
前言
本文主要依据NFAs with Tagged Transitions, their Conversion to Deterministic Automata and Application to Regular Expressions Ville Laurikari Helsinki University of Technology Laboratory of Computer Science PL 9700, 02015 TKK, Finland vl@iki.fi这篇论文以及re2c自身代码进行描述。
EXP抽象化
re2c的抽象化过程和我们程序分析理论中的内容有很高的一致性。首先是最基本的结构单元EXP。每一句代码都是EXP,而这些EXP往往可以进一步分解:如123+234,在程序分析理论的结构上的操作语义部分,我们提出了这样的分析方法:A[a1 opa a2]σ = A[a1]σ opa A[a2]σ。这里也是一样,同时还增加了实际分析的细节:首先,我们将123+234整个EXP转换成EXP+EXP。随后对第一个EXP进行同样的分解。由于123不包含op所以转换成VAR。对于VAR我们进行按位读取识别:将第一位和后续分开。第一位看作DGT,后续看作新的VAR。直到将123全部识别。随后对234进行同样的操作。
即
EXP->EXP+EXP->VAR+EXP->1 VAR +EXP ->12 VAR +EXP ->123+EXP->123+VAR->123+2 VAR->123+23 VAR ->123+234
NFA自动机
NFA Nondeterministic Finite Automaton 非确定有限状态自动机
有限状态自动机。首先对状态进行定义,状态是自动机每一次处理信号的结果,每一次接收信号后会进入新的状态,这个状态可能是循环状态(处理信号后之前的处理机制依旧适用),也可能是下一个状态(已经不适用于相同状态的处理,需要进入新的状态,应用新的处理机制)
要实现上面所描述的状态,需要进行相应的运算,对于应用新的处理机制的运算为组合运算,用RS表示。对于依旧使用当前机制的运算为重复运算,用R^*表示。除此之外,还有替换运算:从当前状态转换到下一状态可以应用两种不同的处理机制,比如说一个EXP可以处理成VAR,也可能是一个函数的调用。用R|S表示。
DFA自动机
DFA Deterministic Finite Automaton 确定有限状态自动机
其确定性在于该模型用于解决已知字符串是否满足自动机设置。即满足条件就继续否则退出,这种是就是是不是就是不是的设置使得自动机只存在一条路径,不会出现R|S的运算。这不代表DFA自动机一次只能应用一种处理机制,DFA自动机和NFA自动机实际可以相互转化,DFA自动机每一个状态的处理机制是NFA相对应处理机制的集合。
即对于下面一个NFA自动机,我们可以转换成如图二所示的DFA自动机
图一
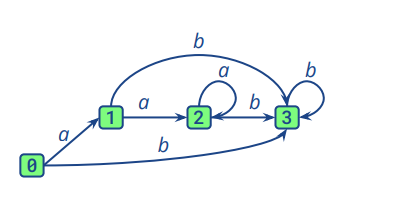
图二
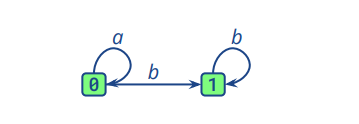
图二中的0包含图一中的0,1,2:在接收初始状态时,进入NFA的0,也就是DFA中的0(0)。接收到a则进入NFA的1,也就是DFA中的0(1)。接收到b则直接进入NFA的3,也就是DFA的1(3)。其余部分相似。所以DFA的处理机制是NFA处理机制的集合。
TNFA自动机
NFA with tagged transitions就是在NFA的基础上加上了tag元素,用于记录自动机处理过程。
也就是TNFA不仅包含NFA中有的有限个状态,有限个符号,运算关系,初始状态,结束状态,还包含有限个标签。
在处理一个输入时,首先接收前,自动机处于上一个状态,接收输入时,设置tag在当前处理机制,进入下一个状态
虽然加上了Tag,但是NFA的不确定性依旧存在,所以我们要把TNFA转换成DA deterministic automata。
首先,我们要找到初始状态,根据TNFA的处理机制确定TDFA的初始状态。再根据所有的处理机制,将处理机制进行分类集合,形成TDFA的处理机制。最后确定退出状态。
TDFA自动机
同样的TDFA是加上了tag的DFA。
相较于TNFA,TDFA不仅包含有限个状态,有限个符号,初始状态,最终状态,还包含过度函数,初始化和终止化。
tag的作用
当我们想要匹配[0-9][a-z]\的时候,在[0-9]和[a-z]之间的处理机制的转换在没有tag的时候不能明确标识出来。加入tag后,我们不再需要通过检测到非[0-9]切换处理机制,再重复读取该非[0-9]的信号。
当然,tag的添加不具有唯一性,比如正则表达式为(a|b)t_0 b (a|b)\的处理机制,对于abba信号,t_0可以标记在第一个a后面,也可以标记在第一个b后面。为此,我们添加一项原则使得tag唯一。对于包含重复处理机制的匹配,我们尽可能的多去实现重复,也就是说,除非当前处理机制不能应用,或者应用当前匹配机制后无法继续匹配,否则使用当前处理机制。
例子
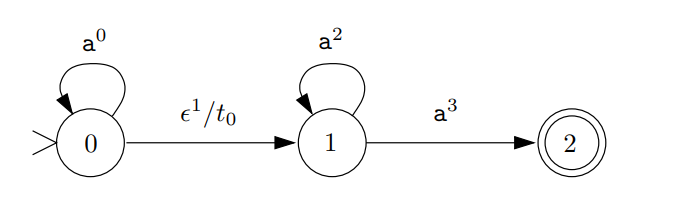
0是初始状态,接收信号后,可能应用同样的处理机制或者进入下一状态。所以TDFA的初始状态也是0.
状态1可能使用同样的处理机制也可能进入状态2,而状态2是TNFA的终止状态,所以对于TNFA的1,2是TDFA的1,也是TDFA的终止状态。除此之外,TDFA具有终止化操作,即对于进入TDFA的1(2)后,会退出程序。同样的,在TDFA的初始状态0中,会包含初始化达到使用新的处理机制进入程序的作用。其中,过度函数就是应用处理机制时记录标签从而达到记录执行过程的作用。
伪代码实现
对于一个状态t,进行a处理
对于任意状态u->u’之间存在a处理,则添加到链表中。
reach(t,a)
for u->u’ == a : r = r + (u’ , k)
当前状态所有可能的处理机制进行遍历,找到进入其他状态的最短路径。
t_closure
for (u , k) ∈ S (:push(u,0,k) 😉
init closure
while stack (: pop(s,p,k) ; for s -> u (: if tag (: remove ; add )
if (u,p’,k’) ∈ closure and p < p’ (: remove (u,p’,k’) 😉 if (u,p.k) not ∈
closure : (add(u,p,k) ; push (u,p,k))))
将TNFA转换成TDFA
for map item : add map item to init ; signal map item
while signal map item : unsignal signal item ; for symbol : u <- t_closure(reach(t,a)) ; c <- list ;for map item in u : if map item not in k : add map item to c ; if u -> u’ == R : add R to c ; else signal u’ ; t = u’ ; c = a ; if u’ == final : finish ;
伪代码执行流程:
将当前状态的处理机制保存到链表中,将所有保持0状态的处理机制添加到初始化部分。接收信号,将所有能够处理a信号的处理机制添加到新的链表中,并且将该链表中的处理机制进行筛选,找到能够跳转的最短的应用链群。将跳转的状态和使用的处理机制链记录,重复上述步骤处理新的状态直到进入终止状态。
代码分析
import qualified Test.QuickCheck as Q
import qualified Test.QuickCheck.Monadic as QM
import qualified System.Process as SP
import qualified System.Exit as SE
import qualified Data.ByteString.Char8 as BS
import Data.Char (ord)
import qualified Text.Regex.TDFA as X
import qualified Data.Array as A
import Control.Monad (when)
data E = A | B | C
| Empty
| NA | NB | NC
| Alt E E
| Cat E E
| Star E
| Plus E
| Mayb E
| FromTo Int Int E
| From Int E
instance Show E where
show x = case x of
A -> "[a]"
B -> "[b]"
C -> "[c]"
Empty -> "(\"\")"
NA -> "[^a]"
NB -> "[^b]"
NC -> "[^c]"
-- Alt l r -> show l ++ "|" ++ show r
Alt l r -> "(" ++ show l ++ "|" ++ show r ++ ")"
-- Cat l r -> show l ++ show r
Cat l r -> "(" ++ show l ++ show r ++ ")"
Star e -> "(" ++ show e ++ ")*"
Plus e -> "(" ++ show e ++ ")+"
Mayb e -> "(" ++ show e ++ ")?"
FromTo n m e -> "(" ++ show e ++ "){" ++ show n ++ "," ++ show m ++ "}"
From n e -> "(" ++ show e ++ "){" ++ show n ++ ",}"
show_posix :: E -> String
show_posix x = case x of
A -> "[a]"
B -> "[b]"
C -> "[c]"
Empty -> "()"
NA -> "[^a]"
NB -> "[^b]"
NC -> "[^c]"
-- Alt l r -> show_posix l ++ "|" ++ show_posix r
Alt l r -> "(" ++ show_posix l ++ "|" ++ show_posix r ++ ")"
-- Cat l r -> show_posix l ++ show_posix r
Cat l r -> "(" ++ show_posix l ++ show_posix r ++ ")"
Star e -> "(" ++ show_posix e ++ ")*"
Plus e -> "(" ++ show_posix e ++ ")+"
Mayb e -> "(" ++ show_posix e ++ ")?"
FromTo n m e -> "(" ++ show_posix e ++ "){" ++ show n ++ "," ++ show m ++ "}"
From n e -> "(" ++ show_posix e ++ "){" ++ show n ++ ",}"
instance Q.Arbitrary E where
arbitrary = do
d <- Q.choose (2,4) :: Q.Gen Int
arbitrary_d d
arbitrary_d :: (Enum a, Eq a, Num a) => a -> Q.Gen E
arbitrary_d 0 = do
Q.frequency
[ (1, pure Empty)
, (1, pure A)
, (1, pure B)
, (1, pure C)
, (1, pure NA)
, (1, pure NB)
, (1, pure NC)
]
arbitrary_d d = do
n <- Q.choose (0,1) :: Q.Gen Int
m <- Q.choose (if n == 0 then 1 else n, 3) :: Q.Gen Int
Q.frequency
[ (1, pure Empty)
, (1, pure A)
, (1, pure B)
, (1, pure C)
, (1, pure NA)
, (1, pure NB)
, (1, pure NC)
, (30, Alt <$> arbitrary_d d' <*> arbitrary_d d')
, (30, Cat <$> arbitrary_d d' <*> arbitrary_d d')
, (10, Star <$> arbitrary_d d')
, (10, Plus <$> arbitrary_d d')
, (10, Mayb <$> arbitrary_d d')
, (10, FromTo n m <$> arbitrary_d d')
, (10, From n <$> arbitrary_d d')
]
where d' = pred d
parse_input :: Int -> IO [(BS.ByteString, [Int], [BS.ByteString], X.MatchArray)]
parse_input ncaps = do
let step :: BS.ByteString -> BS.ByteString -> (BS.ByteString, [Int], [BS.ByteString], X.MatchArray, BS.ByteString)
step input key =
let ns'@(n1:n2:_:ns) = reverse $ BS.foldl' (\xs c -> ord c : xs) [] key
s = BS.take n2 input
ss = split ns s
ar = A.listArray (0, ncaps) (split2 ns s)
rest = BS.drop n1 input
in (s, ns', ss, ar, rest)
go :: [BS.ByteString] -> BS.ByteString -> [(BS.ByteString, [Int], [BS.ByteString], X.MatchArray)]
go [] _ = []
go (key:keys) input =
let (s, ns, ss, ar, rest) = step input key
in (s, ns, ss, ar) : go keys rest
split :: [Int] -> BS.ByteString -> [BS.ByteString]
split [] _ = []
split (n1:n2:ns) s = (BS.drop n1 . BS.take n2) s : split ns s
split _ _ = error "uneven number of keys"
split2 :: [Int] -> BS.ByteString -> [(Int, Int)]
split2 [] _ = []
split2 (n1:n2:ns) s = case (n1, n2) of
(255, 255) -> (-1, 0) : split2 ns s
_ | n1 /= 255 && n2 /= 255 -> (n1, n2 - n1) : split2 ns s
_ -> error $ "bad re2c result: " ++ show (n1, n2)
split2 _ _ = error "uneven number of keys"
split_at :: Int -> BS.ByteString -> [BS.ByteString]
split_at _ s | s == BS.empty = []
split_at n s | BS.length s < n = error "bad tail"
split_at n s = BS.take n s : split_at n (BS.drop n s)
ncaps' = 2 * (ncaps + 1) + 3
input <- BS.readFile "a.c.line1.input"
keys <- split_at ncaps' <$> BS.readFile "a.c.line1.keys"
return $ go keys input
prop_test_re2c :: E -> Q.Property
prop_test_re2c r1 = QM.monadicIO $ do //读取输入流
let portable_empty = "[a]{0}"
re_file = "/*!re2c " ++ show r1 ++ "|" ++ portable_empty ++ " {} */" //show函数
re_posix = "^" ++ show_posix r1 ++ "|" ++ portable_empty //show_posix
rr = X.makeRegex re_posix :: X.Regex //正则匹配
ncaps = length $ filter (== '(') re_posix
re2c = "../re2c"
ok0 <- QM.run $ do
BS.writeFile "a.re" $ BS.pack re_file
SP.system $ "ulimit -t 10 && " ++ re2c
++ " --posix-captures -Werror-undefined-control-flow -ST a.re -o a.c 2>>re2c_last_warning"
++ " || exit 42 && gcc a.c -o a && ./a"
QM.assert $ ok0 `elem` [SE.ExitSuccess, SE.ExitFailure 42]
when (ok0 == SE.ExitFailure 42) $ do
QM.run $ print re_posix
when (ok0 == SE.ExitSuccess) $ do
ss <- QM.run $ parse_input ncaps
mapM_ (\(s, ns, xs, ar) -> do
let s1 = map BS.unpack xs
s2 = ((\x -> if x == [] then [] else head x) . X.match rr . BS.unpack) s
ar' = (X.match rr . BS.unpack) s :: X.MatchArray
ok = (ar == ar' && s1 == s2) || (BS.filter (== '\n') s) /= BS.empty
QM.run $ when (not ok) $ do
print re_posix
print ncaps
print $ BS.unpack s
print ns
print s1
print s2
print ar
print ar'
QM.assert ok
) ss
main :: IO ()
main = Q.quickCheckWith Q.stdArgs { Q.maxSuccess = 1000000 } prop_test_re2c
获取re2c结构的表达式,转换成规则,为后续分析进行匹配。
parse.cc 基于 bison
static const char *const yytname[] =
{
"$end", "error", "$undefined", "TOKEN_COUNT", "TOKEN_ERROR",
"TOKEN_REGEXP", "'|'", "'*'", "'+'", "'?'", "'('", "')'", "$accept",
"regexp", "expr", "term", "factor", "primary", YY_NULLPTR
};
#define yyerrok (yyerrstatus = 0)
#define yyclearin (yychar = YYEMPTY)
#define YYEMPTY (-2)
#define YYEOF 0
#define YYACCEPT goto yyacceptlab
#define YYABORT goto yyabortlab
#define YYERROR goto yyerrorlab
switch (yyn)
{
case 2:
#line 51 "../lib/parse.ypp" /* yacc.c:1651 */
{ regexp = (yyval.regexp); }
#line 1244 "lib/parse.cc" /* yacc.c:1651 */
break;
case 4:
#line 55 "../lib/parse.ypp" /* yacc.c:1651 */
{ (yyval.regexp) = ast_alt((yyvsp[-2].regexp), (yyvsp[0].regexp)); }
#line 1250 "lib/parse.cc" /* yacc.c:1651 */
break;
case 6:
#line 60 "../lib/parse.ypp" /* yacc.c:1651 */
{ (yyval.regexp) = ast_cat((yyvsp[-1].regexp), (yyvsp[0].regexp)); }
#line 1256 "lib/parse.cc" /* yacc.c:1651 */
break;
case 8:
#line 65 "../lib/parse.ypp" /* yacc.c:1651 */
{ (yyval.regexp) = ast_iter((yyvsp[-1].regexp), 0, AST::MANY); }
#line 1262 "lib/parse.cc" /* yacc.c:1651 */
break;
case 9:
#line 66 "../lib/parse.ypp" /* yacc.c:1651 */
{ (yyval.regexp) = ast_iter((yyvsp[-1].regexp), 1, AST::MANY); }
#line 1268 "lib/parse.cc" /* yacc.c:1651 */
break;
case 10:
#line 67 "../lib/parse.ypp" /* yacc.c:1651 */
{ (yyval.regexp) = ast_iter((yyvsp[-1].regexp), 0, 1); }
#line 1274 "lib/parse.cc" /* yacc.c:1651 */
break;
case 11:
#line 68 "../lib/parse.ypp" /* yacc.c:1651 */
{ (yyval.regexp) = ast_iter((yyvsp[-1].regexp), (yyvsp[0].bounds).min, (yyvsp[0].bounds).max); }
#line 1280 "lib/parse.cc" /* yacc.c:1651 */
break;
case 13:
#line 73 "../lib/parse.ypp" /* yacc.c:1651 */
{ (yyval.regexp) = ast_cap(ast_nil(NOWHERE)); }
#line 1286 "lib/parse.cc" /* yacc.c:1651 */
break;
case 14:
#line 74 "../lib/parse.ypp" /* yacc.c:1651 */
{ (yyval.regexp) = ast_cap((yyvsp[-1].regexp)); }
#line 1292 "lib/parse.cc" /* yacc.c:1651 */
break;
#line 1296 "lib/parse.cc" /* yacc.c:1651 */
default: break;
}
将分析之后的结构插入AST中
lex.cc
if (yych <= '>') {
if (yych <= '\'') {
if (yych <= 0x00) goto yy2;
if (yych == '$') goto yy6;
goto yy4;
} else {
if (yych <= '+') goto yy8;
if (yych == '.') goto yy10;
goto yy4;
}
} else {
if (yych <= ']') {
if (yych <= '?') goto yy8;
if (yych == '[') goto yy12;
goto yy4;
} else {
if (yych <= 'z') {
if (yych <= '^') goto yy6;
goto yy4;
} else {
if (yych <= '{') goto yy14;
if (yych <= '|') goto yy8;
goto yy4;
}
}
}
根据特殊符号进行不同跳转
yy2 遇到空格之类的处理下一个字符
yy2:
++cur;
#line 42 "../lib/lex.re" //nil { return 0; }
{ return 0; }
#line 103 "lib/lex.cc" //yy4 ++cur
yy6 获取变量
yy6:
++cur;
#line 46 "../lib/lex.re" /*[$^] {
error("anchors are not supported");
return TOKEN_ERROR;
}*/
{
error("anchors are not supported");
return TOKEN_ERROR;
}
#line 123 "lib/lex.cc" //yy8
yy8遇到()|*+?则变量名匹配结束。
yy8:
++cur;
#line 44 "../lib/lex.re" //[()|*+?] { return cur[-1]; }
{ return cur[-1]; }
#line 128 "lib/lex.cc" //yy10
yy10遇到 . 插入AST
yy10:
++cur;
#line 72 "../lib/lex.re" // .
{
yylval.regexp = ast_dot(NOWHERE);
return TOKEN_REGEXP;
}
#line 136 "lib/lex.cc" //yy12
yy12
yy12:
yych = *++cur;
if (yych == '^') goto yy15;
#line 52 "../lib/lex.re" // [
{ goto cls; }
#line 142 "lib/lex.cc" //yy14
yy14 获取数字
yy14:
yych = *(mar = ++cur);
if (yych <= '/') goto yy5;
if (yych <= '9') {
yyt1 = cur;
goto yy17;
}
goto yy5;
yy17 获取数字
yy17:
yych = *++cur;
if (yybm[0+yych] & 128) {
goto yy17;
}
if (yych == ',') goto yy20;
if (yych == '}') goto yy21;
其他的逻辑也是类似一个字符一个字符分析进行跳转。
compile.cc
static smart_ptr<DFA> ast_to_dfa(const spec_t &spec, Output &output)
{
const opt_t *opts = output.block().opts;
const loc_t &loc = output.block().loc;
Msg &msg = output.msg;
const std::vector<ASTRule> &rules = spec.rules;
const std::string
&cond = spec.name,
name = make_name(output, cond, loc),
&setup = spec.setup.empty() ? "" : spec.setup[0]->text;
RangeMgr rangemgr;
RESpec re(rules, opts, msg, rangemgr);
split_charset(re);
find_fixed_tags(re);
insert_default_tags(re);
warn_nullable(re, cond);
nfa_t nfa(re);
DDUMP_NFA(opts, nfa);
dfa_t dfa(nfa, spec.def_rule, spec.eof_rule);
determinization(nfa, dfa, opts, msg, cond);
DDUMP_DFA_DET(opts, dfa);
rangemgr.clear();
// skeleton must be constructed after DFA construction
// but prior to any other DFA transformations
Skeleton skeleton(dfa, opts, name, cond, loc, msg);
warn_undefined_control_flow(skeleton);
if (opts->target == TARGET_SKELETON) {
emit_data(skeleton);
}
cutoff_dead_rules(dfa, opts, cond, msg);
insert_fallback_tags(opts, dfa);
// try to minimize the number of tag variables
compact_and_optimize_tags(opts, dfa);
DDUMP_DFA_TAGOPT(opts, dfa);
freeze_tags(dfa);
minimization(dfa, opts->dfa_minimization);
DDUMP_DFA_MIN(opts, dfa);
// find strongly connected components and calculate argument to YYFILL
std::vector<size_t> fill;
fillpoints(dfa, fill);
// ADFA stands for 'DFA with actions'
DFA *adfa = new DFA(dfa, fill, skeleton.sizeof_key, loc, name, cond,
setup, opts, msg);
// see note [reordering DFA states]
adfa->reorder();
// skeleton is constructed, do further DFA transformations
adfa->prepare(opts);
DDUMP_ADFA(opts, *adfa);
// finally gather overall DFA statistics
adfa->calc_stats(output.block());
// accumulate global statistics from this particular DFA
output.max_fill = std::max(output.max_fill, adfa->max_fill);
output.max_nmatch = std::max(output.max_nmatch, adfa->max_nmatch);
if (adfa->need_accept) {
output.block().used_yyaccept = true;
}
return make_smart_ptr(adfa);
}
ast转DFA
将AST内容拆分,添加标签,生成NFA,输出NFA,转换成DFA,添加回溯标签,寻找最简DFA
最后
代码部分分析只是草草带过,依旧有很多不足。如果有什么问题,欢迎指教。







发表评论
您还未登录,请先登录。
登录