

前言
现在机器学习即服务(Machine Learning as a Service,MLaaS)是非常热门的,很多大厂都把自己的模型开放作为其云平台的一项服务,国外的Google,Amazon,国内的Baidu,Face++等都有类似的服务。但是模型的具体架构、训练算法等细节是不公开的,知识会提供API,供用户使用,MLaaS的提供商可以通过此API向用户收取查询费用来获得收入。从攻击者的视角来看,API可能会带来哪些风险呢?本文将会介绍三种利用API接口发动的攻击,以及对应危害,并给出防御策略。
Membership Inference Attack
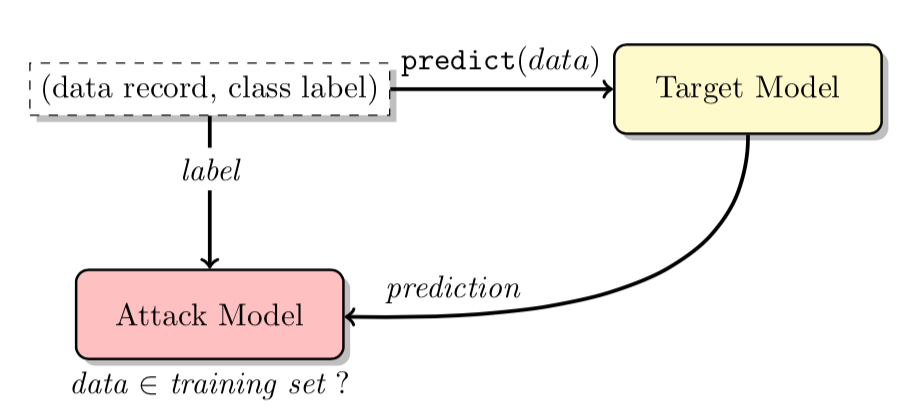
该攻击目的是针对一个给定的的机器学习模型,给定一条记录,攻击者可以判断给定记录是否是训练集的一部分,这就涉及到了训练数据集的隐私泄露问题。通过该方法,攻击者就可以推测出有关于模型训练集的信息。
如上图所示,攻击者将目标记录作为input交给目标模型,模型会返回对该记录的output,其output是一个概率向量。攻击者将预测向量、目标记录的标签,传给攻击模型,攻击模型就可以判断记录是否在目标模型的训练数据集内。
攻击流程
该方案是三种方案中最繁琐的,所以有必要展开细说。
首先需要构造训练数据集,用其来训练影子模型(shadow model)(这些模型的行为与目标模型类型,不过相比于目标模型,我们明确知道给定的记录是否在影子模型的训练集中),然后使用影子模型教攻击模型(attack model)区分成员数据和非成员数据,最后利用训练好的攻击模型对目标模型进行推理即可。
Q1.怎么训练影子模型?
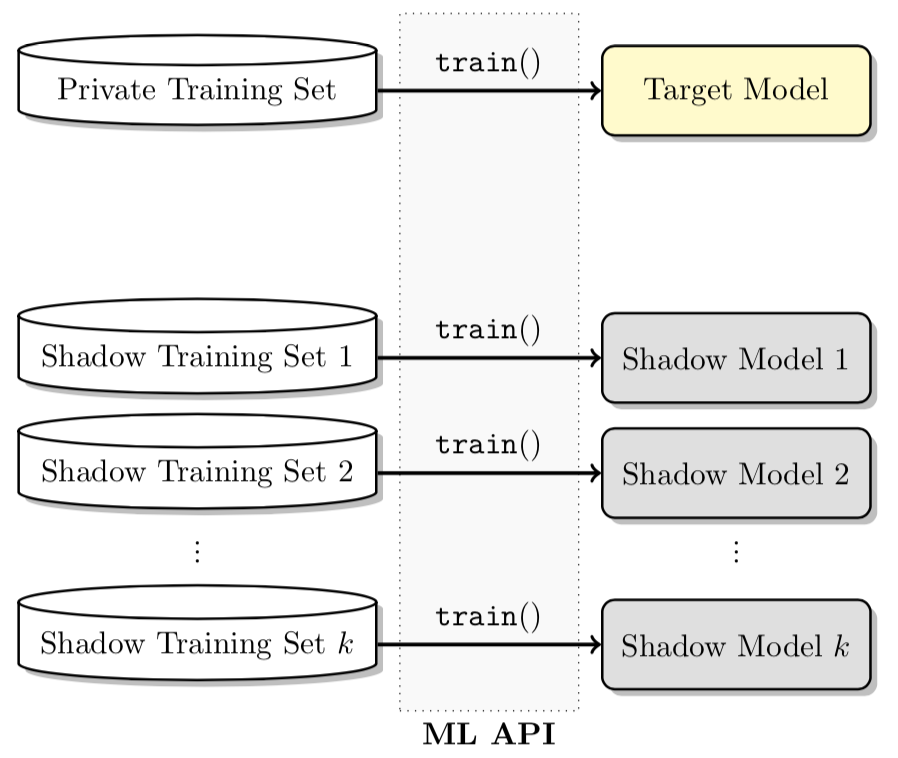
我们构造与目标模型的训练数据集格式相同的数据集对影子模型在与目标模型相同的机器学习平台上进行训练,所有k个模型内部参数都是独立训练的。
Q2.影子模型的训练数据集怎么构造?
有三种构造方法。
第一种是基于模型的合成(model-based synthesis),利用目标模型本身为影子模型合成训练数据。算法如下

合成过程分为两个阶段:(1)利用爬山法(hill-climbing)对可能的数据记录空间进行搜索,找出目标模型会给出较高置信度的输入记录;(2)从这些记录中抽取合成数据。在此过程合成记录之后,攻击者可以重复该记录,直到影子模型的训练数据集已满为止
第二种是基于统计的合成(statistic-based synthesis)。攻击者可能拥有被提取目标模型所需训练数据的总体集合的一些统计信息。例如,攻击者可以事先知道不同特征的边缘分布。可以通过独立地从每个特征的边缘分布中采样的值来生成数据集。
第三种是带噪声的真实数据(noisy real data),这针对的情况是攻击者可以访问一些与目标模型的训练数据类似的数据。
Q3.攻击模型如何训练?
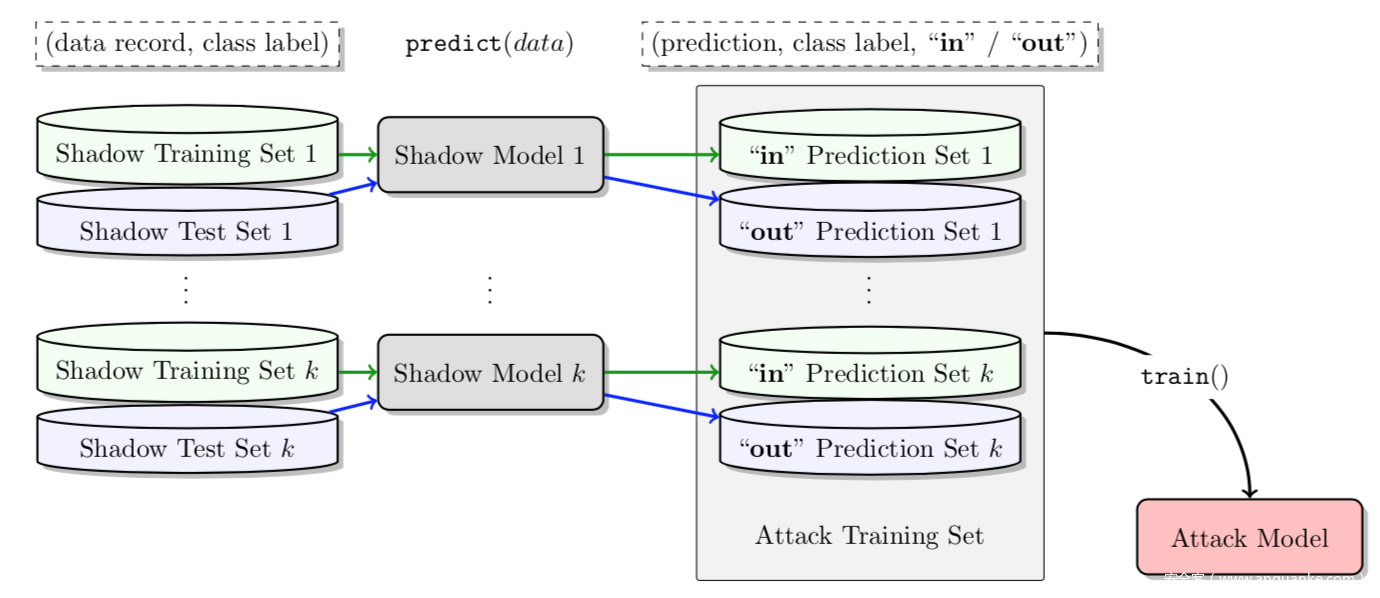
如图所示,我们在影子模型的输入和输出上训练攻击模型。对于影子模型训练数据集中的所有记录(成员数据),我们查询模型并获得输出。这些输出向量被标记为“in”并添加到攻击模型的训练数据集(非成员数据)中。 我们还使用与其训练数据集不相交的测试数据集查询影子模型。 该集合上的输出被标记为“out”,并添加到攻击模型的训练数据集中。
这个方案看起来比较繁琐,但是这么做是有理由的、
在黑盒的场景下,可以从目标模型中得到的只有预测向量,甚至在实际场景下,由于企业的使用限制,无法从目标模型中获得足够多样本的预测向量。此外,由于不同样本的预测向量的分布本身就不一致,即使攻击者直接利用预测向量进行训练,也无法实现较好的攻击效果。因此, 需要使用与目标网络相同的结构,并建立与目标数据集同分布的影子数据集,之后为每一类数据建立多个影子模型,实现了对预测向量的数据增强效果,并获得了大量的预测向量作为攻击模型的训练样本。并且利用预测向量构建了攻击模型,使其能够捕捉预测向量在成员数据和非成员数据之间的差异,从而完成了黑盒场景下的成员推断攻击。
原理
简单来说,该攻击可行主要有两个原因。
一个是过拟合(overfitting),成员推理攻击实际上是指攻击者能够区分出目标模型的训练集成员与非训练集成员,而模型的过拟合问题则是指模乘能够完美的预测训练集但是对于新数据的预测能力弱。如果一个模型过拟合,或者说泛化能力太弱的话,其训练集成员和非训练集成员就容易区分;另一个原因是训练集数据不具有代表性,机器学习的一般假设是测试集数据和训练集数据是同分布的,不具代表性也就是指训练集数据和测试集数据的分布是不同的,那么在训练集上训练出来的模型就不能很好贴合测试集的数据,从而导致模型的训练集与测试集异于区分。这两点原因使得成员推理攻击能够成员。
防御
防御方案都很多,这里给出几种比较典型的。
一种方案是知识蒸馏。知识蒸馏是利用迁移知识使得能够通过训练好的大模型得到小模型从而能够部署在资源受限的设备如手机中,大模型称之为教师网络,小模型称之为学生网络。防御成员推理攻击的实质实际上是无法区别模型训练集成员与非成员,而知识蒸馏这一技术恰好能够实现这一点。
一种方案是dropout,正如我们前面提到的,成员推理攻击能够成功的原因是由于模型的过拟合,因此可以通过提高模型的泛化能力从而使其能够防御成员推理攻击。Dropout在训练的过程中以一定比例随机失活神经元来达到提升模型泛化能力的效果。
一种方案是模型堆叠(model stacking),通过避免模型的过拟合来实现防御。使用三个分类器来实现分类任务,将前两个分类器的结果作为第三个分类器的输入,且三个分类器使用不相交的数据集,减少了模型记住训练集的可能,从而达到避免模型过拟合的效果。
Model Inversion Attack

该攻击的目的是利用黑盒模型输出中的置信度等信息将训练集中的数据恢复出来,上图所示就是利用该技术将人脸从面部识别模型中提取出来,其中左边提取出的人脸,右边是训练集中的人脸。
攻击流程
攻击的关键算法如下所示

首先定义一个关于人脸识别模型f和AUXTERM的损失函数c(AUXTERM会使用任何可用的辅助信息),然后最多进行α次迭代梯度下降,梯度步长大小为λ。每一次执行梯度下降后,得到的特征向量会传给后处理函数PROCESS,它可以根据给定的攻击进行各种图像处理,比如去噪、锐化等。如果损失在β次迭代中未能提高,或者至少与γ一样大,则终止梯度下降过程并返回最佳结果。
攻击者需要计算损失函数c的梯度,这就反过来要求计算模型f的梯度,这就意味着模型必须是可微的。
当然,该方案有明显的局限性,从下图可以看出,应对不同的算法进行攻击时,其攻击效果差异较大。

针对softmax,其重构出的图像具有清晰可辨别的特征,而MLP和DAE的特征轮廓模糊得多。
实战
为了简单起见,我们对线性分类器做攻击

模型训练完成后准备进行攻击
先看看待攻击的目标
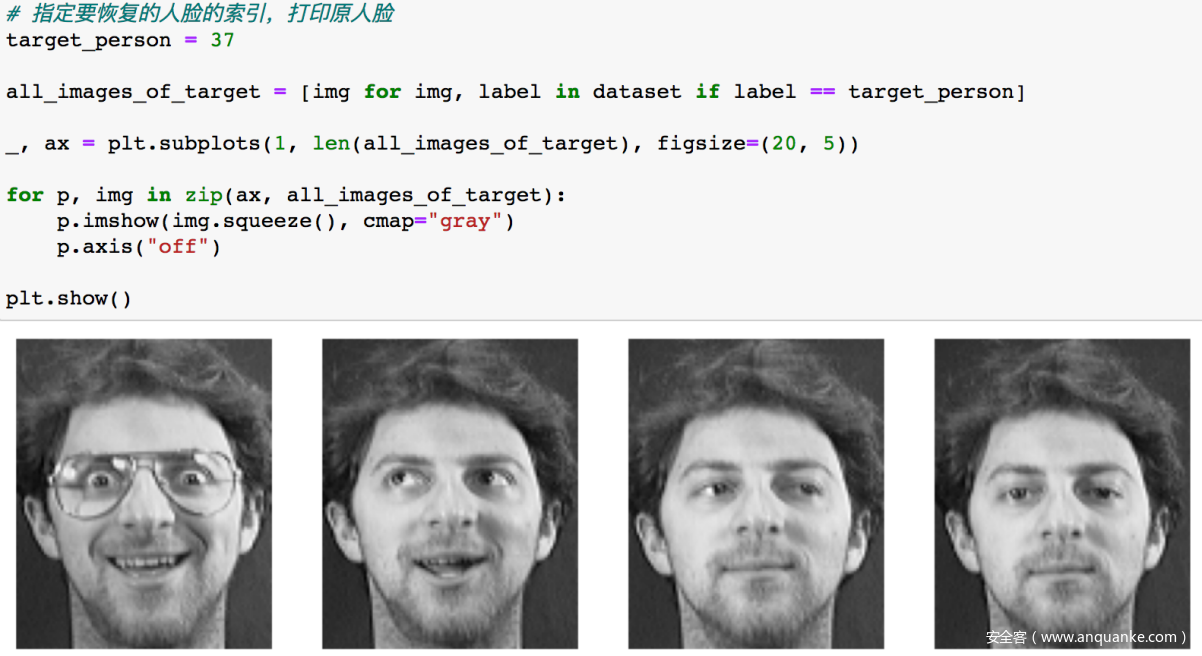
先初始化x,然后发动模型逆向攻击,下面的for循环就是利用x和目标标签的损失进行反向传播、更新,以一步步使x接近目标人脸

将x画出来

从上图可以看到结果与训练集中的原图像是非常接近的,说明我们攻击成功了。
原理
模型输出的置信度包含了输入数据信息,可以作为输入数据恢复的线索。攻击者将模型逆向 攻击问题转变为一个优化问题,优化目标为使逆向数据的输出向量与目标数据的输出向量差异尽可能小。也就是说,假如攻击者获得了属于某一类别的输出向量,那么他可以利用梯度下降的方法使得逆向的数据经过目标模型的推断后,仍然可以得到相同的输出向量。
防御
由于该攻击是基于梯度的,所以模型所有者降低用户可以从模型中提取出的梯度信息的质量或者精度即可。最直接的方案就是降低模型返回的置信度的精度,对softmax生成的分数进行四舍五入即可。

上图是不同舍入精度下攻击的效果,可以看到,精度越低,则攻击效果越差。
Model Stealing Attack
注意模型窃取和模型逆向的区别,模型逆向攻击的目的是为了逆向得到训练集中的数据,比如上面的例子就是逆向得到人脸,而模型窃取的目的是为了得到模型的信息,如参数、架构等。

该攻击目的是通过向黑盒模型进行查询获取相应结果,获取相近的功能,或者模拟目标模型决策边界。
这项技术的危害是什么呢?模型本身托管在一个安全的云服务中,它允许用户通过基于云的预测API查询模型。模型所有者通过让用户为预测 API付费来实现模型的业务价值,所以机器学习模型属于商业秘密.此外,一个模型的训练过程需要收集大量的数据集,也需要大量的时间和巨大的计算能力,所以一旦提取出模型并对其滥用,就会给模型拥有者带来巨大的经济损失。从另一个角度看,如果攻击者窃取了模型,那就相当于就拥有了模型的白盒权限,此时发动对抗样本等攻击就非常轻松了。
攻击流程
攻击流程的本质就是攻击者构造输入,向预测 API提交查询,并接收输出,获得许多输入输出对。
我们以考虑攻击线性回归模型。
线性回归模型形式上为f(x) = σ(w·x+ β),w为d维的weight,β为bias.逻辑回归是一个线性分类器,它在特征空间中定义了一个超空间,然后将样本分为两类。给定一个样本(x,f(x)),我们相当于获得了一个线性方程w·x+ β=,因此我们只需要d+1个样本对(即查询d+1次),就足以恢复出w和 β,这样便实现了模型窃取攻击。
实战
我们以攻击基于MNIST训练得到的线性分类器为例
由于MNIST中的图片的size为2828,所以我们就设计w为2828,那么总计有28*28+1个参数
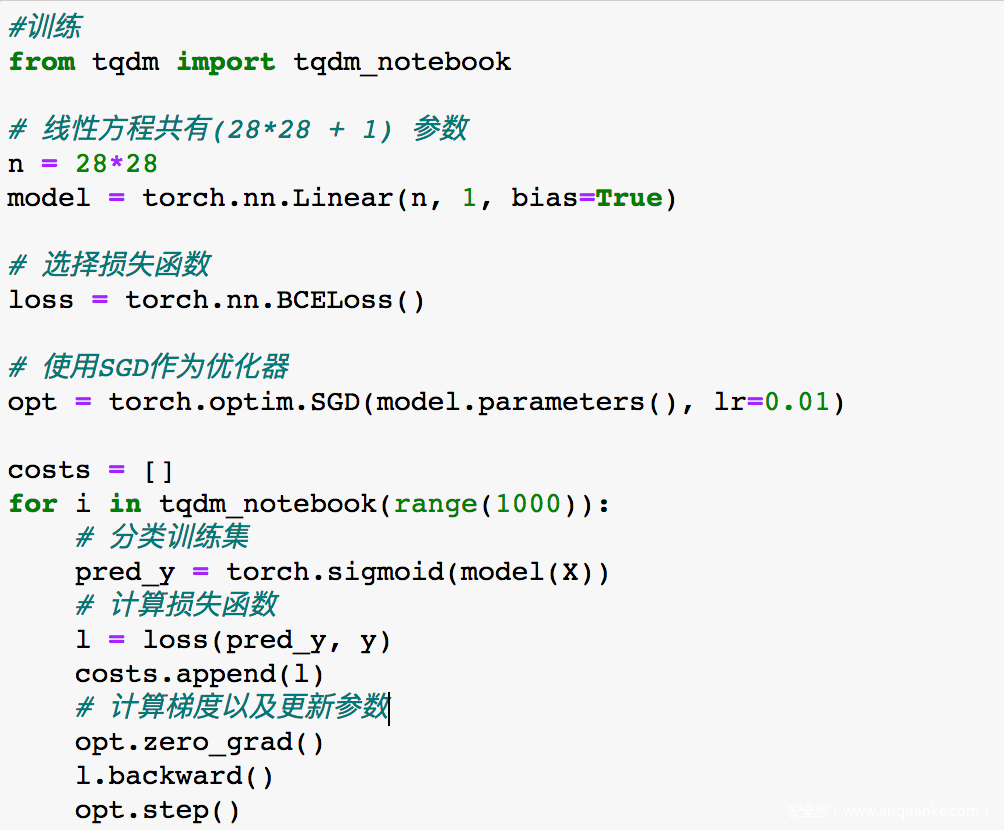
训练完成后打印查看模型性能

由于模型中参数太多,我们打印前20个
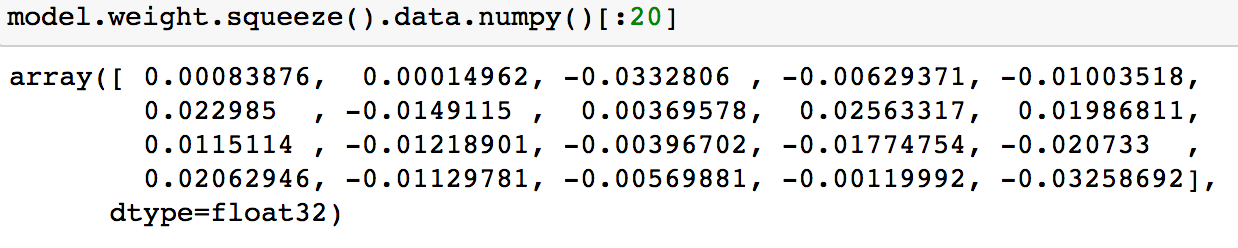
接下来我们执行”d+1”次查询,查询的x可以任意,满足查询次数即可
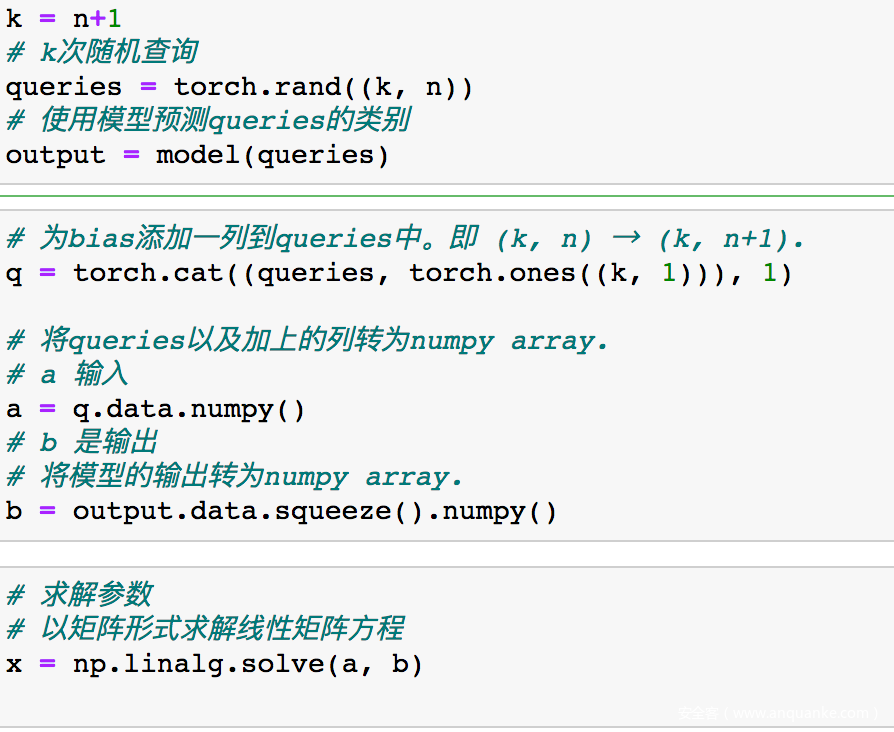
打印求解结果的前20个(即恢复出的前20个参数)
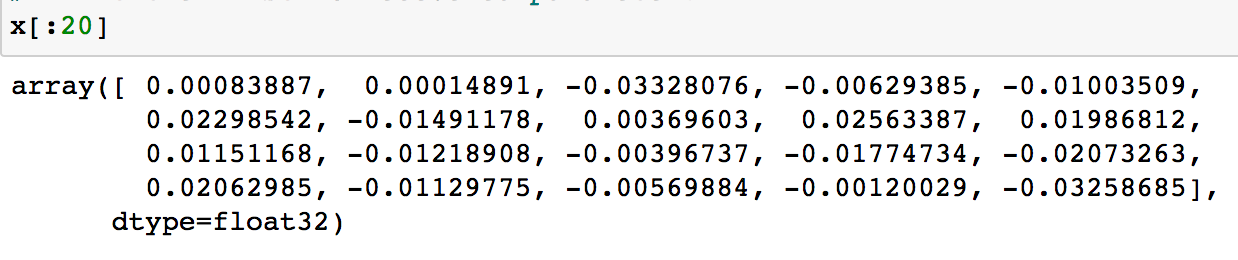
与模型原参数对比可知,是非常接近的。
原理
由于训练后的机器学习模型本质上是一个函数,因此只要攻击者获得足够的输入输出对并有足够的时间,从理论上就可以恢复模型参数。实际上在进一步做优化的攻击时,攻击者可以利用模型特性来生成包含更多信息的样本,以减少查询个数的需求和时间成本,有时甚至要牺牲一些准确性。
防御
最直接的方法就是限制返回给用户的结果精度,比如将置信度分数四舍五入到固定的精度,这样可以降低攻击的成功率。还可以使用集成技术。比如使用随机森林等方案,将多个模型的预测聚合起来作为最终的结果返回给用户,通过该方法,用户只能获得目标函数的相对粗略的近似值。另外还可以考虑差分隐私的方案,可以直接将差分隐私应用于模型参数,这样攻击者就无法区分相近的模型参数。
结束语
这三类攻击之所以可行,本质是因为模型的参数、模型的输出等信息都是通过输入样本产生的(模型在训练样本上训练,所以模型参数本质上与训练样本强相关,模型的输出取决于模型参数和模型测试样本,本质上也与训练样本强相关),只要是训练后的模型,其数据中一定会包含原始数据的信息,即意味着任何模型都会面临这些风险,并且无法完全抵抗。可以预见,后续攻击者会进一步扩展攻击场景,包括迁移学习、联邦学习、强化学习等,或者是从提升攻击效率角度出发,增强从与模型有限次的交互中获取尽可能多的信息。
另外,文中所列方案均为最典型的方案,随着研究人员意识到这方面攻击的危害,已有提出了越来越多的新方案,限于篇幅不再逐一介绍,有兴趣的师傅们可以阅读文末给出的参考文献,同时文末也给出了开源实现,师傅们也可以自己动手尝试一下。
参考
开源代码
1.https://github.com/inspire-group/membership-inference-evaluation
2.https://github.com/spring-epfl/mia
3.https://github.com/BielStela/membership_inference
4.https://github.com/privacytrustlab/ml_privacy_meter
5.https://github.com/yashkant/Model-Inversion-Attack
6.https://github.com/ftramer/Steal-ML
参考文献
1.Membership Inference Attacks Against Machine Learning Models
2.Stealing Machine Learning Models via Prediction APIs
3.Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures
4.Hacking smart machines with smarter ones: how to extract meaningful data from machine learning classifiers
5.Ml-leaks: model and data independent membership inference attacks and defenses on machine learning models
6.Privacy risk in machine learning: analyzing the connection to overfitting
7.Towards reverse-engineering black-box neural networks
8.Updates-leak: data set inference and reconstruction attacks in online learning
9.LOGAN: membership inference attacks against generative models
10.Cloudleak: large-scale deep learning models stealing through adversarial examples
11.Deep models under the GAN: information leakage from collaborative deep learning
12.Categorical reparameterization with gumbel-softmax
13.Machine learning with membership privacy using adversarial regularization
14.Knockoff nets: Stealing functionality of black-box models
15.Exploring connections between active learning and model ex- traction
16.A Survey of Research on the Attack and Defense of Artificial Intelligence Model Data Leakage
17.A survey on membership inference on training datasets in machine learning







发表评论
您还未登录,请先登录。
登录