> TP/ALL,也就是说这种情况下,TN/ALL基本上决定了 ACC值。
举个例子,我要测试一款WAF的准确率。抓取了一份真实的流量作为测试集,这份测试集包含10000个HTTP请求样本,但是只有100个攻击请求,其余9900个是正常业务的流量。我不小心关闭了WAF的所有策略,这样不管是攻击流量还是正常流量,一律当作正常流量放行。测试结果:(0+9900)/10000 = 99%。这样一个ByPass状态的WAF,准确率ACC竟然高达99%,这简直是个笑话。
因此,在不知道测试样本分布比例的情况下,只看ACC指标是没有意义的。如果样本比例不均匀,应当参考AUC指标。
混淆“验证集”和“测试集”
有时模型在测试集上表现很好,却在线上使用的时候一塌糊涂。这有可能是模型的“泛化”能力不强,而由于训练集和测试集的同质化严重,因此各种指标都无法如实反应模型的真实水平。(泛化,是指模型对于没有见过的新样本的分类能力)
我们从一个机器学习常用的函数说起,Sklearn的tain_test_split函数。

它的逻辑是先将数据集随机打乱,然后按某个固定比例将数据集分为两个互补的子集。人们习惯把其中一个子集叫做训练集,用于训练模型,另一个子集,用于初步验证模型效果,叫做验证集,又因为它有辅助调参的作用,也叫开发集。这两份子集来源于一个数据集,因此相似度极高、同质化严重。我看了很多安全类的项目,直接把验证集当作测试集,把验证集的指标当作模型的最终指标发布,这样是不严谨的,这样的指标也是严重虚高的。
如果我们把测试集当作高考的话,那么验证集就是模拟考试。模拟考试的题都是自己老师出的,老师上课讲过的题型,和平时作业题很像,考试环境也很好,容易考出高分。但高考会出现陌生的题型,考试环境也不熟悉,分数就不一定高。
我曾经做过一个实验,用CNN撸了一个检测SQL注入的模型。正样本是在一个mysql注入点上,用sqlmap的盲注、延时、联合、报错这四种注入手段,进行爆库、表、字段、内容,记录所有payload,形成正样本,同时采集等量正常数据作为负样本,形成数据集。用tain_test_split切割为训练集和验证集。
结果在验证集上表现非常优秀,ACC=100% TPR=100% (TPR=TP/所有正样本 =1-漏报率)
然后我制作了第一份测试集,记录了sqlmap通过这个注入点读写文件的payload。结果依旧: TPR=100%。说明模型还是有一定“泛化”能力,但是毕竟都是sqlmap生成的数据,依旧与训练集存在不少相似特征。
于是我又做了第二份测试集,使用Pangolin、Havij、WVS分别针对mysql和mssql注入点进行攻击,生成了一份数据,测试结果立马下降到:TPR=91%。这还不包括payload变形,相信在线上环境,这个指标会进一步下降。
验证集上指标虚高是因为与训练集相似度高。同理,如果测试集与训练集来自同一个源,尽管是两份不同的数据集(例如SQLMAP脱库和操作文件两种攻击数据),也会造成指标偏高。综上,测试集与训练集的相似度越高,指标就越(偏)高;测试集越是复杂多样,测试指标就会越低、越接近真实水平。
“误报”的放大
如图是某款NTA的白皮书,其宣称的误报率是0.01128。
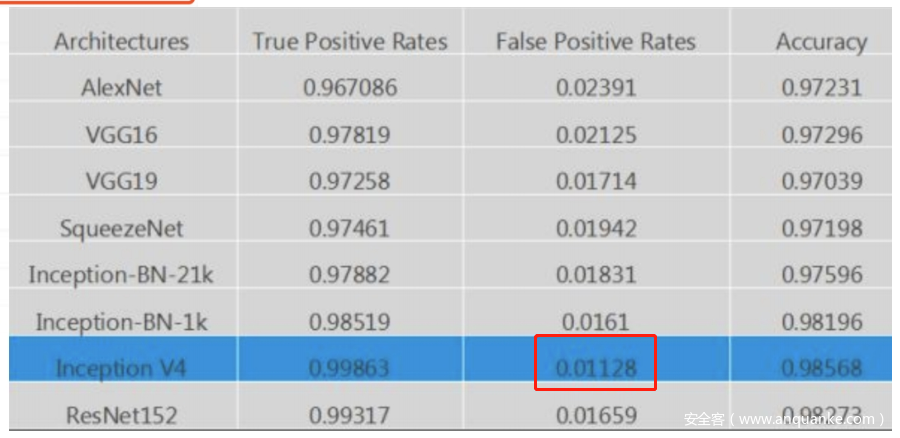
这个误报率算是比较低的。如果是在其他领域,这是一个合格的模型。因为其他领域中,每一类样本出现的概率大致相同。
但是在安全领域内不一样,在线上环境中,正常样本的数量要远远大于恶意样本数量,其差距何止几个数量级。例如对于IDS/IPS来说,攻击流量远远小于业务本身的正常流量;对于杀毒软件/EDR来讲,病毒文件的数量远远小于各种正常软件的文件。
而这个NTA 宣称的1.128%的误报,看似很低,设想如果网络中每秒建立10个会话,那么平均不到10秒就会产生一个误报。显然如果单独使用这个模型会造成“车祸现场”般的用户体验。但这并不意味着这是个失败的NTA,我们要看它后续对于误报的处理,如果在模型后面串联了二次确认的逻辑,能将误报降低到可接受的范围,也未尝不是一个好产品。
因此,由于安全场景的特殊性,即便很小的误报率也会被无限“放大”。用户看不到分母,只能看到结果。尽管误报多不代表误报率高,但误报过多确实影响用户体验和用户信任。
训练集的局限性
最理想的训练集,并不一定是越多越好,而是尽可能多地涵盖真实世界发生的每一种情况。然而真实情况是,采集的样本不可能包含每一种情况,或多或少的都会存在局限性,这是不可避免的。但是有些局限性是人为的错误导致,是可以避免的。
公司在客户现场部署了某个以DGA算法为卖点的NTA,跑了几个月几十页误报,一条有效告警都没有。于是我决定自己写个DGA检测算法,期间参考了不少AI检测DGA的文章,发现了一个几乎所有项目的通病:负样本喜欢采用Alexa Top N的域名。
Alexa Top N的域名都是正常域名,这点毋庸置疑,作为负样本似乎没什么问题。却忽略一个问题:Alexa排名靠前的都是高质量域名,网络中高质量的域名毕竟是少数,大量小企业和个人没有足够的预算投入在域名上,只给程序解析用的域名取名更加随意。低质量域名与高质量域名的统计特征区别很大,高质量域名长度短,常见一到两个单词或拼音,或是纯数字,便于记忆。低质量域名较长,常见字母和数字混合,拼音缩写,中英混合等。需要注意的是,DGA生成的域名也大都是低质量域名。如果用低质量的正常域名去测试模型的话,实际误报率应比理论值高。
我们以这个项目为例:
https://www.freebuf.com/articles/network/153345.html
该模型的ACC 97%~98% AUC 99.6%,是一个不错的模型,文章没有说明误报率FPR是多少,一般有FPR < 100%-ACC,因此估计误报率不会超过3%。但是负样本使用Alexa Top 50w进行训练,有很大的局限性。下面我们测一下模型对低质量域名的误报情况。
我在公司办公网出口进行抓包一小时,提取所有域名。为了保证测试集都是低质量的域名,排除了Alexa Top 100万的,去掉了gov.cn和edu.cn结尾的,去重后共有26个域名,全部都是正常域名。模型取0.5作为阈值。检测结果如下:
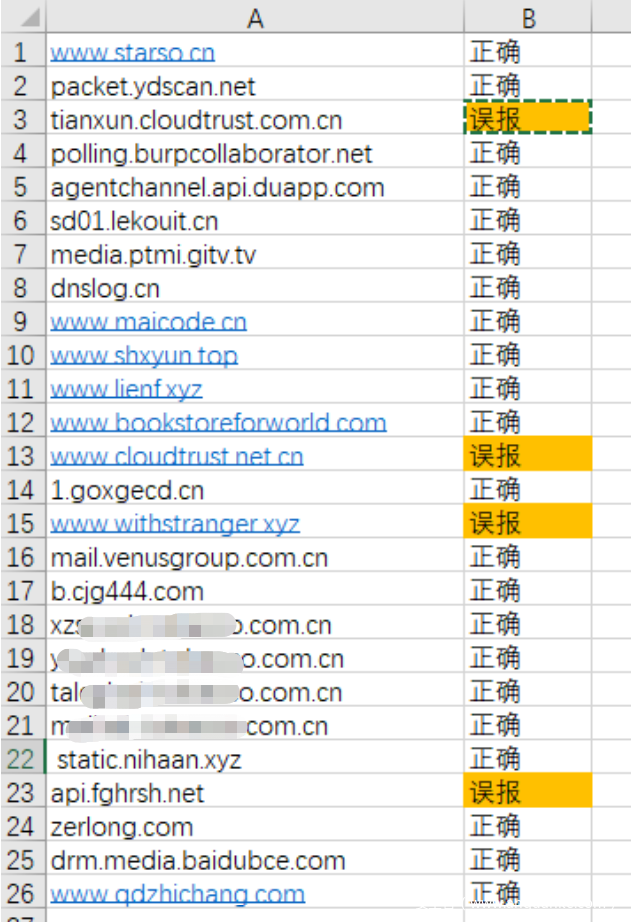
在这个26个样本的测试集,总共4条误报, 误报率15%。远高于理论值。
很多朋友在采集样本的时候,首先想到的是,我怎么能用最低的成本收集更多的样本,而很少有人去想,用这种方式采集的样本是不是随机抽样,收集的样本是否具备共同的特征。尽管任何数据集都会存在一定局限性,但这种错误无疑把这种局限性放大了,使得模型的实际指标下降严重。如果说样本采集是对真实世界的抽样,那么我们应当尽可能的保证这是个随机抽样,而不是局限在某个范围内的抽样。
特征数量水分大
特征数量不是评价模型的指标,但确实可以从侧面反映出模型的水平。有位大牛说过:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。
经常见到AI产品介绍中这样写:“本产品采集了目标的了几千个特征,详细的描述了每一个细节”。这种描述往往让人惊讶,明明不复杂的一个东西,哪来的这么多特征。嘿嘿,秘密就在于One-Hot编码上。
One-hot又称独热编码,可对特征进行扩充,提升模型的非线性能力,是神经网络最常用的编码方式。
举个例子,我们描述一个人的性别,可以用三个编码描述:[是男的, 是女的,无性别者]。命中的编码置1,其余为0。男的就是[1,0,0],女的就是[0,1,0]。这样一个特征就可以扩展为三个维度。
性别是离散型的特征,如果是连续型的数字,那么可以无限扩展。例如我们描述一个人的年龄,用一个维度足够,18岁就是[18]。那么用one-hot编码:[是不是0岁,是不是1岁,是不是2岁,… …,是不是大于100岁]。这样一个年龄特征,可以扩展成101个维度。
所以,“人”理解的特征,和给“机器”表述用的特征是有区别的,混淆两者的概念是宣传需要,应注意分辨。
说点别的
我们感受不到AI带给安全的改变,还有一个可能原因,就是传统的方案的指标本来就不低,只是以前很少用ACC AUC这些高大上的指标去评价他们,也没有人去做AI与传统方案的横向对比测试。
在有些领域,如web攻击检测,基于规则和策略的传统方案准确率也不差,却非要用AI方案再做一遍,最后准确性可能会提升了几个百分点,但是投入的研发成本却比传统方案增加了很多。如果用多投入的这些成本去优化传统的规则和策略,会不会提升效果更明显?似乎没有人做过调研,AI似乎成了目的而不是方法。总有一天,AI的热度会降下去,大家对它也会有一个客观的看法。







发表评论
您还未登录,请先登录。
登录