

前言
技术的发展是为人类创造更美好的世界。
随着AI技术的进步,攻击AI的技术也越来越多,包括对抗样本、后门攻击等,这些是针对模型安全而言的,在数据层面,攻击者甚至可以通过攻击窃取训练集中的个人隐私数据,为此,安全研究人员提出将差分隐私应用于AI,以保护AI的训练集中样本的隐私;在另一方面,借助差分隐私技术也可以促进各方的交流,避免数据孤岛。在本文中,我们将以设想的新冠疫情下医院之间互助的场景为例,通过实战介绍PATE技术在利用AI赋能医疗行业的同时保护患者个人隐私。
场景
由于新冠疫情的流行,由大量的病人拍摄的CT等待被医生分析、诊断,我们尝试在自己的医院里创建一个二分类的图像分类器,可以根据CT图像判断病人的是否得了新冠(阳性或阴性)。但是我们的CT图像是没有标记的,这意味着不能做监督学习。而有5家医院有有标记的数据(医生已经看过CT并给出结论了),并且愿意帮助我们这家医院,可是如果直接把这些数据分享给我们,会侵犯病人的隐私,同时可能违反一些数据保护相关的法律法规。此时我们的目标是在为我们医院构建深度学习模型的同事,保护这5家医院的隐私,那么具体该怎么做呢?
背景知识
我们用到称为差分隐私的方法。什么是差分隐私呢?
差分隐私确保统计分析不会损害隐私。它确保个人的数据对整个模型输出的影响是有限的。换句话说,不论是否包括数据集中特定个体的数据,算法的输出几乎是相同的。
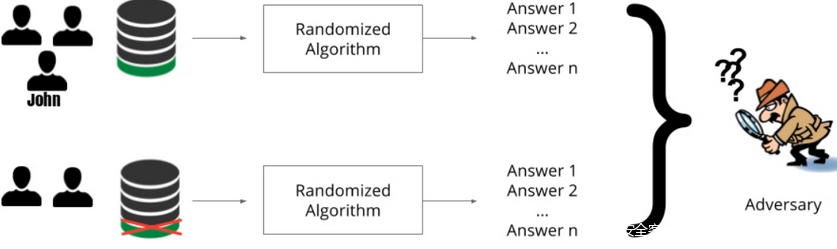
如上图所示,John 的信息出现在第一个数据集中,不在第二个数据集中,但是模型输出是相同的,所以想要获得 John 的数据的对手不能确定数据集中是否存在 John,更不用说数据的内容了。因此,John的隐私得到了保障。
差分隐私通常通过在模型或统计查询的输入层(本地差分隐私)或输出层(全局差分隐私)添加统计噪声来工作。增加的噪声保证了个人对决策结果的贡献被隐藏起来,但在不牺牲个人隐私的情况下获得了对整体的深入了解。
噪声的大小取决于一个称为privact budget(隐私预算)的参数,这个参数通常用ε表示。ε的值越小(即添加的噪声越多) ,它提供的隐私就越高,反之亦然。如下图所示,我们可以看到,随着越来越多的噪声被添加到脸部图像,它得到的匿名信息越多,但它变得越来越不可用。因此,选择正确的ε值非常重要,需要在可用性与隐私之间做好权衡。

在本文中我们使用的隐私方法叫做PATE(Private Aggregation of Teacher Ensembles)。
PATE的工作流程如下:
首先在不相交的训练集上分别训练得到几个模型,称为教师模型。然后将一个输入交给这些教师模型预测,教师模型预测得到各自的类标签,最终以所以教师模型输出的总和作为最终的预测类。不过这一步会分为两种情况:1.如果所有或者大多数教师模型的预测都是相同的,那么最终应该输出什么类就很容易知道了。这意味着不会泄露任何单个训练样本的私有信息,因为如果从某个数据集中删除任何训练样本,不会影响模型最后的输出。在这种情况下,privacy budget很低,算法满足差分隐私;2.如果各个教师模型给出的预测不一致,则privacy budget很高,这会让最终应该给出什么预测变得不那么直接,并最终导致隐私泄露。为了解决这个问题,我们可以使用Report Noisy Max(RNM算法),它会在每个模型的输出中添加随机噪声。通过这种方法可以提供一种强力的隐私保护。这种情况下,算法满足了完全意义下的差分隐私。
但是PATE不限于此,它还额外增加了隐私。可能有些人会觉得将教师模型聚合在一起用于推理就可以了,但是这是不行的,原因有两点:
1.每次我们做出预测,privacy budget就会增加,所以迟早都会达到一个点,那时候隐私是一定会泄露的
2.通过多次查询,攻击者可以获取教师模型的训练数据,这时隐私也完全泄漏了
所以我们不能简单的聚合,而需要创建一个学生模型。学生模型使用的训练集是没有标签的(如场景部分中提到的我们的医院),我们把训练集中的数据交给教师模型来预测,通过教师模型打标签,一旦打上标签,教师模型就可以被丢弃了。此时学生模型已经可以训练了,训练完毕后它实际上从教师模型中学习了有价值的信息。最重要的是,privacy budget不会随着学生模型每次查询而增加,而且在最坏的情况下,攻击者只能得到教师模型给出的带噪声的标签。
场景应用
回到我们的场景中来,我们希望为自己的医院训练一个分类器,用于判断病人是否患了新冠。我们只有一些未标记的CT图像,现在需要其他5家医院的数据来标记你的数据集,但是出于隐私原因,我们不能直接访问那5家医院的数据。在聊了上一节的知识后,我们决定按照如下步骤进行处理:
1.让这5家医院各自在自己的数据集上训练模型,完成这一步后,得到了5个教师模型
2.使用这5个教师模型,为我们医院的每张CT图像生成5个标签
3.为了保护教师训练集的隐私,可以对生成的标签应用RNM算法。对于每张CT图像,我们获得生成的5个标签中最频繁的标签,然后添加噪声实现差分隐私
4.使用带噪声的标签训练学生模型(我们医院自己的模型),将其部署在自己的医院中用于诊断。
数据集
没有多少开源数据集可以用于新冠病毒诊断,为了保护患者隐私,获取这些数据集是不容易的。不过github上开源了一部分,地址在这里:https://github.com/UCSD-AI4H/COVID-CT,中国武汉同济医院的一位高级放射科医生已经证实了该数据集的实用性。
在Images_Processed文件夹下有两个文件夹,分别是COVID和Non-COVID,对应存放的是确诊有新冠的和没有新冠的片子。在Data_Split文件夹下是图像的标签。为了后续编程方便,可以将Image_Processe和Data_Split分别改为Image,labels
创建数据集
在labels文件夹下同样可以看到COVID和Non-COVID,每个子文件下都有test,train,val,分别是测试集、训练集、验证集。
现在我们要模拟的场景是教师模型有私有数据(打上标签的),学生只有公开的没有标签的数据,所以我们可以将这里的训练集作为教师模型的新联数据集,将测试集作为学生模型的训练数据集,然后使用验证集来分别测试学生模型和正常模型(不通过差分隐私训练得到的模型)的性能。
首先创建一个自定义的dataset loader,创建数据转换,并最终加载数据

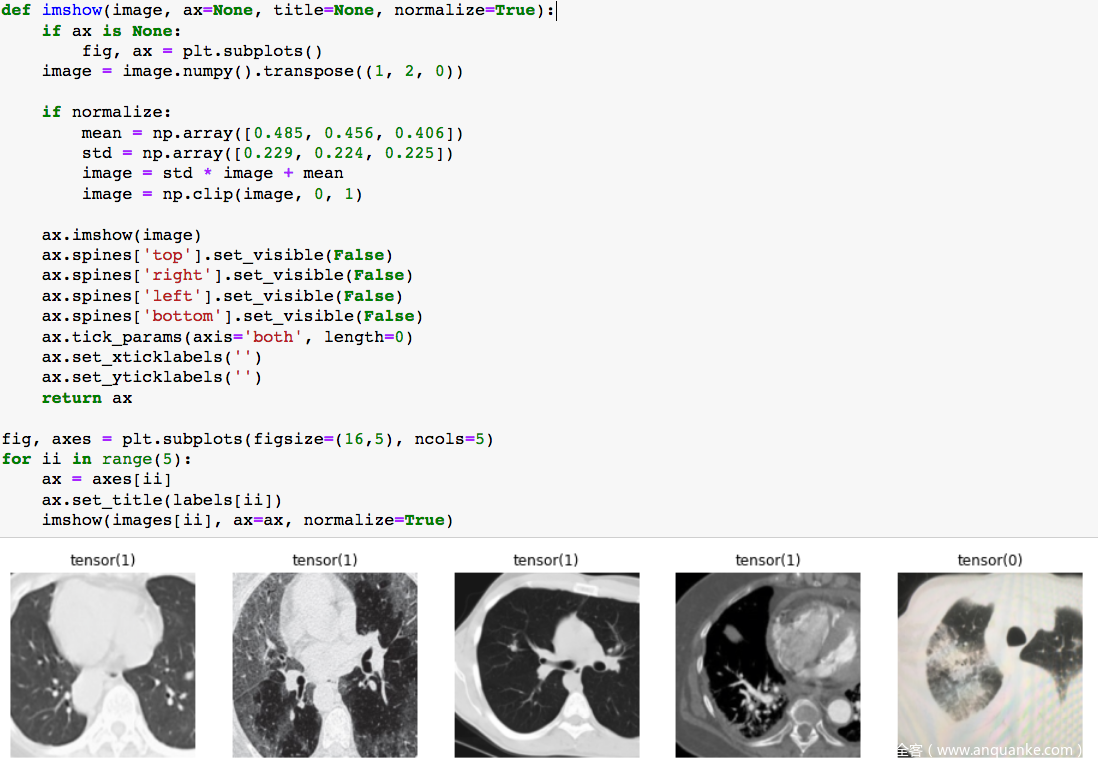
在成功加载数据后,可以可视化部分样本
我们现在可以继续在5家医院之间划分训练集。5家医院,对应着5个教师模型,这里需要注意,数据集必须是不相交的,也就是说,任何2个数据集都不应该有重叠的训练样本。前面已经说过,差分隐私中,如果个人的数据被从数据集中删除,数据集的输出仍然是相同的,以为个人对数据集没有贡献。如果有某一个人的副本,即使删除其中的一个副本,个人的数据仍然有助于输出,这样就无法保护个人隐私。
所以在将训练集划为5个子集时,我们必须非常谨慎。
下面的代码就是在5个教师模型或者说5个医院之间划分我们的训练集,并为每一个教师模型创建训练集dataloader和验证集dataloader。

现在对于教师模型来说,有5个trainloader,5个validloader;接着我们为学生模型(我们自己的医院)创建trainloader,validloader

训练教师模型
首先训练教师模型,5家医院会在不相交的数据集中训练得到5个不同的模型
首先定义一个简单的CNN模型

然后如下定义我们的训练代码

定义超参数,我们使用交叉熵损失CrossEntropyLoss和Adam优化器。
每个教师模型训练50个epoch

然后开始训练教师模型
获取学生标签
在训练完成之后,我们得到了5个教师模型,使用这5个模型为学生模型生成标签。这5个模型中的每个模型都会为我们(学生)数据集中的每张图片生成标签。换句话说,对于学生模型的数据集来说,其中的每张图片都有5个生成的标签。
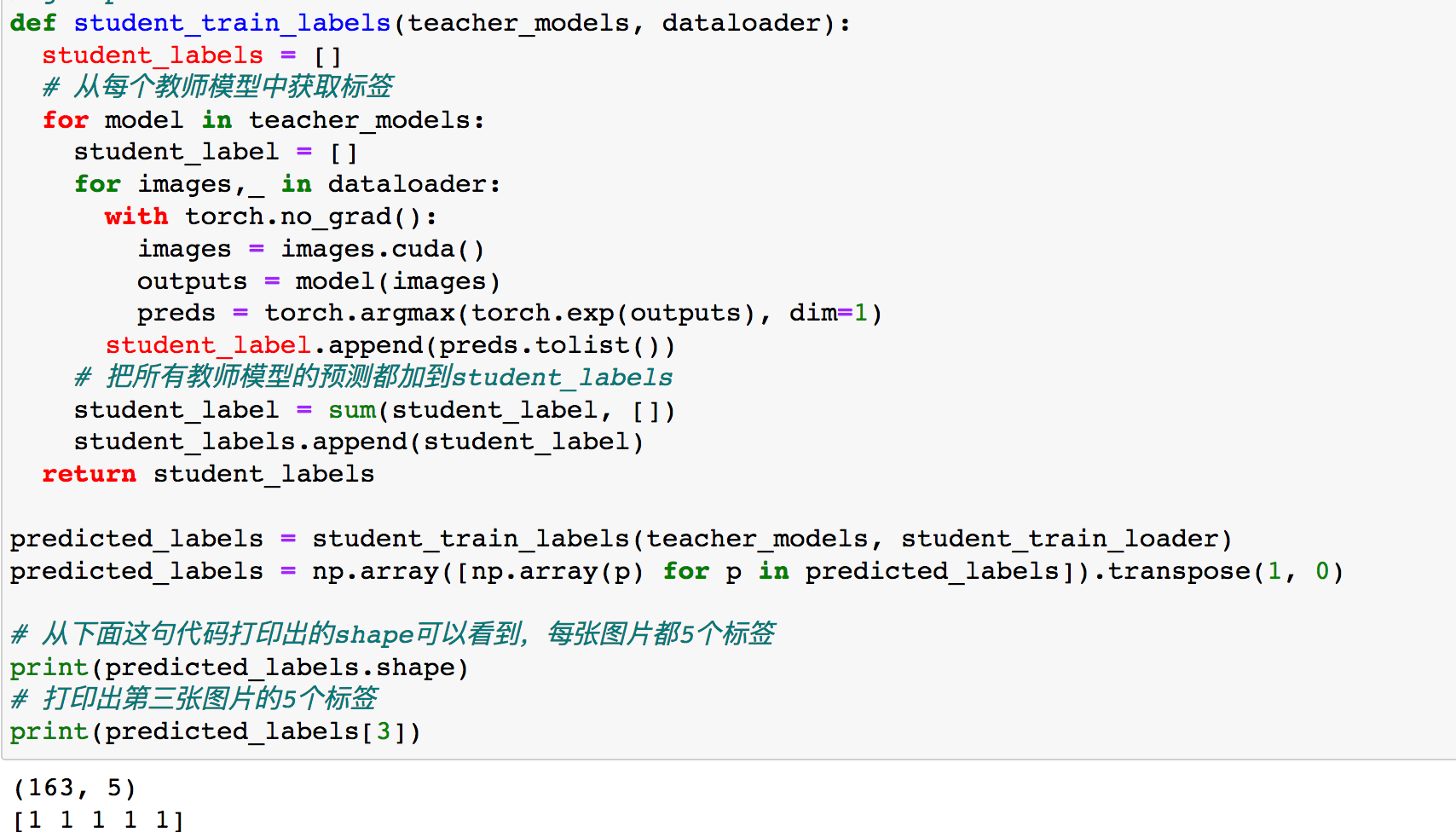
(163,5)的意思是说,在学生模型的数据中有163个训练样本,5个教师模型为每个样本生成了5个标签。第三张CT图片的预测标签为5个1,说明5个教师模型都认为这是新冠阳性。如果是[1,1,1,0,0]则表示两个教师模型认为这是阴性,三个教师模型认为这是阳性,此时我们以多数原则为依据,认为这是阳性。
添加拉普拉斯噪声
我们在模型训练之后添加被广泛使用的拉普拉斯噪声,这可以保证不会泄露超过的信息。我们定义了add_noise,其将预测的标签和值作为输入,我们可以使用控制添加的噪声量


我们把这些标签保存下来就可以了,训练好的教师模型已经用不到了

PATE分析
我们知道,这些标签实际上是来自于私人信息的,所以这些新标签中可能包含一定数量的泄露信息。泄露的信息量在很大程度上取决于添加的噪声量,这是由决定的。所以选择合适的很重要,我们可以使用PATE进行分析。它实际上可以告诉我们,如果发布这些标签,会有多少信息通过这些标签泄露。
我们使用perform_analysis方法,以所有教师模型的预测标签列表和我们刚刚计算的带噪声的新标签作为输入,并返回两个值:data_dep_eps,data_ind_eps,分别表示数据相关的和数据无关的。Perform_analysis目的在于告诉我们教师模型之间的一致性水平。data_ind_eps的表示在最坏情况下可能泄露的最大信息量,而data_dep_eps的表示教师模型的决策的一致性程度。一个小的data_dep_eps的表明,教师模型的预测具有很高的一致性,并且浙西模型没有记忆私人信息(过度拟合)。因此,小的data_dep_eps的表示较小的隐私泄漏率。在试验了不同的值以及noise_eps变量后,我们设=0.1,得到的结果如下

可以看到,我们得到的data_dep_eps的是15.536462732485106,data_ind_eps的是15.536462732485116
训练学生模型
现在已经从教师模型那里得到了带噪声的标签,现在就可以开始训练了。在训练之前需要用来自教师模型的新标签替换掉旧的学生的dataloader(其中包含着我们下载数据集的时候附带的原始标签,当然,在实际情况下我们是不可能有原始标签的,所以实际中是没有这一步的)

接着训练学生模型。我们使用换成新标签的trainloader进行训练,并使用validloader的数据集评估模型的性能。我们使用和教师模型相同的CNN架构以及超参数。
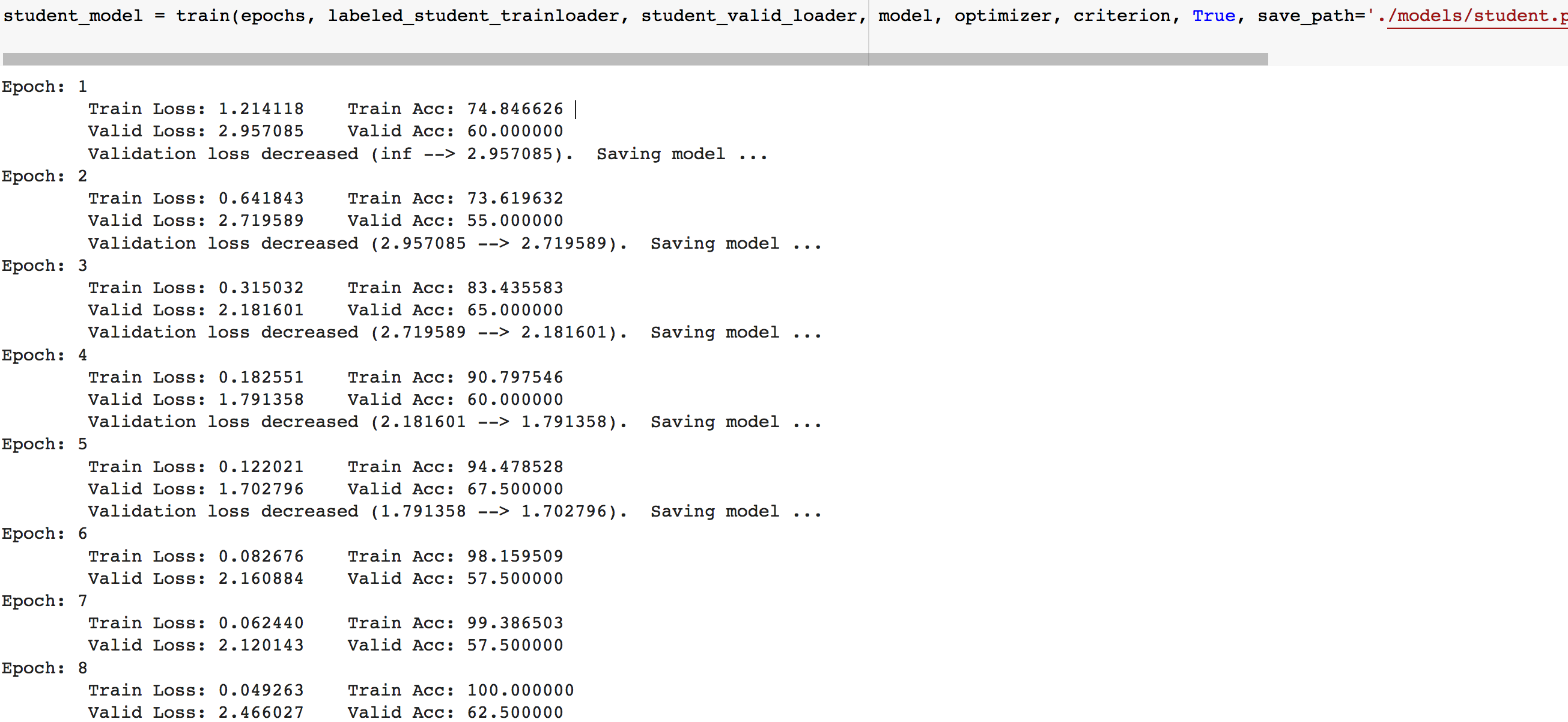
同时再训练一个使用原始标签的trainloader的数据的模型
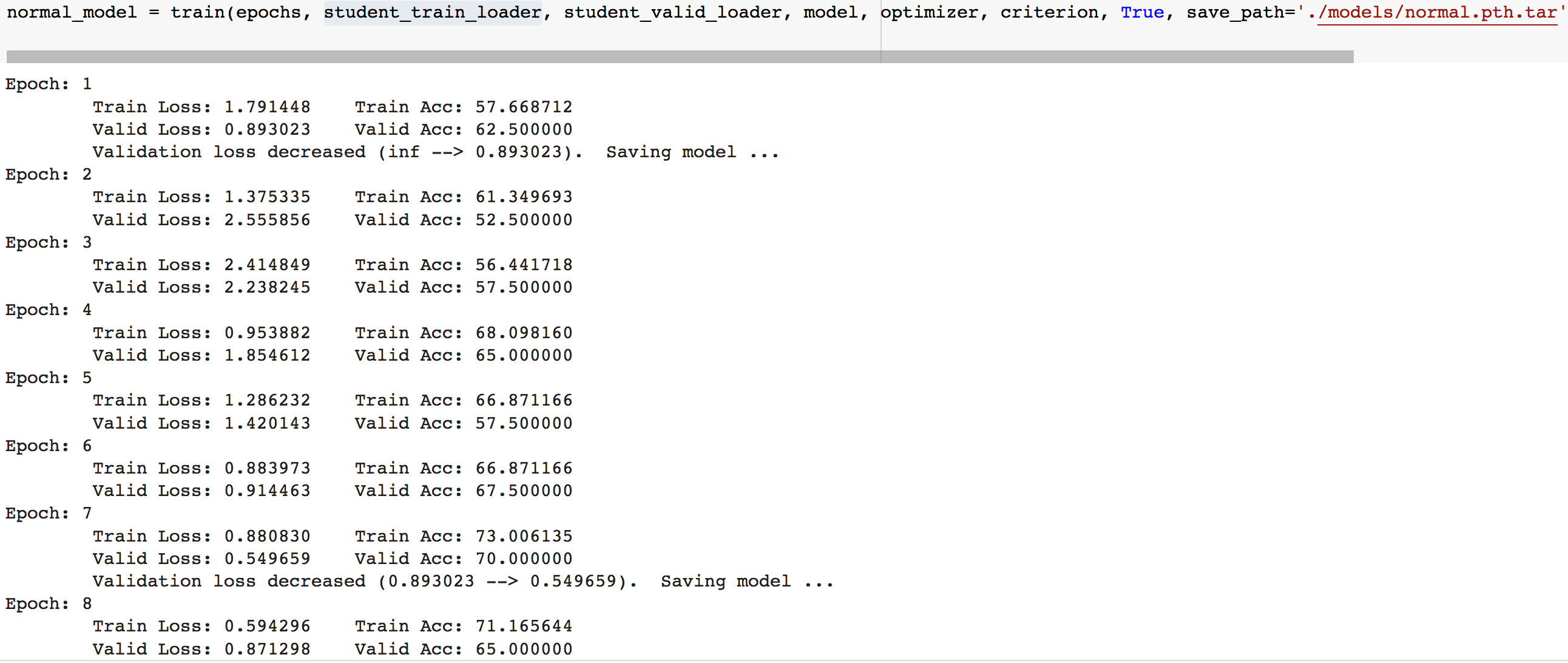
注意,这两个模型只有所用的数据集的标签是不同的
训练完成后,在测试集上比较这两个模型的性能


可以看到,学生模型的准确率稍微低于正常训练的模型,原因包括教师模型预测的偏差、添加的噪声等等,在不牺牲隐私、不违反数据隐私保护法律的情况下我们可以为5家医院之外的其他医院训练出一个学生模型,可以提升医疗效率,拯救更多的生命。
总结
我们在本文中利用差分隐私保护方案PATE,以设想的医院互助场景为例,在保护患者隐私数据的情况下,实现了在未标记CT图像数据集上的训练,得到了不错的结果。
参考
1.Scalable Private Learning with PATE
2.http://www.cleverhans.io/privacy/2018/04/29/privacy-and-machine-learning.html
3.Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data
4.https://ivyclare.github.io/comic/pate/
5.https://blog.openmined.org/build-pate-differential-privacy-in-pytorch/
6.https://github.com/UCSD-AI4H/COVID-CT







发表评论
您还未登录,请先登录。
登录