

前言
fuzzing技术在漏洞挖掘领域是一个无法绕开的话题,无恒实验室也一直在使用fuzzing技术发现产品的问题。虽然fuzzing不是万能的,但是没有它是万万不能的。说它不是万能的其实也是相对的说法,理想状态下,例如在可接受的时间范围内,计算资源足够丰富且系统复杂度足够低的情况下,fuzzing就能够给你任何想要的结果。这就好像是让一台计算机去随机的print一些文字,只要时间足够长,随机字符产生的效率足够快,那么早晚有一天会print出一部《三体》出来。
然而理论是丰满的,现实是骨感的,虽然人类社会的计算资源和效率在不断增长,但是软件系统的复杂度却以更快的幅度在增长着,以往通过近乎于dumb fuzz就能找到漏洞的情况几乎绝迹了。所以fuzzing技术必然要朝着更高覆盖率的样本生成、更高效的代码路径移动算法(变异)、更合理的计算资源分配调度等方向去发展。
不敢妄言未来fuzzing技术能发展到什么程度,这要靠学术界和工业界的共同努力,但是如果我们有一天见到了一个AI在面对大部分未知系统的时候都能自己solve出bug,那么毫无疑问,它一定用到了fuzzing!情怀的部分就到这里,下面来脚踏实地的实践一下安卓的一些native binary如何去fuzz。
技术背景:
fuzzing二进制目前有很多流派,但都大同小异,目的都是以最快的速度产生样本覆盖更多的code path,显然在这个过程中以code coverage作为整个fuzzer的驱动导向是最科学的,也就是覆盖率引导的灰盒模糊测试技术CGF(Coverage-based Greybox Fuzzing),这里有必要对这个最为核心的技术背景做些介绍。
统计coverage信息的方法通常有以下几种:
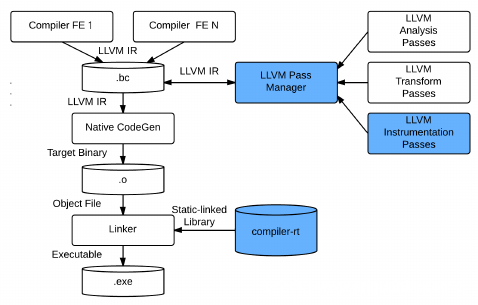
1、Compiler Instrumentation:如果存在源码的情况下,这种方式做代码覆盖率统计和fuzz是最可靠且高效的,例如利用LLVM、GCC等,但可惜很多情况下拿不到源码。
https://gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html
https://llvm.org/docs/CommandGuide/llvm-cov.html
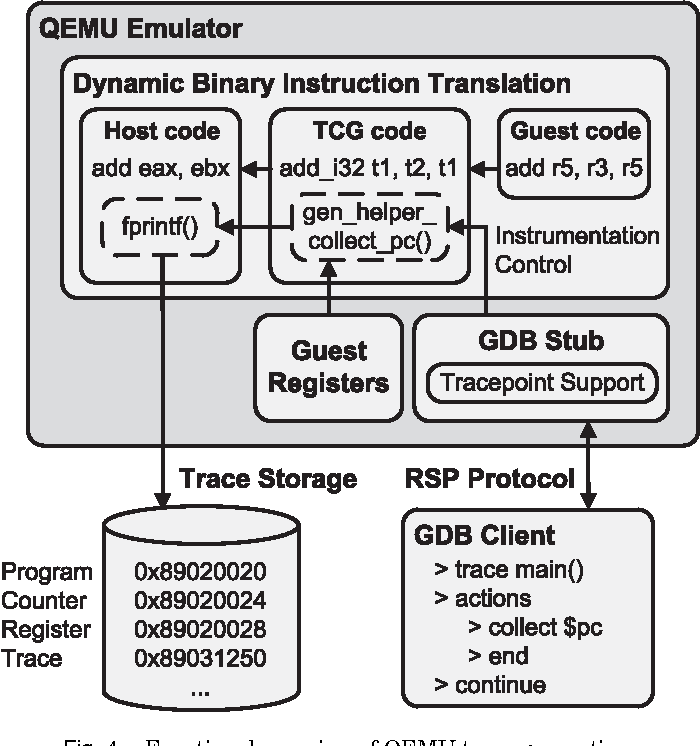
2、Execute Simulation:例如基于QEMU、Unicorn模式的AFL就会在QEMU准备翻译执行基本块之前插入覆盖率统计的代码,缺点是执行效率有点低。
https://github.com/edgarigl/qemu-etrace
https://andreafioraldi.github.io/articles/2019/07/20/aflpp-qemu-compcov.html
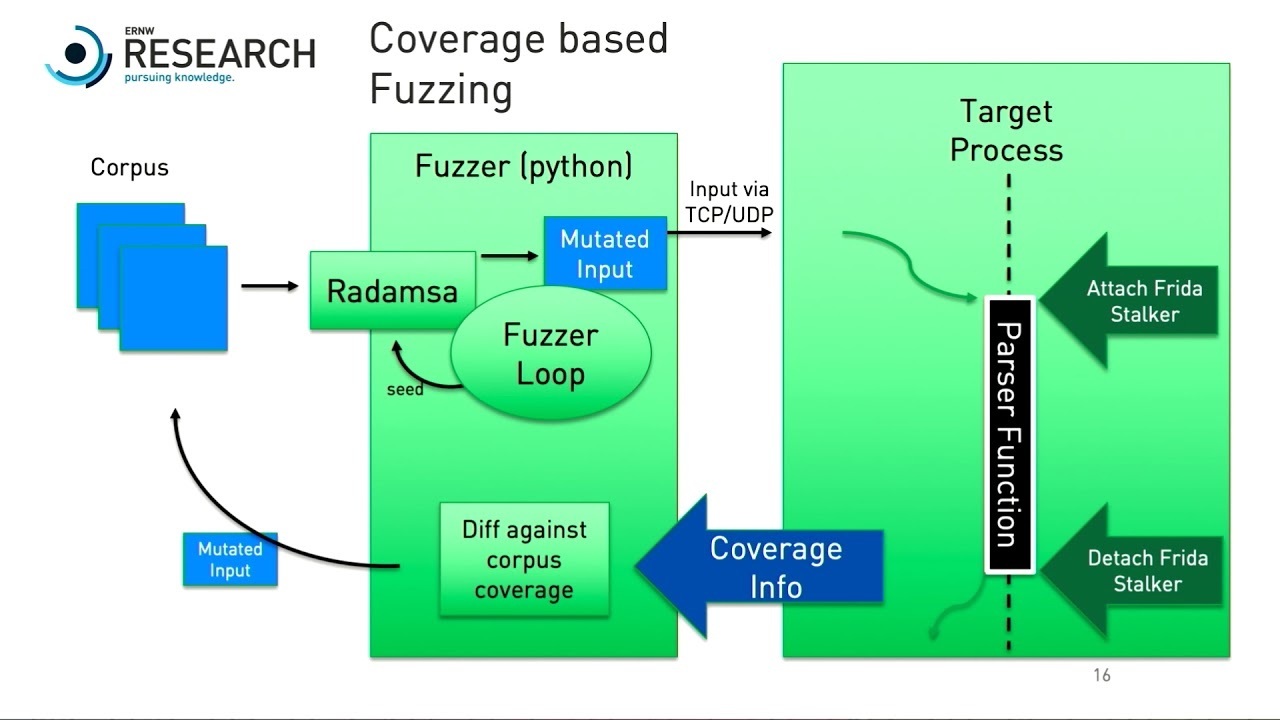
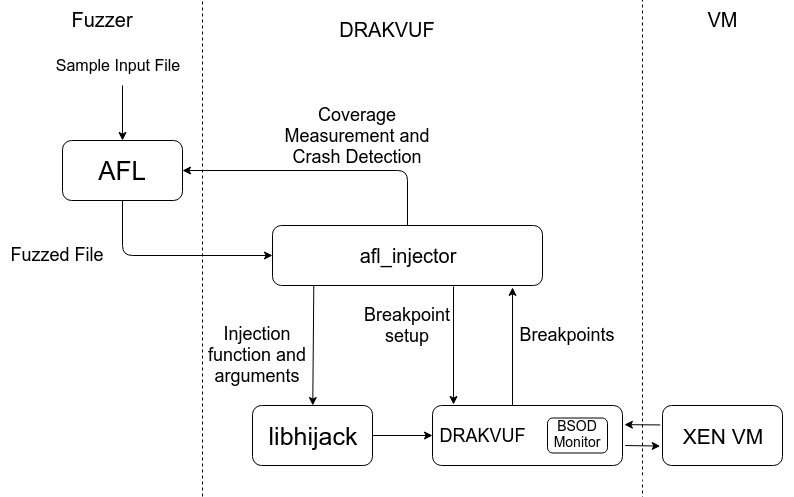
3、Runtime Trace:这种形式的代码路径覆盖比较灵活,实现形式也比较多样化,也是本文所用到的主要方法。较为常见的方式例如使用frida动态插桩、调试启动、或者直接改造手机ROM等方式都可以实现,缺点是由于架构复杂稳定性很难保证,很多时候还没等target crash,fuzzer自己先crash了。文章后面会详细一些的介绍用到的frida stalker工具。
https://frida.re/docs/stalker/
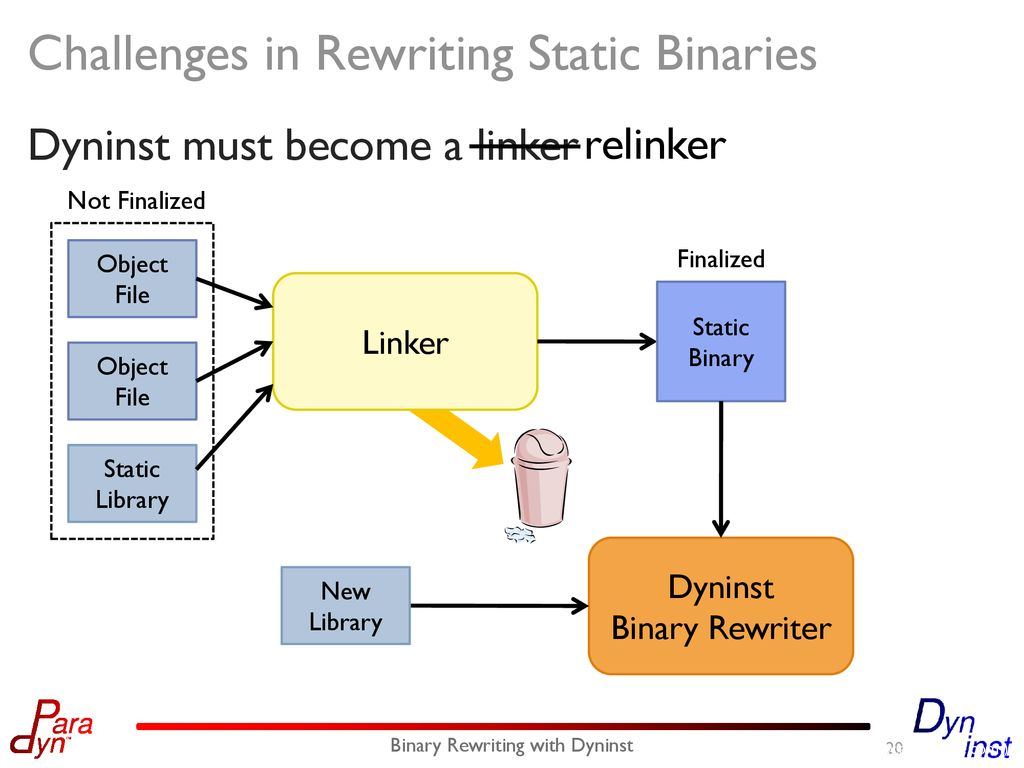
4、Binary Rewrite:这种方法主要是针对二进制disassemble的每个基本语句块进行插桩,如果做的比较理想,效果可能仅次于Compiler Instrumentation,但缺点是它太难了,如果仅仅是个比较简单的binary问题倒还不大,但如果是个复杂度很高的系统实现起来就会困难重重,例如有些binary自带VM的情况、binary存在runtime rewrite自身的机制、binary使用了一些CPU的特殊Architecture Feature、各种binary重定位问题等等,这些处理不好都会让rewriten binary无法顺利执行。
https://github.com/GJDuck/e9patch
https://github.com/utds3lab/multiverse
https://github.com/talos-vulndev/afl-dyninst
5、Hardware Trace:这可能成为未来binary fuzzing的主流方向,硬件对软件天然就处在上帝视角中,这里要明确一下我所说的Hardware Trace这个范畴,并不是真的需要搞个专用于fuzzing的硬件,这里主要是说利用硬件与操作系统之间的那一层的能力去完成fuzz的目的,这对fuzz操作系统自身尤其有效,例如利用hypervisor、硬件调试器等的能力,当然也不排除有一天会有人搞出个FPGA甚至ASIC来跑fuzz,哈哈,那简直太硬核了!
https://github.com/gamozolabs/applepie
https://the-elves.github.io/Ajinkya-GSoC19-Submission/
目标选择:
关于如何选择fuzzing目标这点,主要从安卓so库的安全风险角度分享一下我的经验和思路:

1、有攻击面:这是最先要确认的一个点,虽然理论上说任何程序都有攻击面,但是有大有小,有多有少,我们倾向于选择攻击面大的目标,这样才更有价值,例如有些so库可能会直接接收用户的外部数据进行处理,例如视频播放器、图片解析引擎、js解析引擎等等,这些so库如果出现漏洞,大概率上比较容易直接利用。
2、高频应用:更高频被用到的so库也是值得重点考量的,越是高频被用到,就越易于攻击利用,风险也就越大,例如有些工具util性质的so库,可能会被好多其他库调用,出问题的概率很大。
3、复杂度高:理论上说,漏洞的产生的概率与系统复杂度成正比,越是复杂就越是容易出问题。
4、消减措施缺失:某些so库在编译过程中可能没有考虑到安全性,没有开启安全编译选项,这就会导致其上的漏洞很容易被利用,风险也很大。
样本生成:

确认了目标以后,就要开始考虑目标的业务逻辑了,越是能清晰的了解测试目标,就越是能准确的构造出好的样本,提升fuzz的效率。这个过程就好像导弹在击中目标之前的制导过程,需要明确击中目标所要经过的各个路径和需要绕过哪些障碍等。落实到业务上就是需要了解目标会接收什么样的输入数据、对数据处理的过程是怎样的、是否需要交互、是同步还是异步等等,越准确清晰越好。例如,现在要fuzz的目标是一个视频解码引擎的H265解码算法,那么就要考虑如何去基于H265的编码算法生成一些视频样本,如果样本使用其他一些MPEG、AVS、WMV等的编码,那可能fuzz到天荒地老也未必能找出一个H265解码器的问题。
“精确制导”之后我们也需要去做一些类似“火力覆盖”的事情,因为生成一个单一样本很难做到最大化的code coverage,所以我们需要在目标接收数据范围内做一些多样性的变化,产生一个样本集,通过大量多样性的样本达到一个比较满意的代码覆盖率。
本文使用ffmpeg库对H265的视频样本进行生成,示例部分代码逻辑。
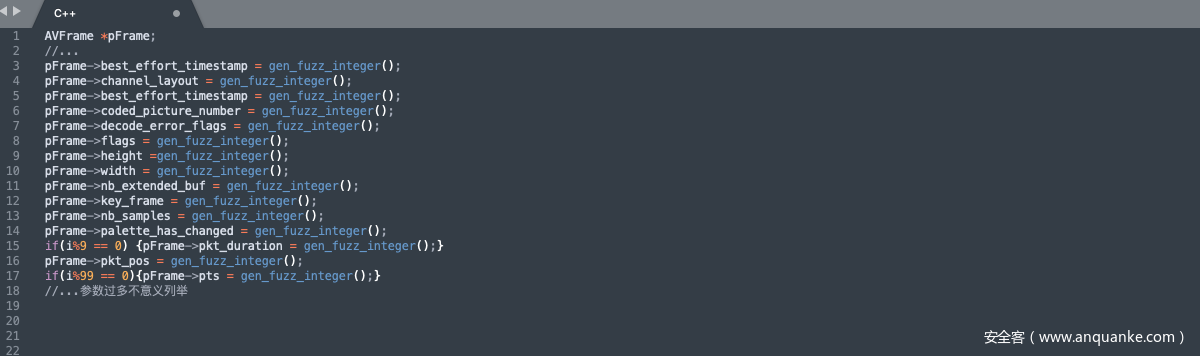
对原始帧做一些随机变化:
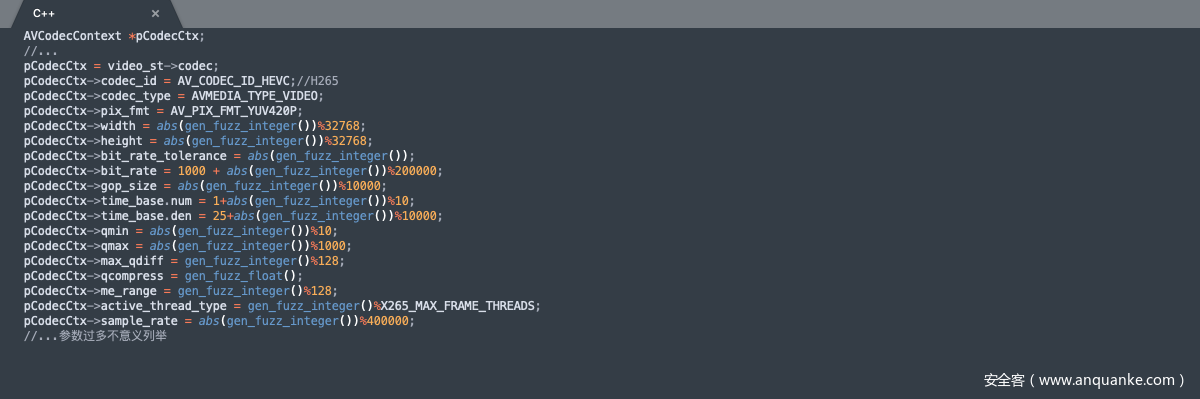
视频参数也进行些随机多样化的设置:
还可以选择性的在视频流封装前搞点事情:

这样生成出来的视频文件其实已经经过一定程度的变异,甚至可以直接fuzz出一些crash了。
覆盖率引导:
样本集有了,我们需要进行一些裁剪工作,主要根据样本对被测目标的覆盖率进行筛选,选出能够最大化coverage的最小集合,然后再对这个最小样本集进行变异,这样可以避免生成一些重复性的测试cases。
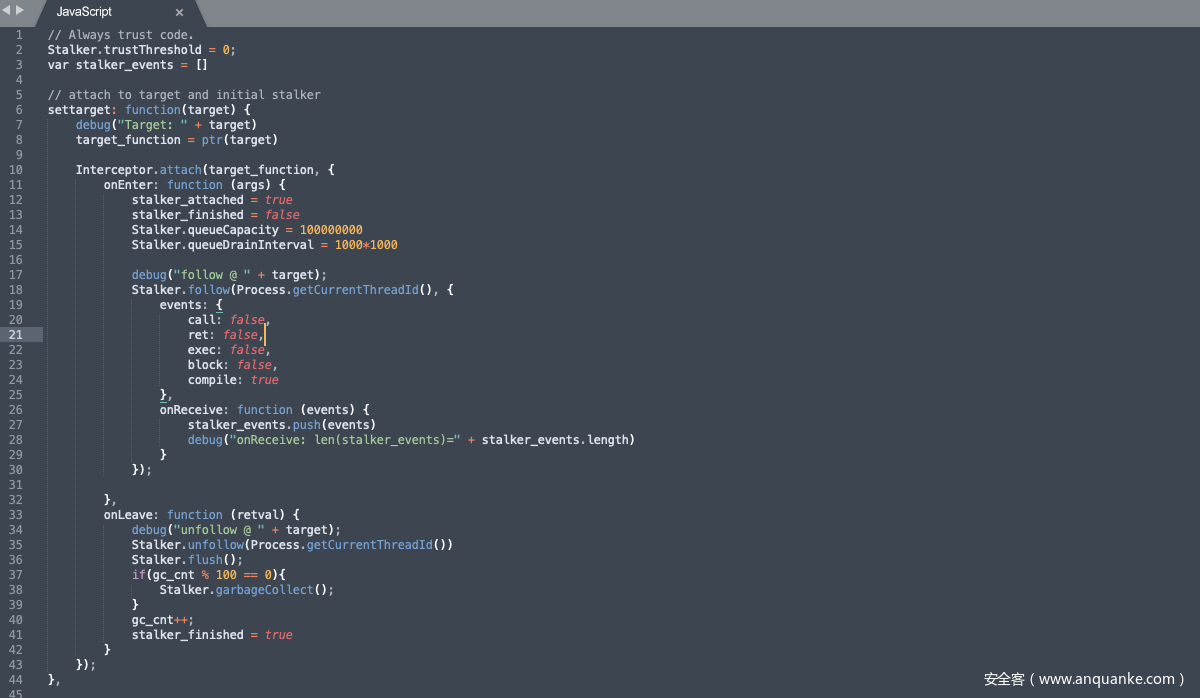
技术背景中提到过的stalker是这个环节的核心,stalker是frida系列神器的代码tracer,可以做到函数级、基本块级、指令集的代码tracing。不过这个工具之前一直对arm支持的不够好,目前frida 14.0的版本也仅支持arm64。
stalker的主要原理是dynamic recompilation,这里我们简单介绍一些stalker中的专有名词概念:
Blocks:基本块,与编译原理中的概念相同,不再赘述。
Probes:Probes就是一个基本块的桩点,如果你用过interceptor的话,他们很类似。
Trust Threshold:这个概念稍微有点绕,它实际主要是为了优化编译执行效率,但是设置它却和一些带有self-modifying功能的程序有关,例如某些加过壳或者做了anti-disassembly的binary在runtime期间会对自身的代码进行rewrite,这个过程stalker就必须要对代码重新进行dynamic recompilation,这将会是个非常耗时且麻烦的过程。所以stalker为blocks设置了一个阈值N,当blocks执行过N次之后,这个block将会被标记为可信的,以后就不会再对它进行修改了。
了解了这些概念后,继续来看一下stalker在dynamic recompilation过程中的基本操作。stalker会申请一块内存,以基本块为单位写入instrumented后的block copy并插入Probes,重定位位置相关的指令例如ADR Address of label at a PC-relative offset.,对于函数调用,保存lr相关的上下文信息,建立这个块的索引并且进行count计数,达到Trust Threshold的设定阈值的就不再进行重新编译,接下来执行一个基本块然后继续开始下一个。这个过程限于篇幅只能说个大概,实际的处理过程比较复杂,感兴趣的同学可以自行去读一下stalker的代码加深理解。

通过stalker的能力,我们可以在trace target的过程中清晰的拿到coverage,后续通过coverage来优化样本集,引导变异过程等就都很轻松了。例如我们可以通过建立bitmap的方式记录覆盖状态,根据coverage的高低来对样本进行筛选,还可以通过coverage来确定每次样本变异后的的效果等。
最后截几小段关键代码示例一下:
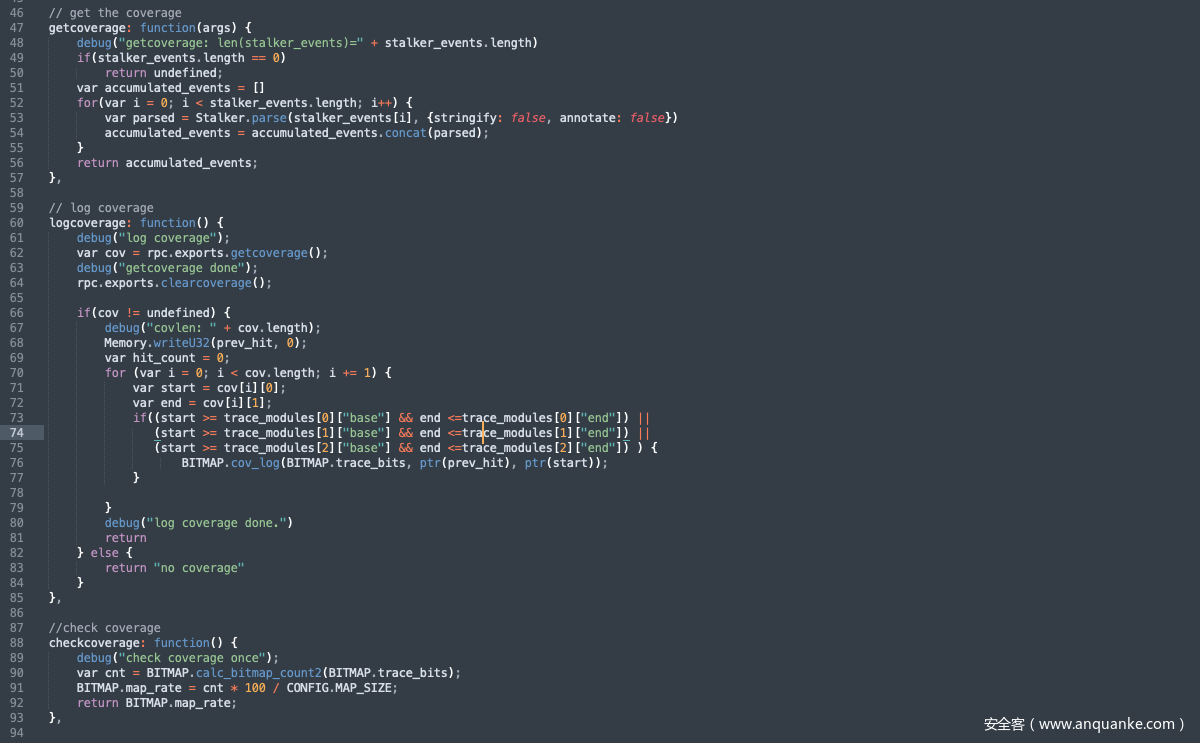
结束语:
fuzzing技术作为漏洞挖掘的经典手段,一直受到安全从业人员的喜爱,无恒实验室也一直致力于使用fuzzing技术发现产品的安全缺陷,提升产品质量。在这个过程中我们发现了大量安全性及稳定性问题,但是路漫漫其修远兮,未来无恒实验室会继续在fuzzing的智能化、高效化、精准化等方向持续投入研究,并且向业界贡献成果。
关于无恒实验室:
无恒实验室是由字节跳动资深安全研究人员组成的专业攻防研究实验室,实验室成员具备极强的实战攻防能力,研究领域覆盖渗透测试、APP安全、隐私保护、IoT安全、无线安全、漏洞挖掘等多个方向。实验室成员为字节跳动各项业务保驾护航的同时,不断钻研攻防技术与思路,发表多篇高质量论文和演讲,发现大量影响面广的0day漏洞。无恒实验室希望以最为稳妥和负责的方式降低网络安全问题对企业的影响,同时,通过实验室的技术沉淀、产品研发,致力于保障字节跳动旗下业务与产品的用户安全,让世界更加美好更加安全!
加入无恒实验室:https://security.bytedance.com/static/lab/index.html







发表评论
您还未登录,请先登录。
登录