

AI中的攻防
方院士曾经提到,对于安全领域而言,当一项新技术出现的时候,会面临两种情况,一种情况是用其赋能安全,在这方面可以赋能攻击,也可以赋能防御,比如生成对抗网络(GAN),可以用GAN识别恶意软件,也可以用GAN生成可以绕过杀软的恶意软件;另一种情况是其本身存在安全问题,对抗样本、数据投毒均属于这一种情况。
我们来简单整理一下发展脉络,出现了AI技术,人们想着用它来辅助安全,比如基于AI的杀毒引擎,但是攻击者开始研究AI本身的缺陷,发现了对抗样本的存在,其根本原因学术界尚有争议,但是它是深度学习模型的本质缺陷,只要是深度学习模型都会存在对抗样本的问题,所以攻击者可以构造能够规避基于AI的杀毒引擎检测的对抗样本(adversarial attack在其出现之前,还有个名称,就叫做evasion attack)。既然对抗样本无法规避,那么是否可以用一些可解释性技术,来解释模型做出决策的依据呢,如果可以做到这一点,我们知道是样本的哪一特征或者一些特征的组合让模型将其分类为正常软件或者恶意软件,那也是可以的。简单地说,我们用AI作为引擎辅助防御,但是攻击者能够AI本身,为了提高其决策可靠性,人们又引入了可解释技术,那么,攻击者是否可以进一步去攻击攻击、欺骗可解释性技术呢?
答案是可以的,这也是文本的重点,将会介绍如何攻击两种流行的可解释技术:LIME和SHAP.
可解释技术
在深度神经网络(Deep Neural Networks,DNN)的推动下,深度学习在许多领域取得了重大突破。深度神经网络成功的一个关键因素是它的网络足够深,大量非线性网络层的复杂组合能对原始数据在各种抽象层面上提取特 征。然而,由于大多数深度学习模型复杂度高、参数多、透明性低,如黑盒一般,人们无法理解这种“端到端”模型做出决策的机理,无法判断决策是否可靠。
深度学习模型在实际应用中产生了各种问题,可解释性的缺失使这些问题难以解决。例如在医疗领域,看似非常精确的用于肺炎患者预后的系统,非常依赖数据集中的虚假相关性。该系统预测有哮喘病史的病人死于肺炎的风险较低,但这是因为哮喘病人得到了更快、 更好的关注,才导致他们的死亡率更低。实际上,这类病人死于肺炎的风险会更高。在司法领域,借助 COMPAS 软件对罪犯再犯风险的评估,法官能更合理地对保释金额、判刑等做出决策。但由于训练和测试模型时所用数据库的代表样本不足或是无关统计相关等原因,模型存在潜在的人种偏见、性别歧视,或是其他各种主观偏见。在图像处理领域,高度精确的神经网络面对对抗攻击却很脆弱。只需对图像的像素进行不可察觉的改变,图像处理神经网络就可以将其任何预测改变为任何其他可能的预测。
对于安全性要求苛刻的应用,例如健康诊断、信用 额度、刑事审判,人们依旧选择线性回归、决策树等不那么精确,但人类可理解的模型。深度学习模型可解释性的缺失,严重阻碍了其在医学诊断、金融、自动驾驶、军事等高风险决策领域的应用。因此研究可解释性就显得格外重要,可解释性有利于系统的使用者更 好地理解系统的强项和不足,并明确系统的知识边界,了解系统在何种情况下有效,从而恰当地信任和使用系统来进行预测。对系统的设计者而言,可解释性有利于优化和改进系统,避免模型中的歧视和偏见,并加强对系统的管理和监控。
可解释性技术的关键在于将模型决策结果以可理解的方式向人类呈现,它有助于人们理解复杂模型的内部工作机制以及模型如何做出特定决策等重要问题。从模型自身的性质来看,线性模型、决策树天生带有可解释性,而深度学习天生是不具有可解释性的,为了提升可解释性,可解释性技术可以分为两类:全局可解释性和局部可解释性。全局可解释性从整体上理解模型如何进行预测,而局部可解释性为模型的单个预测提供局部解释,后者的代表就是LIME和SHAP。
LIME&SHAP
LIME、SHAP这类方法的本质是构建更简单的可解释模型,用这些模型作为复杂模型的近似,可以解释任何给定的黑盒分类器,它们通过通过学习每个预测的局部可解释模型(如线性模型),以一种可解释、可靠的方式解释任何分类器的单个预测,它们估计实例上的特征属性,确定每个特征对模型预测的贡献。
设f为需要解释的分类器,g是选中的用于学习并解释f的可解释模型,G是g的集合
另设g的复杂度为Ω(g),对于线性模型而言,其可由非零权重的数量来衡量;并用πx来衡量x和x’的相近程度
LIME,SHAP的目标就是在生成一种解释,同时满足:1.在x附近逼近黑盒行为;2.复杂度尽可能低,故目标函数如下所示
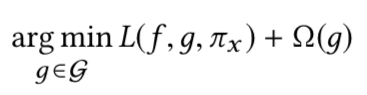
上式中的损失函数定义为
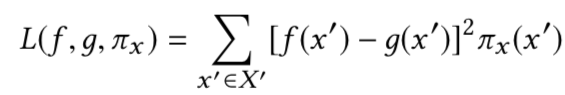
其中X’是在x附近的x’的集合
而LIME和SHAP的主要区别在于如何选择Ω(*g)和πx
在LIME中,这些函数的定义是启发式的,Ω(g)是线性模型中的非零权重,πx是使用余弦或者l2距离定义的。而在SHAP中,SHAP将这些函数的定义定义在博弈论原则的基础上,以保证解释满足某些期望的性质。
应用
我们来看看LIME,SHAP在解释模型时会有什么结果,这两种方法非常流行,已经有成熟的库可以用了,我们直接导入即可

我们针对前面提到过的COMPAS应用可解释性技术进行分析
先来看看LIME的解释


输出的结果中,上面的是LIME对原始模型的决策结果做出的解释,这里打印出了模型决策时最重要的前三个特征。可以看到,LIME认为模型在分类时将种族因素作为最重要的特征,也就是说原始模型是存在偏见的,此时,用户发现该偏见后就可以采取一些措施进行纠正,但是对于攻击者而言,它的目的就是为了欺骗可解释模型,从而让用户无法发现模型存在偏见,最终造成危害。
再来看看SHAP方法。

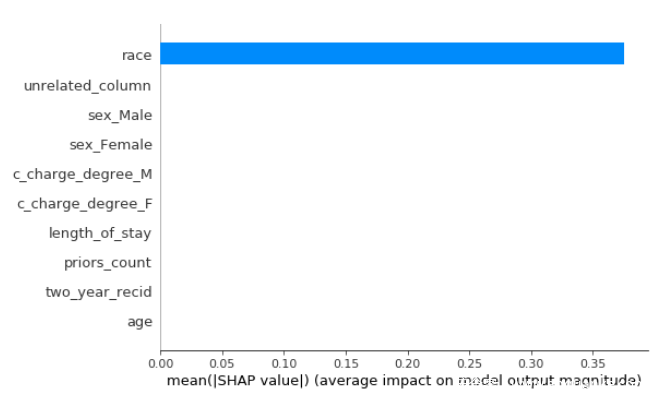
从输出结果可以看到,SHAP认为模型在做出决策时认为种族是最重要的因素,也就是说,这个模型存在种族歧视。如果熟悉COMPAS背景的人应该知道,它是用于评估犯人从监狱释放后,在两年内再次犯罪的可能性,早已有新闻表明该系统确实存在种族歧视,也就说到目前为止,SHAP,LIME等方案给出的结果是可信的。而用户发现模型存在偏见、歧视之后就可以想办法进行改进。但是如果攻击者欺骗了SHAP,LIME呢?如果SHAP,LIME不认为模型存在歧视,但是其确实存在歧视,一旦将其应用于现实生活中,后果不堪设想,尤其当模型歧视的因素是比较敏感的话题的时候,比如人种、性别差异等。
攻击LIME&SHAP
原理
LIME等技术通过构建局部可解释近似模型来解释给定黑盒模型的单个预测,每一个样本的局部近似都被设计用来捕获给定数据点附近的黑盒行为,这些邻域构成了由输入数据中单个实例的扰动特征生成的合成数据点。然而,使用这些扰动生成的实例可能是off-manifola或者out-of-distribution(OOD)的
为了更好地理解由扰动生成的合成数据点的性质,研究人员进行了实验。他们使用LIME方法对输入实例进行扰动,然后对包含原始实例和扰动实例的组合数据集进行主成分分析PCA,将其降到2维
结果如下
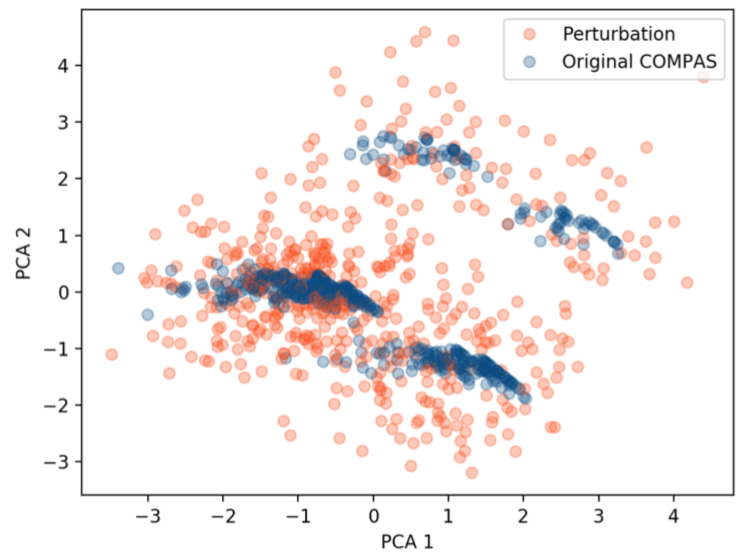
从图中可以看到,合成的数据的分布与原始的实例的分布有很大的不同,这种现象是研究人员欺骗LIME,SHAP的基础。攻击者可以在输入数据点上创建一个类似于原始分类器(可能具有很大的歧视性)的对抗性分类器,但是在扰动数据上的表现却与原始分类器不同,对抗性分类器表现地没有偏见并且是公平的,从而有效地欺骗LIME、SHAP。
设f是前面提到的有偏见的分类器,对手希望设计一个对抗性分类器,在用户生成这个黑盒的解释时,解释技术会被欺骗,认为这个模型是无害的。这个分类器接收的N个数据点组成的数据集X来自于真实世界的分布Xdist。为了欺骗解释性技术,攻击者设计的对抗分类器,在从Xdist采样的数据点上显示有偏见的行为,而在不是来自Xdist
的数据点上保持没有偏见,由于LIME,SHAP输出的特征重要度严重依赖于扰动实例(通常是OOD样本),因此得到的解释将使对抗分类器看起来无害。
设Ψ是一个没有偏见的分类器(基于与敏感特征不相干的无害特征进行预测),则对抗分类器e的形式如下
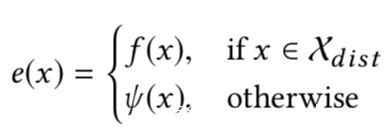
创建这种分类器的难点就是我们需要判断给定的数据点是否来自Xdist,或者说是否是OOD的,为此需要创建一个分类器is_OOD
为了创建分类器is_OOD,需要构造新的数据集,扰动每个实例x生成新的实例xp,设所有通过扰动得到的实例的集合为Xp,然后将X中所有实例的标签设置False,将Xp中所有实例的标签设为True(在X中的实例除外),然后我们在联合数据集Xp⋃X以及对应的标签上训练分类器即可。
实现
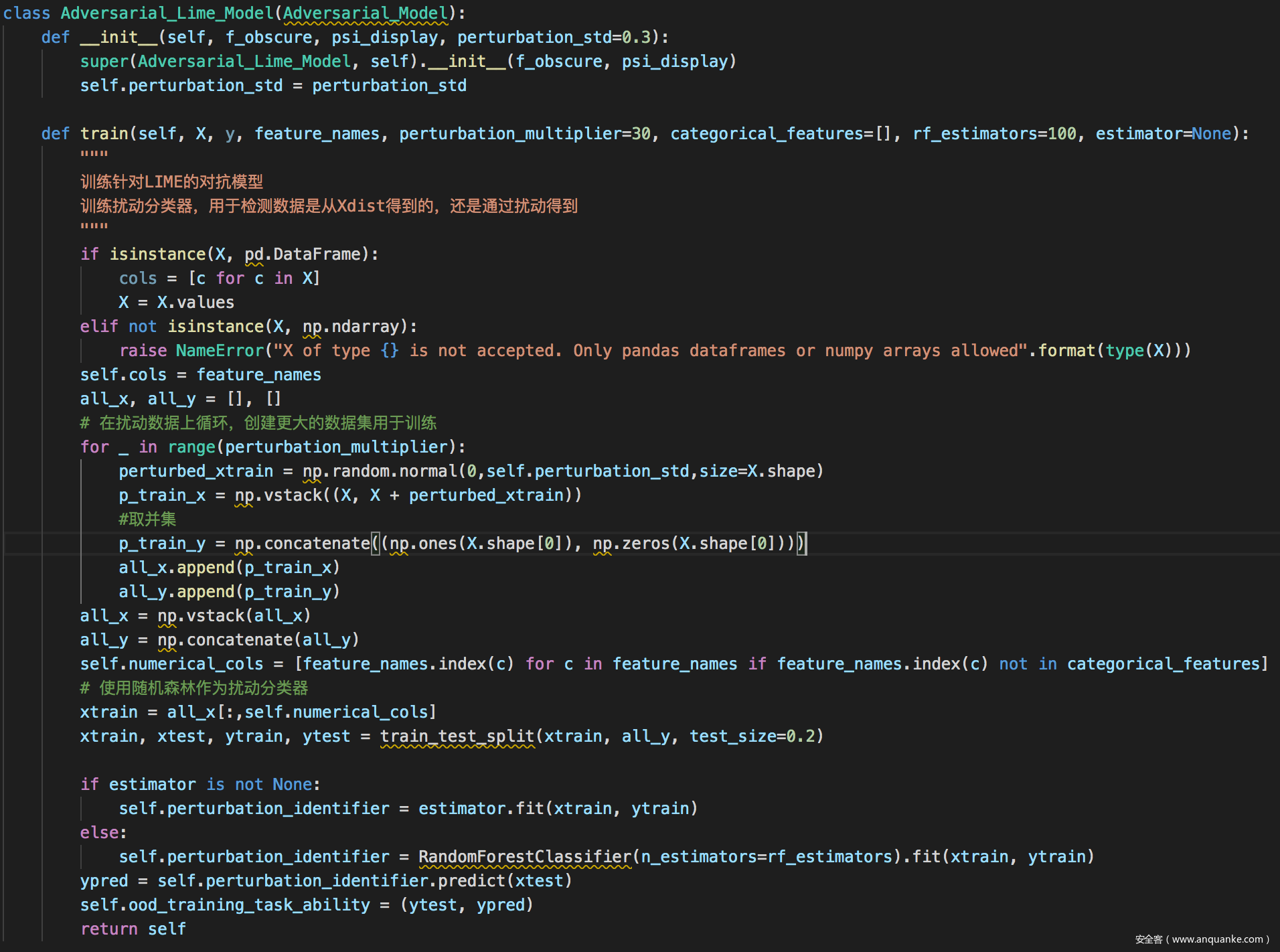
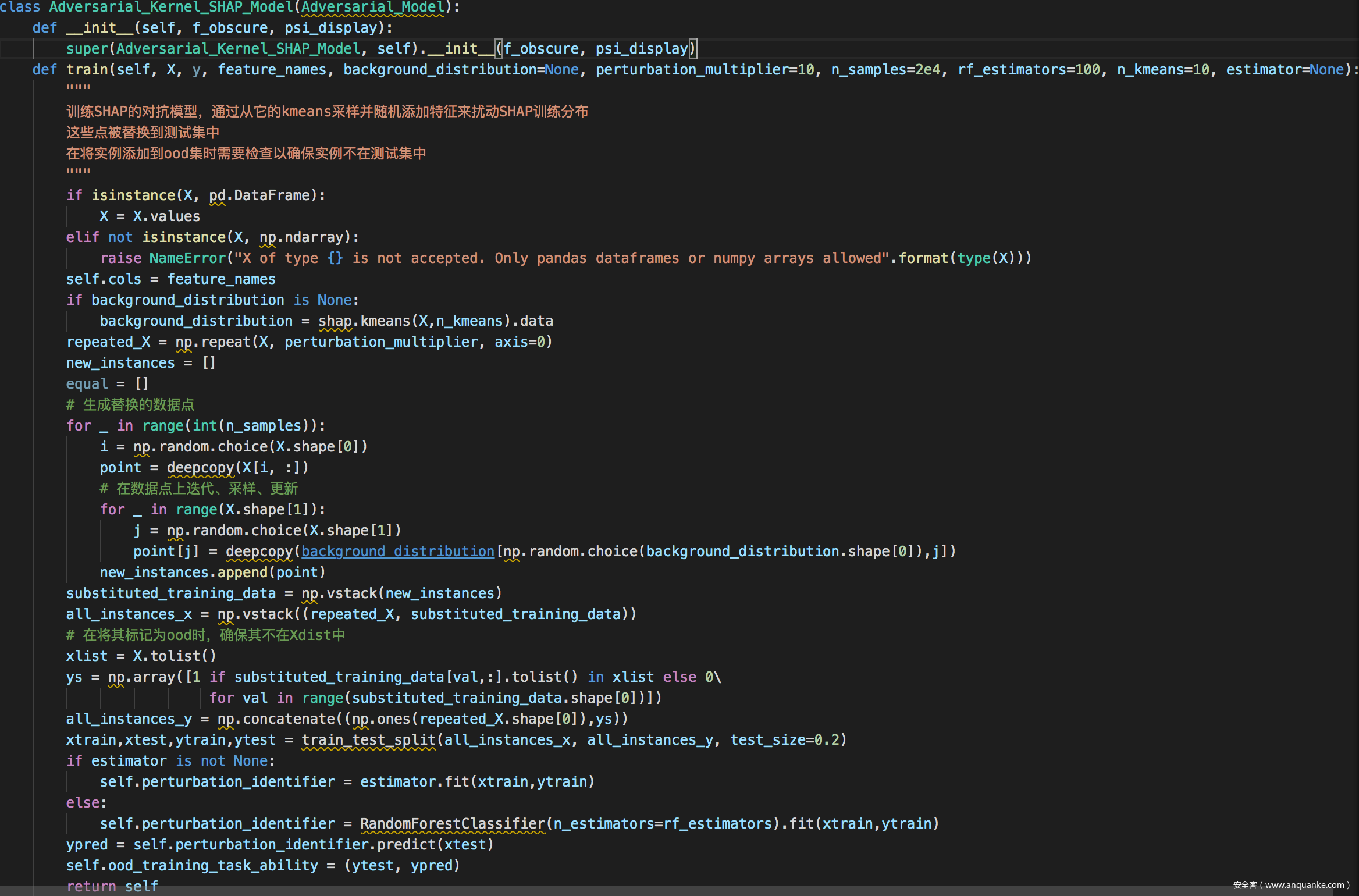
COMPAS测试
COMPAS数据集如下
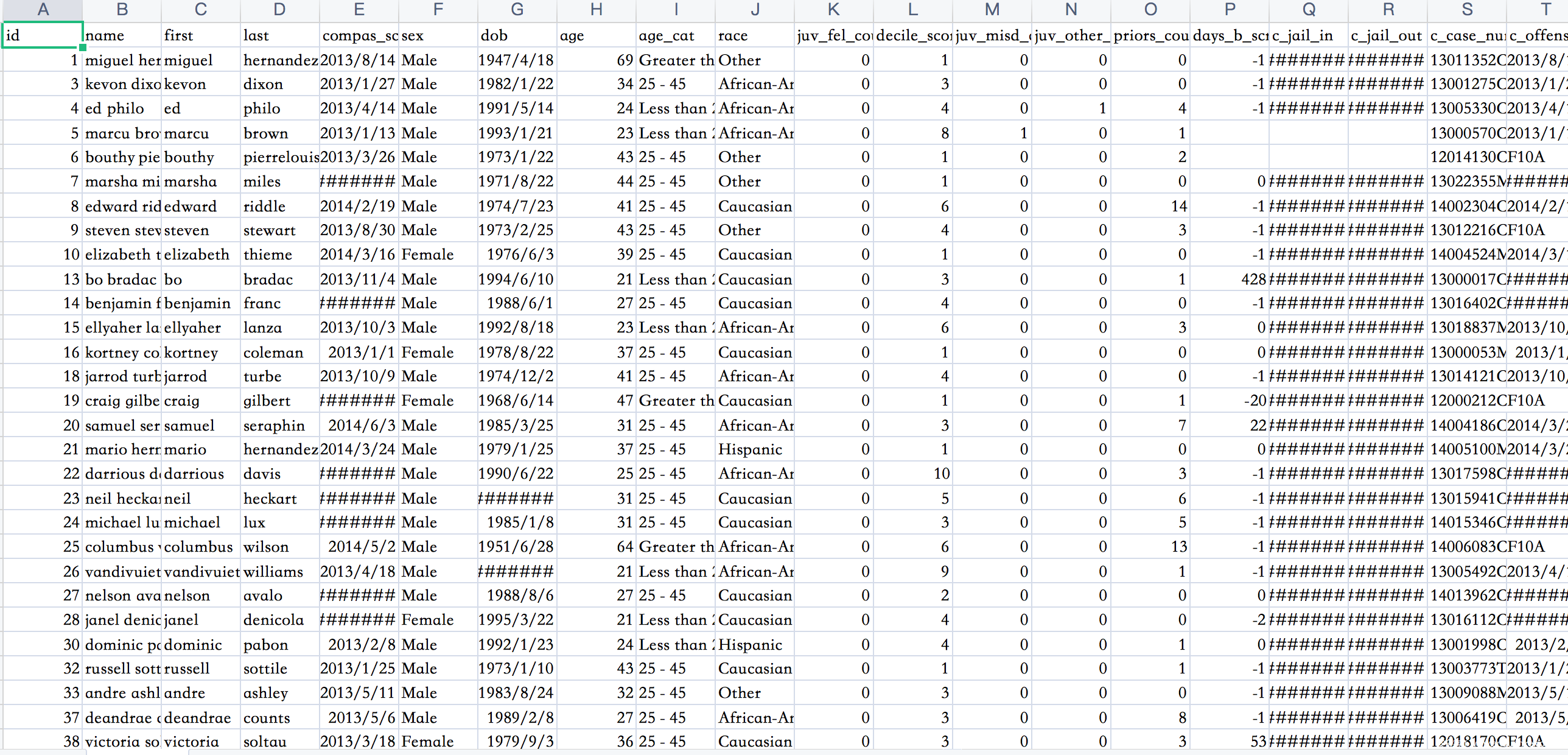



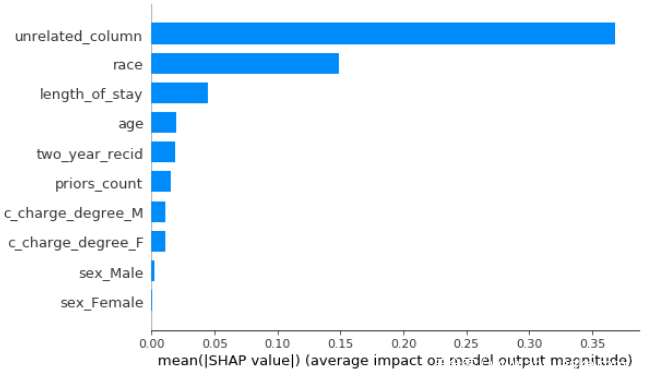
从结果可以看到,不论是LIME还是SHAP此时在解释对抗模型的决策时,都认为其不再以种族作为最关键的决策因素,即不再认为该模型是存在种族歧视的,而实际上,通过我们的分析,我们知道该模型事实上是存在种族歧视的,由此我们就实现了对LIME,SHAP方案的欺骗。
其他数据集
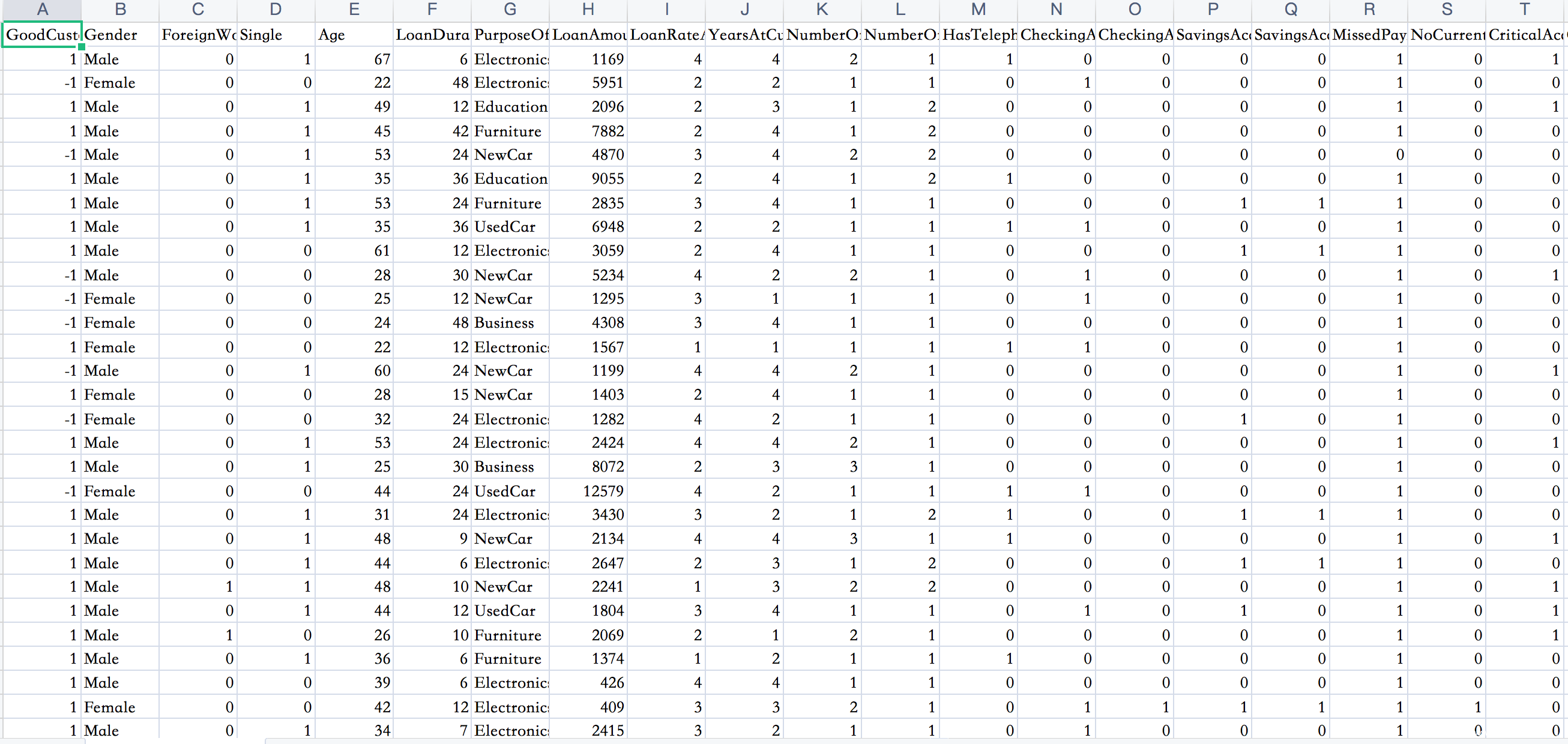
COMPAS数据中的特征包括犯罪史、人口特征、COMPAS风险评分、入狱和服刑时间,其输出为风险率,涉及到种族歧视的问题。Communities & Crime数据中的特征包括种族,年龄,教育程度,警察统计数据,婚姻状况,公民身份等,其输出为犯罪率,涉及到种族歧视问题。German Credit数据中的特征包括账户信息,信用记录,贷款目的,就业情况,人口统计资料等,是输出判断客户是否为优质客户,其存在性别歧视。我们可以用同样的方法进行攻击,攻击结果如下
数据集如下
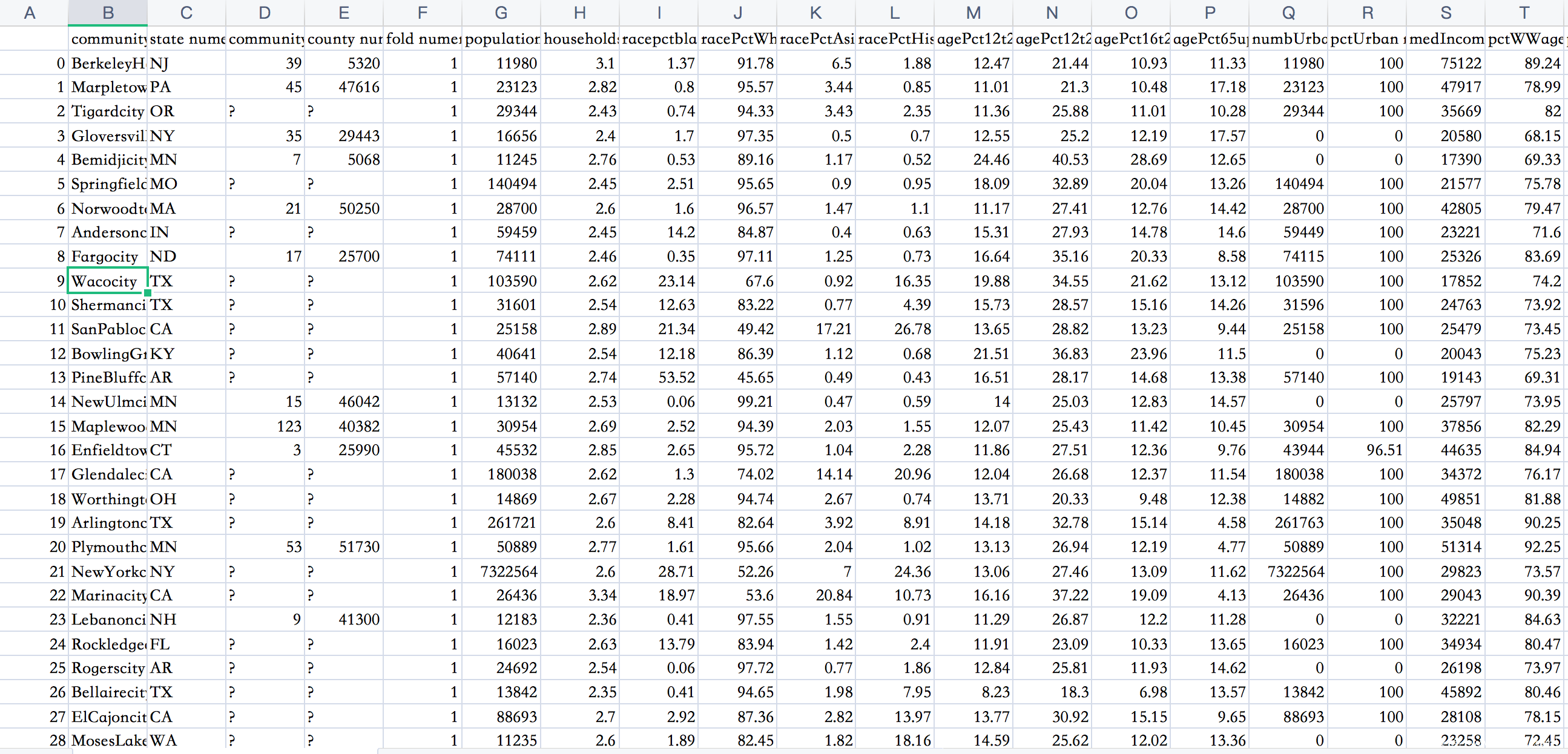
lime
shap

从结果可以看出,两种可解释性方法都认为除人种外的其他因素在模型决策时更加重要,而模型认为重要的因素,比如母语是否为英语、孩子数量等在我们人类看来往往并不要紧。
数据集如下
lime
shap

从结果可以看出,两种可解释性方法都认为除性别外的其他因素在模型决策时更加重要,而模型认为重要的因素,比如存款余额、是否为外国工作人员等在我们人类看来往往并不要紧。
参考
1.https://www.jiqizhixin.com/graph/technologies/60c538c0-32a9-4415-abab-6e1c0fba4cb3
2.深度学习模型可解释性研究综述
3.Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods







发表评论
您还未登录,请先登录。
登录