
引言
近几年来,自动化漏洞挖掘技术成为网络安全的重要研究方向。传统的漏洞挖掘技术面临着耗时长、误报多等痛点,且无法全面地探测目标软件中的已知与未知漏洞。因此,一种简单高效的漏洞挖掘技术,即模糊测试技术,逐渐成为了研究者们关注的重点。模糊测试(Fuzzing)是一种软件漏洞自动化挖掘技术。它主要通过向目标系统注入海量非法、畸形或非预期的输入,以发现大量的软件漏洞。模糊测试技术具有自动化程度高、可用性高、误报率低,对目标程序源码没有依赖等优点。正是这些优点使其已成为软件漏洞自动化挖掘领域中最重要的技术,并被广泛应用于DevSecOps-开发安全测试领域。本文将探讨如何将灰盒Fuzzing技术应用于黑盒协议Fuzzing场景,从而大幅度提升黑盒Fuzzing的漏洞挖掘效率。
背景
常见安全问题
C/C++是目前协议栈实现使用最广泛的编程语言。出于对硬件底层、网络流的优化需求,C/C++语言在设计上更多考虑性能而非安全。因此,此类代码中容易出现一些“内存安全”问题。一类问题由程序未定义的行为导致,例如缓存区溢出漏洞;另一类由程序既定行为导致,例如整数反转导致的内存操作指针计算错误。内存安全类问题最终可能会导致类似如程序崩溃、信息泄露、任意代码执行(RCE)、权限提升(LPE)等严重安全漏洞。内存安全类问题,可以从时间和空间两个维度来分类:
空间上的内存安全类问题,例如缓冲区栈溢出、堆溢出,越界索引(OOB)等。
时间维度上的内存安全类问题,例如释放后重用(UAF)、返回后使用(UAR)、范围域外使用(use-beyond-scope)等。
从缺陷成因的维度分析,常见的内存安全问题主要由以下几点导致:
未定义的变量,其在使用时可能会泄漏一些内存信息。
指针类型错误,其偏移可能导致内存数据的非法访问或者修改。
代码逻辑错误,可能由于研发人员校验缺失、逻辑错误导致,也有可能由于编译器的错误优化导致。
尽管这种类型的安全问题有很多,但配合成熟的检测手段,利用Fuzzing测试技术在发现上述类型代码安全问题上有着奇效。
Fuzzing技术分类
Fuzzing测试可以从技术和应用场景上分为三类:基于模版生成的黑盒Fuzzing(例如Peach)、基于遗传变异和反馈的灰盒Fuzzing(例如AFL)和基于程序分析、分支约束求解的白盒Fuzzing(例如S2E)。在本文中,我们主要关注利用灰盒测试技术来优化黑盒测试流程。
灰盒 Fuzzing
灰盒Fuzzing在源代码测试领域有着广泛的应用。通常,它会在程序编译阶段对被测程序进行插桩。灰盒Fuzzing程序依据插桩后得到的反馈数据(如目标程序执行了新的执行流单元)来判断哪些变异的种子为优秀的种子。这类判定逻辑将用于指导遗传变异算法,从而可以引导测试种子向更优异的方向进行持续变异,而无需人工建模。总而言之,基于遗传变异和反馈激励的算法可以自动指导与优化测试流程,自动探索程序代码空间,并在发现漏洞时给用户提供详细的问题定位与漏洞复现功能。在测试依赖条件方面,灰盒Fuzzing首先要求被测程序在编译阶段可被插桩,从而支持丰富的程序调用监控图。其次,开源灰盒Fuzzing工具需要和被测程序运行在同一系统环境中以实现反馈获取。而在协议测试场景中,往往不具备如上的两大测试条件,从而导致灰盒协议Fuzzing在协议测试场景中具有一定的局限性。
黑盒 Fuzzing
黑盒Fuzzing技术是对测试环境依赖最少的方法,非常适合在对目标程序内部结构和特性缺乏了解的情况下进行测试。因此,这类技术在类似协议测试和仪表测试方面得到了广泛使用,并获得了优异的测试结果。黑盒协议Fuzzing的种子变异一般是基于先验证知识的,依赖于专家知识定义的协议模型或基于Wireshark等已有工具解析出的协议模型。此时,Fuzzing工具会依据模版格式生成大量畸形测试数据,再通过发包器将数据发送给被测目标。被测程序在处理这些畸形测试数据时,Fuzzing监控模块一旦发现被测程序出现了类似崩溃、无响应、超时等异常行为,那么我们就可以判定目标程序存在潜在的安全问题。黑盒协议Fuzzing工具(如Peach)仍需要大量的人工工作来定义数据模型(DataModel)和状态机模型(StateModel)。此外,通常一个协议会包含多个字段,对所有字段进行充分、递归式的测试需要大量的算力,从而导致需要大量的测试时间。因此,为了加速测试效率,程序在定义数据模型和状态及模型时必须有针对性,从而缩短漏洞发掘时间(Time-to-Explore)。这也导致黑盒协议Fuzzing非常依赖模型的完整度和对被测协议的理解深度。
技术挑战
目前的主流黑盒和灰盒Fuzzing测试技术还面临一些技术挑战。这些技术挑战限制了当下Fuzzing测试效率地提升。1. 黑盒Fuzzing无法感知程序的内部状态对于传统黑盒Fuzzing而言,测试过程依赖于专家知识设定好的状态模型。而又由于测试环境的限制,黑盒Fuzzing无法感知程序的内部状态,那即使被测程序出现了新的状态,黑盒Fuzzing也不能很好地感知并利用。这就导致测试效率低下,加大后期优化成本。2. 灰盒缺少预定义的结构化数据指导
灰盒Fuzzing可以基于程序路径反馈来调整自己的变异策略和变异算法调度,所以它不需要测试人员编写复杂的程序测试模型。此外,由于它可以细粒度地感知程序执行,容易触发一些被测程序的未定义行为或意料之外的状态转移。但由于它的测试数据生成缺失了某些特定的结构化信息,如数据模型、状态模型等先验知识,其在触发一些常规的状态转移、提升程序状态的覆盖率上存在较大的困难。另外,随着虚拟化技术、程序动态分析技术和编译器功能的发展,黑盒测试手段日渐丰富。在某些黑盒测试场景中,我们可以在黑盒中运行一个监控进程或线程,可以对黑盒中运行的程序进行插桩。因此,本文想要探讨一种方式,让黑盒的先验知识和灰盒的程序反馈优化实现互补,来提高协议测试场景下的测试效率,降低测试成本。
我们的方案
主流方法都是为已有的灰盒模糊测试工具赋予Fuzzing工具协议状态解析能力,这种方案实施相对容易,但仍存在明显问题:首先,很多黑盒协议测试场景的程序存在硬件依赖,无法运行在灰盒Fuzzing所需的标准系统中;其次,例如协议测试中,基于状态感知、状态迁移的测试,无法用灰盒Fuzzing传统的fork API的方式进行测试;最后,黑盒测试的场景中,大多需要client和server端在不同的物理机上(例如蓝牙),灰盒Fuzzing工具没有做这一类型的设计。所以我们要改变思路,在黑盒Fuzzing的测试场景下,融入灰盒Fuzzing技术。
主要策略
本文并不介绍关于如何开发黑盒与灰盒相结合的Fuzzing工具,而是介绍一种简单的思路和方法来让开源黑盒Fuzzing工具与开源灰盒Fuzzing工具可以互补使用。
一般来讲,在模糊测试领域主要使用动态插桩技术和静态插桩技术来收集程序运行时的反馈信息。动态插桩技术基于pintool、dynamorio等工具,将编译好的程序放到可控环境中执行。静态代码插桩技术可以在程序编译时进行插桩,在运行的环境中输出反馈信息,也可以对二进制程序进行静态指令改写实现插桩。
在获取黑盒中运行程序的执行路径反馈后,如何把基于反馈的遗传变异算法联系到黑盒积累的模型上呢?
对于灰盒Fuzzing而言,一段报文或者数据帧,就是一段数据。而数据中的某段偏移,可能是“有效基因片段”,其对触发程序中新的路径的执行具有决定性作用。“有效基因片段”应当被保留。如果用黑盒Fuzzing的角度去理解,“基因片段”可以对应到DataModel中的某个定义的数据字段,或者某个数据字段,例如下面这样的一个黑盒Fuzzing开源工具所使用的Model:
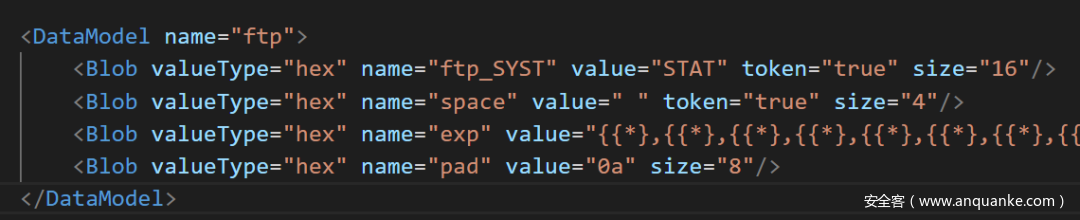
每个blob标签代表了一个可能的“基因片段”——chunk,这样黑盒Fuzzing与灰盒Fuzzing就可以建立联系。我们可以通过读取DataModel和StateModel,建立一个字典ChunkMap,其中key是不同状态State下SataModel中的最小字段名,取其名为chunkID,例如ftp_SYST、space、exp、pad等。value是利用灰盒Fuzzing的覆盖反馈发现的“interesting case”中的“有效基因片段”,名为chunkValue。上面的model中为每个chunkID赋予了一个初始值作为变异参考,但实际中,每个chunkID对应的可以作为参考的值有很多。这个字典可以用于替换黑盒Fuzzing生成的数据中的相应字段,让黑盒Fuzzing的数据在保留了结构化的同时,又能保留促使状态转移的“有效基因片段”。
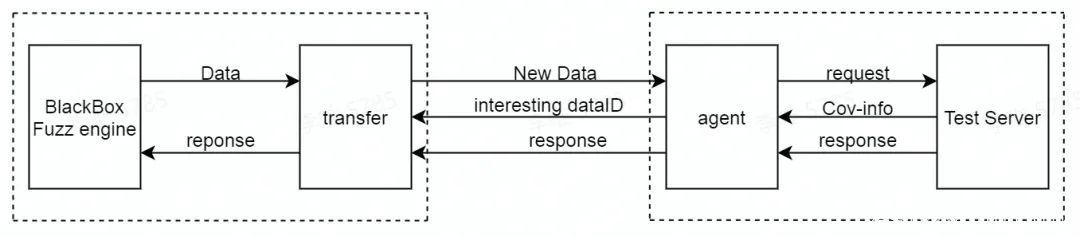
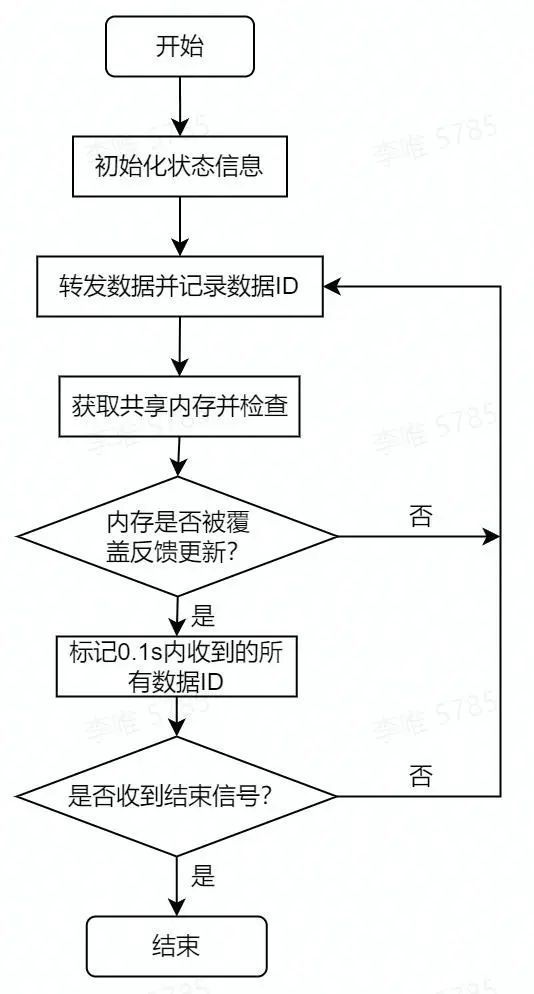
本文设计的方式是部署两个新的引擎分别称为Agent和Transfer。在黑盒测试的被测端部署Agent,测试端部署Transfer。当黑盒Fuzzing发送数据Data进行测试时,首先发送给Transfer引擎,Transfer在没有“interesting case”解析前字典ChunkMap为空,会直接发送数据Data给Agent。Agent在记录数据Data ID用于进行覆盖反馈的对应后,将数据转发给被测程序。当被测程序处理数据时,Agent会进行异步的覆盖反馈获取,当发现新的覆盖反馈时,例如Data触发执行了新的协议解析状态时,Agent返回本次Data ID给Transfer。Transfer在本地保存了一个由它发送的测试数据队列。根据Data ID从队列中找到对应的Data解析,填充字典ChunkMap。当黑盒Fuzzing再次发送数据给Transfer时,Transfer从字典ChunkMap中取出1~n个chunk,替换数据中的chunkValue,重组生成新的测试数据,发送给Agent。
如果发生异常被Agent感知,Agent同样会返回dataID来通知Transfer保存测试数据。
方案实施
DataModel字段解析
Model编写
首先,我们需要一份有效的被测对象的DataModel和StateModel,它指的是对被测对象输入数据进行建模后的模板。DataModel规定了测试数据如何生成,每个字段是什么数据类型,长度,内容或者取值范围,字段之间的关联等等。由于Peach工具已经流行了很久,实际上使用黑盒Fuzzing的同学,已经积累了一些丰富的模型。
Model解析
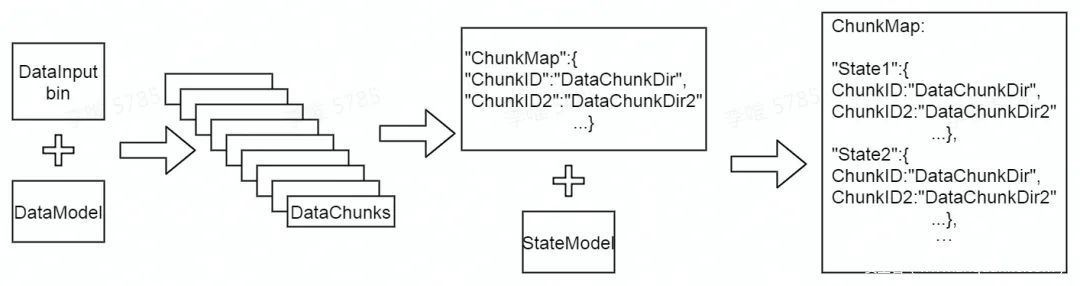
灰盒Fuzzing如果发现一个测试数据可以产生新的程序路径覆盖反馈,它会将整个测试数据直接保存,作为“interesting case”,用于下一次的变异。但是灰盒Fuzzing的变异算法是对整个测试数据的变异,这样的变异相比黑盒先验知识构成的模型的变异,缺乏效率。理想的状态是结合两种变异策略。为了能让黑盒Fuzzing基于灰盒收集到的“interesting case”进行变异,我们需要将“interesting case” ——一个二进制数据文件bin,根据DataModel和StateModel进行解析。读取灰盒输出的bin文件内容,然后根据每个字段的类型和关系的定义,逐个解析,将一个bin文件分拆成不同的片段,这些片段我们称之为chunks。不同state下,将会产生不同队列的interesting chunks。这个解析器就部署在Transfer中。
构建基于Model的chunk字典
基于上面的解析,如果一个测试数据bin为“interesting case”,Transfer就可以将该bin解析为一个个chunk,每一个chunk的ID对应于DataModel中定义好的字段名。Transfer根据chunk ID,生成了一个map——ChunkMap。该字典的键是ID,值是该chunk中的具体内容。 这样在处理了多个灰盒Fuzzing返回的interesting样本后,Transfer就拥有了一个比较丰富的map。黑盒Fuzzing变异生成的数据发送给Transfer后,如果字典不为空,Transfer会选择黑盒Fuzzing生成的数据中的特定字段,替换成map中储存的相应ID对应的值,生成一个新的包含了一个或者多个“有效基因片段”数据的测试数据。
反馈信息获取方式
黑盒与灰盒Fuzzing相结合的一个前提是我们可以对黑盒中运行的程序进行插桩,获取运行时的反馈信息。在本文中,我们选择了编译器插桩的方式,在程序中注入分支覆盖感知和反馈信息输出的功能代码,并且保证程序可以正常运行在被测端的环境中。例如开源灰盒Fuzzing工具afl++的afl-clang-fast使用的插桩函数就非常简单高效,我们可以把afl++的插桩代码编译成动态库,通过LD_PRELOAD对被测进程注入这段代码。
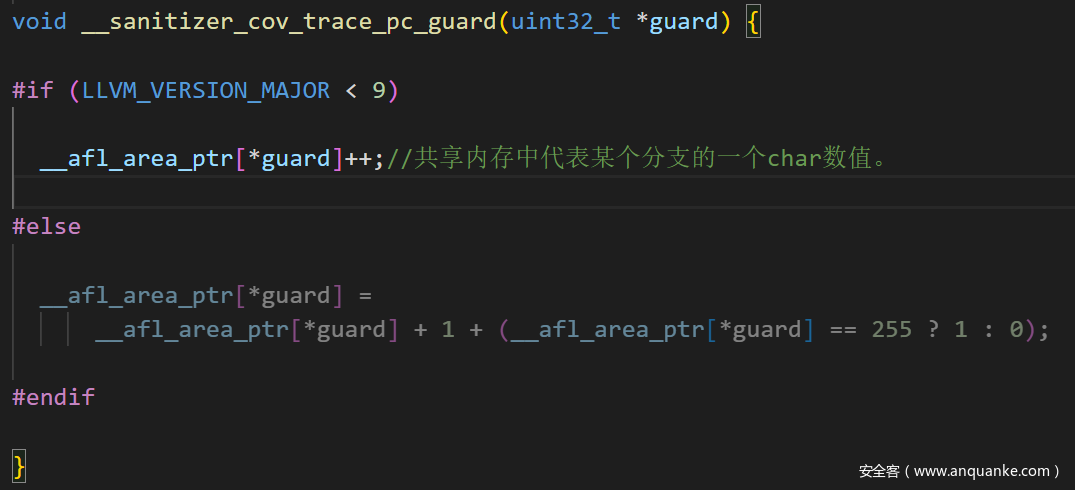
传统的灰盒Fuzzing工具,通常覆盖反馈获取与利用模块是在一个环境中的。而这种黑盒与灰盒相结合的方式,我们必须将覆盖反馈获取模块与利用模块分开,反馈获取模块部署在被测试端,反馈利用模块部署在测试端。编译器在被测程序中注入代码,被测程序在加载到内存中时,带有一段64M的“BranchMap”数据空间,BranchMap初始化为0,表示每个程序中每个branch都没有被覆盖过。 在程序执行的过程中,该BranchMap就像一个地图,会标注出程序运行到了哪些分支;当被测程序运行一个新的分支,map中的某个byte就会被加1。byte的值用来记录该branch执行次数。当然我们可以优化这里,如果内存比较小,我们可以去掉次数记录,或者进一步缩小map的空间。
反馈信息的传递
反馈的获取、“interesting case”的标记和发送靠的是我们在被测端部署的Agent引擎,它可以是一个进程或线程。测试数据实际上是Transfer通过socket发给Agent的,Agent在记录该数据的ID后,转发数据给被测程序或相应被测端口。Agent只记录最近0.1s内的数据的ID。 所以,如果该数据被Agent转发后的0.1s内(我们认为已经很长了,我们后面讲讲为什么设置这个时间阈值),BranchMap中代表分支的某一bit由0置1,Agent会将该次测试数据标注为“interesting case”,发送“interesting case”的ID给测试端Transfer;Transfer收到消息后,更新“interesting case”队列,并解析该case的bin文件,完善chunkMap。
解决反馈同步问题
黑盒Fuzzing测试即便不融入灰盒Fuzzing的覆盖反馈,但在实际操作中会面临一问题,Fuzzing端发送的测试数据与被测端程序的反应无法对应起来。
传统黑盒Fuzzing时,如果某个测试数据触发了一个栈耗尽问题,栈在被耗尽之前,被测程序并不会立刻崩溃,还会继续从队列中拿取测试数据,被测程序依然可以正常响应,并处理黑盒Fuzzing发来的其他数据。等到monitor检测到StackOverflow导致的崩溃后,此时被测程序可能已循环处理了数十条测试数据,无法锁定哪个数据触发了问题。Fuzzing结果与测试数据无法做到完美的对应,那么覆盖反馈的触发与数据对应也存在同样问题。
传统的灰盒Fuzzing可以做到反馈与数据的对应是因为灰盒Fuzzing引擎通过父进程fork、attach或者人工定义的方式,掌握了程序处理数据的整个循环。引擎会等待处理数据的整个循环执行完成后,再发送新的测试数据;这样数据与反馈永远可以对应起来。学术界一些灰+黑的Fuzzing工具,例如AFLNet同样遵从以上方法,等到被测端返回消息后,再发送下次数据。但是,这就有个问题:很多情况下,被测端在解析了畸形报文后,并不会返回消息,这就必须设置一个等待的时间阈值。这样的等待会大大削弱黑盒Fuzzing的测试速度,得不偿失。
于是我们的方案是让Agent分阶段来实施整个策略。只要BranchMap有刷新,我们就会储存过去0.1s中内发送的所有测试数据及根据StateModel的测试数据序列。
在一段时间cov没有更新以后,我们进入“洗牌”模式。我们将初始化bitmap,并将记录的“interesting case”根据记录的state,倒着重发一遍,并对没有产生新的数据设置1s的阈值;如果在这个时间内,没有触发BranchMap,则将该“interesting case”删除。
在处理完这批数据后,Transfer才会根据保留的数据生成chunkMap。chunkMap会在新一轮的测试中使用。
实验测试
定制编译器部署
以ubuntu-20.04为例:apt update && apt install clang -y,然后假定你的灰盒Fuzzing工具使用afl++,进入afl++引擎代码路径执行CC=clang CXX=clang make && make install,验证afl-clang是否安装成功:afl-clang-fast —version
使用afl-clang-fast编译被测代码,这里以bluez为被测对象:./bootstrap && CC=afl-clang-fast CXX=afl-clang-fast++ ./configure && make,可以看到插桩过程:
实际上,AFL的插桩简单粗暴。我们并不太想对开源工具改动太大,所以依然只是用afl的插桩,也可以实现我们的需求。 另外如果在这里,我们设置一个静态局部变量,并在这里对bitmap进行初始化,开启监控线程,是否可以呢?我们之后再验证和讨论这个问题。
部署Agent
我们还用afl来举例,简单修改了afl的代码,使得在Agent模式下,afl只初始化bitmap并根据bitmap中是否有新的bit置位,来给测试端发送反馈信息。
这里需要注意的是,通常来讲,Agent端还有端口转发的功能。但是我们的例子bluez蓝牙协议栈有些特殊,属于空口协议,且蓝牙模块无法实现与自身配对,同时完成发包和收包。所以Agent只负责收集覆盖信息,发送数据由测试端发送。注入这段代码用LD_PRELOAD注入一个hook main函数的库就可以。检查bitmap是否更新的函数依然使用afl的“has_new_bits”稍作修改就好了,这里篇幅所限就不粘贴代码了。afl-fuzz —Agent ./bluetoothd -P 80此时,被测端相关工作已经部署完毕。
测试端准备工作
复用黑盒Peach工具Fuzzing时的DataModel和StateModel以及Publisher。使用我们修改过的afl来解析DataModel并生成map.json:afl-fuzz —tranfer init ./bluez.xml -o ./map/
启动Peach server进行Fuzzing
我们使用开源的Peach代码进行测试,添加了—transport选项来将每一个输出数据发送给Transfer,也是我们修改过的afl-server。一般情况下,afl-server会直接将变异完的数据进行转发。由于蓝牙数据传输的特殊性,需要特定的publisher,所以afl-server只起到数据解析和chunk字典生成的功能。数据依然由Peach注册的Publisher进行发送。 “—afldict”指定了Peach变异后需要替换的字典的路径。”—engine”指定了进行解析和与Agent交互的Transfer。
启动测试
peach —afldict ../aflcustom/map/map.json —engine ./Transfer example/bluez.xml
结果评估
限于篇幅原因,本文仅介绍了黑盒、灰盒融合的一些思路,对于测试的结果和新的优化方法,我们将在之后的文章中分享。







发表评论
您还未登录,请先登录。
登录