

前言
人工智能系统不止存在安全问题,还存在隐私问题,安全问题已经受到了广泛重视,对抗样本等攻击技术大家都有在讨论,相比之下,AI的隐私问题关注的人就没有那么多了,但事实上,AI的隐私保护面临的威胁形势也及其严峻。
我们知道,攻击者之所以会发动攻击,一定是考虑到攻击的性价比的,简单来说,攻击花费的资源如果少于或者远少于攻击成功可以带来的收益,攻击者才会发动攻击。如果从这个角度看,AI的隐私有什么值得攻击的呢?
事实上,大厂为了训练模型,需要花费大量的时间、金钱、人力去收集处理数据,然后花费大量算力训练模型,如果攻击者可以通过某种手段,窃取该模型,不就相当于省去了这么多投入,却能“白嫖”得到一个近似的模型吗?
这类攻击的性价比非常高,但是大部分的注意力还是在AI的安全方面,在隐私方面的关注还不够。本文会介绍一类典型以获取模型隐私为目标的攻击—模型窃取攻击,首先会介绍攻击背景、然后分析背后的细节、原理,最后给出实验复现和分析。
攻击
背景
攻击者的目标是为了窃取目标模型的功能,但在实际情况中,攻击者与目标模型之间仅存在黑盒的交互作用,即输入图像,输出预测,攻击者并不知道除此之外的任何信息。
方案概要及形式化
研究人员提出的对应的攻击方法可以分为两步:
1.向目标模型查询一组输入图像,并获得模型给出的预测
2.使用上一步得到的“图像-预测”对训练一个knockoff(即替代模型)
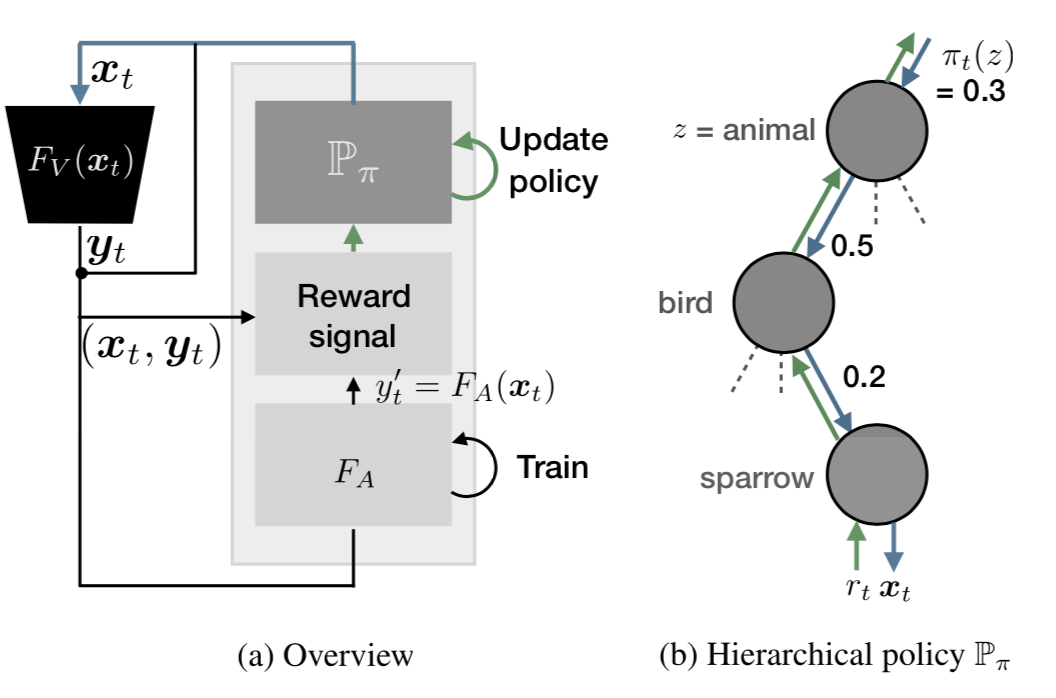
该攻击方案实际上针对的是AI模型的隐私问题,通过进行攻击,可以得到一个替代模型,而该模型的功能与目标模型相近,但是却不需要训练目标模型所需的金钱、时间、脑力劳动的开销。简单的示意图如下
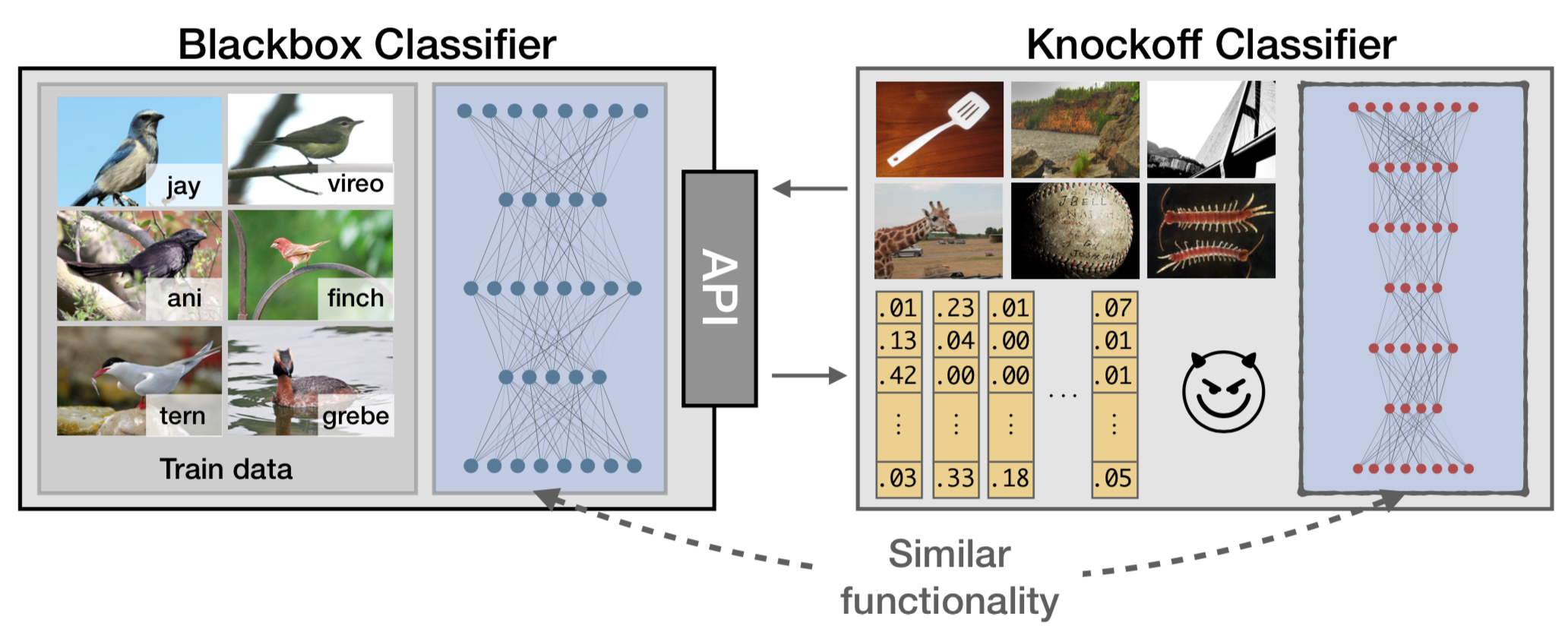
攻击者仅仅通过与目标模型的交互就可以创建一个替代模型。
该攻击方案的形式化表示如下
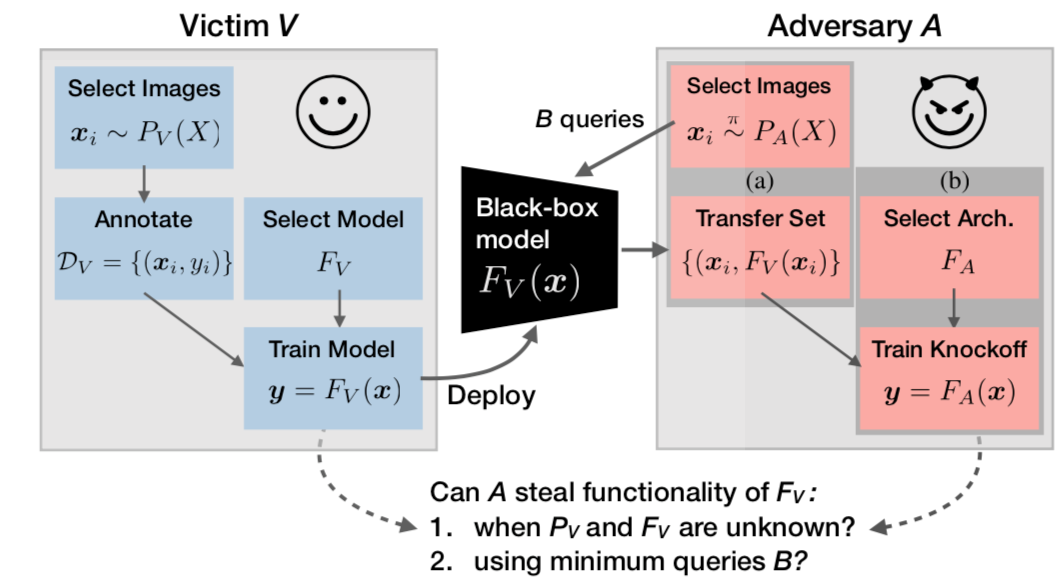
攻击者仅有与目标模型Fv:X->Y的黑盒交互权限,其目标是使用替代模型knockoff FA复制目标模型的功能。图上图所示,这个任务实际上受害者V和攻击者A之间的双方游戏
分析
先来看受害者的视角:
他会为一个具体的任务部署一个训练后的CNN模型Fv。为了训练这个模型,受害者需要:1.收集与任务相关的图像x~Pv(x),由专家对其进行标记,组成数据集Dv={(xi,yi)},2.选择在测试集上可以实现最佳性能的模型Fv,将其作为将要部署的模型,3.该模型将会以黑盒的形式部署,输入图像x,输出置信度y=Fv(x),当然,每进行一次预测,都会有一定的开销,比如延迟、金钱开销等
再来看看攻击者的视角:
攻击者面对的是一个黑盒的模型,输入任何图像x,模型会给攻击者返回K维的后验概率向量y,而这些信息是不可知的,包括:1.Fv模型的内部构造;2.训练集和测试集;3.K个类别的语义信息
为了训练得到knockoff,攻击者需要:
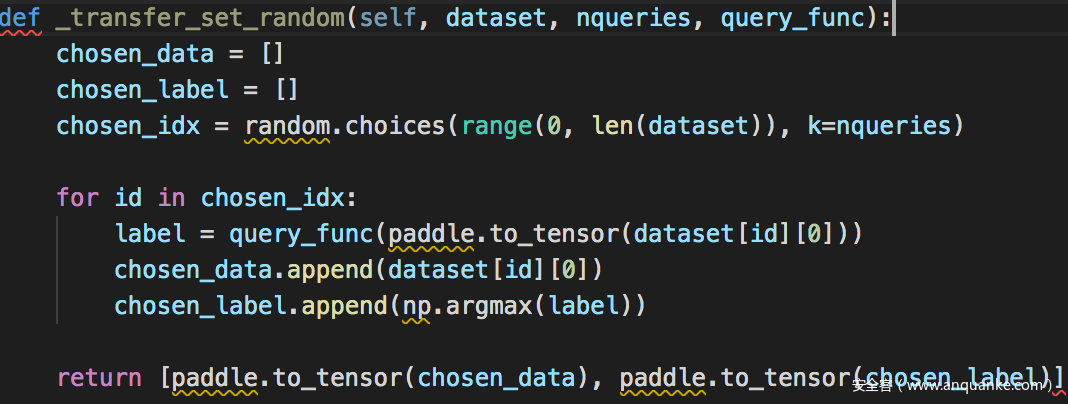
1.使用策略π交互查询图像得到图像的迁移集和伪标签
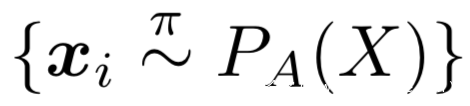
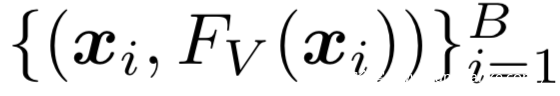
2.为knockoff选择一个架构并训练其模仿Fv在迁移集上的行为
我们的目标就是训练一个性能好的knockoff,此外还有解决两个问题:1.在有限的查询预算内怎样可以实现最好的性能;2.怎样才能挑选出适合用于查询的图像
该方案这么简单的一说可能很容易让我们想到知识蒸馏,知识蒸馏的目的是将知识从较大的教师模型T(白盒)通过迁移集迁移到较小的学生模型S(knockoff)上,但是我们的攻击与知识蒸馏存在显著不同,如下所示
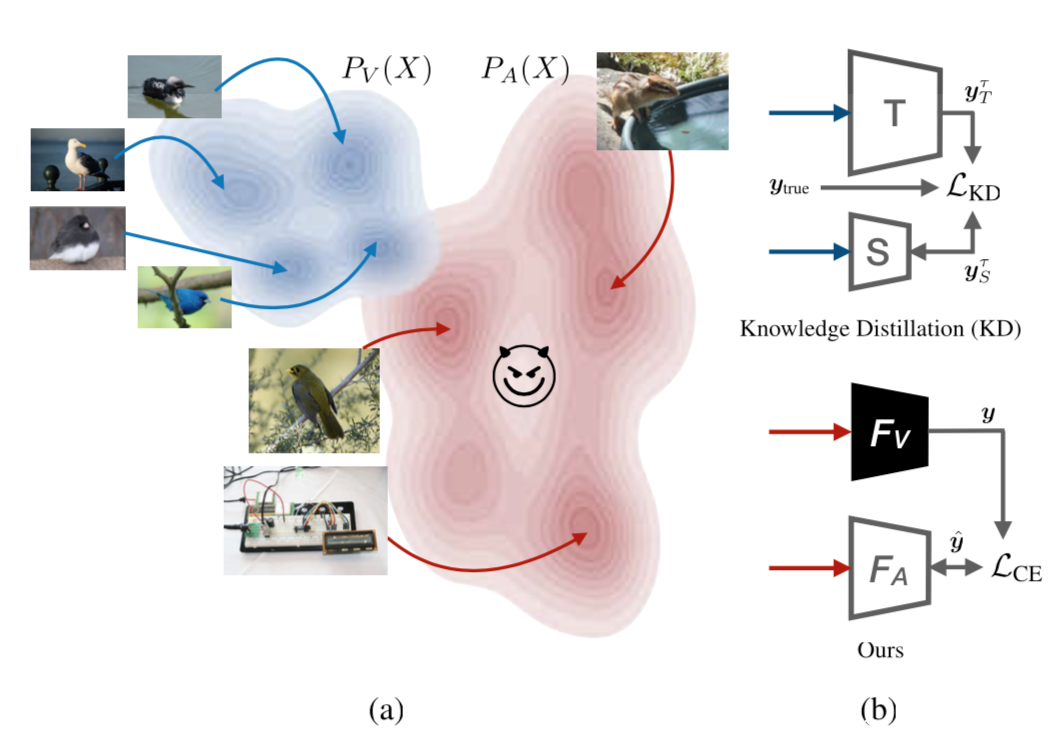
首先,分布是独立的,用于训练FA的图像x来自分布PA(x),而用于训练FV的图像其分布来自于PV;知识蒸馏需要有对模型更强的知识,S和FA都用于训练来分类服从Pv(x)分布的图像
其次,从用于简单的数据的角度来看,学生网络S最小化KD损失如下
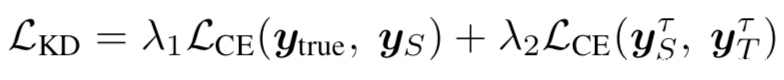
其中有:
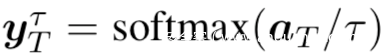
这是在温度t控制下的logits a的软后验概率分布
而在攻击方案中的knockoff(对应知识蒸馏中的S)缺少logits a以及正确的标签yt用于训练
攻击流程
那么该怎么生成Knockoff呢?
主要分为两步:迁移集构造和训练knockoff FA
构造迁移集
构造迁移集,也就是”图像-预测”对,用于训练knockoff模型Fv的行为
首先要选择PA(X).攻击者首先需要选择图像分布来采样图像,这是一个比较大的离散数据集,例如可以用ILSVRC数据集的1.2M的图像作为PA
然后要确定采样策略π:我们是使用这个策略从PA(x)中采样。这里可以考虑两种策略
在该策略下,随机采样图像,并向FV查询。这是攻击者会采取的极端情况,这种策略的风险是,攻击者采样的图像可能和学习任务无关,比如FV是用于分类鸟的,但是采样的图像却是狗
该策略可以将每次查询得到的反馈集成进来,此时的采样策略为:
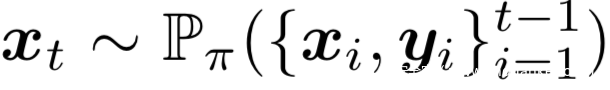
此时的目的是为了提升查询的样本效率;以及增加FV的可解释性
该方案如下图所示
在每个时间步t,策略模块Pπ采样一系列查询图像,奖励信号rt是基于多个标准得到的,并用于更新策略,最终目标是最大化期望的奖励
为了鼓励有关的查询,我们将每个图像xi与标签zi联系起来,从而丰富攻击者的分布。这些标签与目标模型的输出类之间没有语义关系。例如当PA对应ILSVRC数据集的1.2M图像时,我们使用了超过1000个类的标签。这些标签也可以通过非监督技术获得,例如聚类或估计图密度。使用标签有助于理解目标模型的功能。此外,由于我们希望标签{zi∈Z}是相互关联或相互依赖的,所以我们将它们表示为一个由粗到细的层次结构,上图b所示为一棵树的节点,从上往下为动物-鸟-麻雀。
在每个时间步t,我们从一个离散的动作空间Z(攻击者独立的标签空间)中采样动作zt.沿着树向前移动得到动作:在每个节点,用概率πt(z)对子节点采样,这个概率是由节点的softmax分布决定的,即:
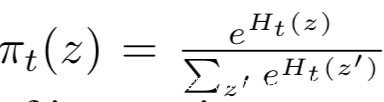
当达到叶节点时,返回对应于标签zt的图像样本
接下来使用动作zt获得的奖励rt使用Gradient Bandit算法更新策略π,这个更新过程等价于沿着上图b中的树反向移动,其中的节点potential可以更新为:
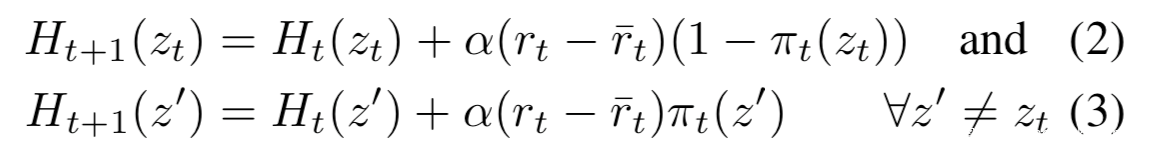
接着我们需要确定奖励怎么定义,为了评估采样图像的质量,我们研究了三种奖励
第一种使用基于边缘的确定性测度来鼓励受害者有信息的图像,即FV是在其上训练过的:
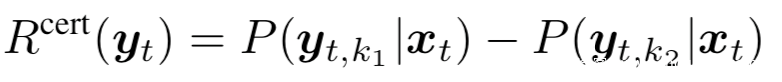
其中的ki是第i高置信度的类,为了防止在单一标签上探索图像的退化情况,引入了多样性奖励:
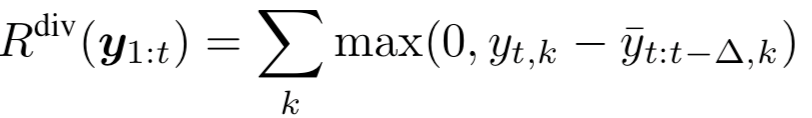
为了鼓励图像中knockoff的预测不模仿FV,我们奖励高交叉熵损失:
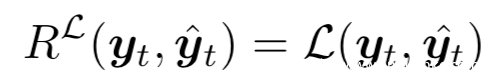
我们结合以上方法,得到总奖励,为了保持相同的权重,会将每个奖励分别缩放到[0,1],然后使用过去的∆时间步计算出的基线减去即可。
训练模型
接下来就是训练Knockoff FA
执行完上一步之后,我们已经得到了迁移集
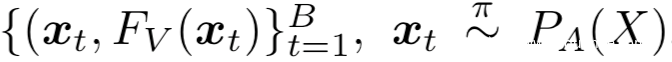
我们用该数据集进行训练
首选要选择架构FA,我们选择复杂的结构作为FA,比如VGG,ResNet等,因为知识蒸馏领域的研究表明,选择复杂的学生模型鲁棒性更好。
接下来需要训练以模型目标模型,为了加速训练,我们从预训练好的Imagenet网络FA开始,通过最小化交叉熵损失在迁移集上训练FA来模拟FV
实验分析及复现
通过对不同的数据集使用不同的查询预算做了实验,结果如下
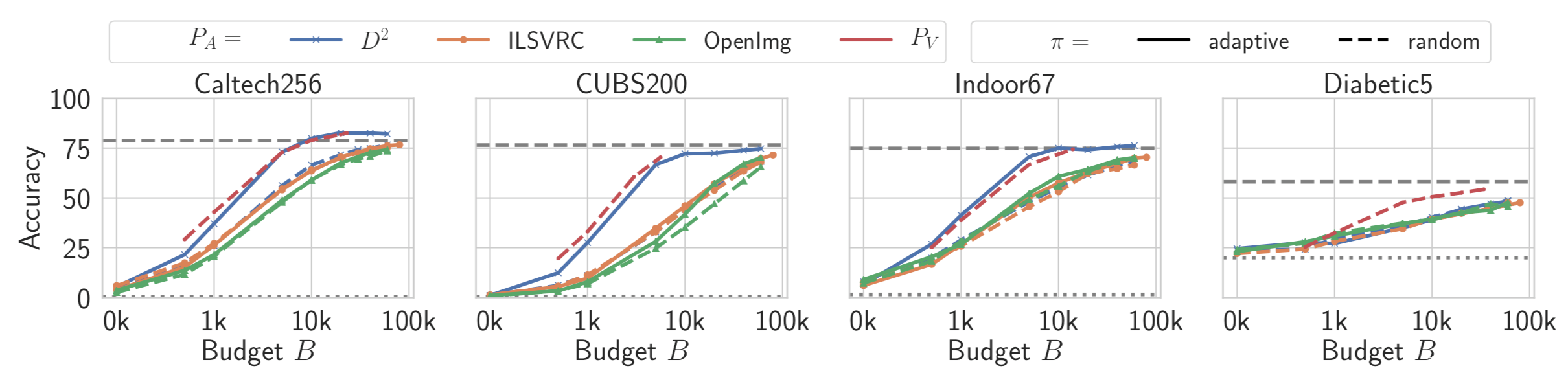
从结果可以看出,预算越高,或者说查询次数越多,则攻击效果越好。
为了研究不同FA架构的影响,研究人员使用两种黑盒FV架构:Resnet-34和VGG-16来研究这种影响。攻击者通过选择:Alexnet, VGG-16, Resnet-{18, 34, 50, 101}和Densenet-161分别作为FA的架构,实验结果如下
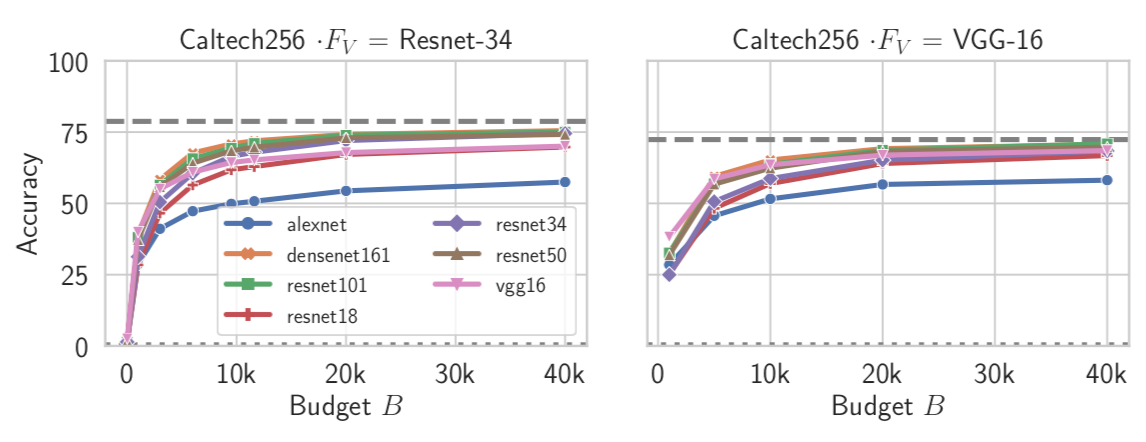
从图中我们可以得出两个结论:1.knockoff的性能按模型复杂度排序:Alexnet结构最简单,但是性能最差,更复杂的Resnet-101/Densenet-161性能却更好,这说明在选择FA架构时,选一个复杂的架构更好;2.模型家族之间的相似性有助于攻击,因为我们可以看到Resnet-34在窃取VGG-16时取得了相似的性能,反之亦然
那么面临这种攻击是否存在简单的办法呢?比如对输出的结果做处理,可以仅给出argmax,或者从top5变为top2,或者四舍五入,总是要尽可能少的暴露信息,为此也进行了相关实验,结果如下
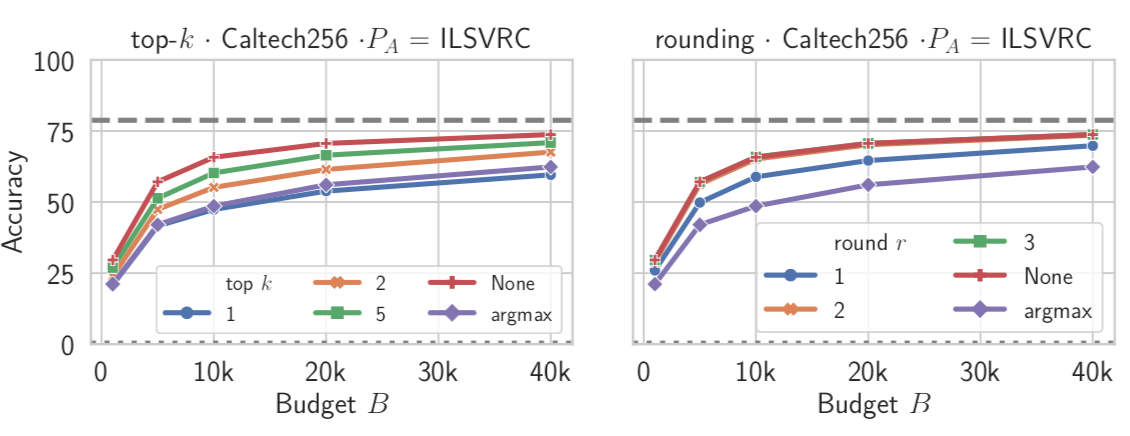
从图中可以看出,不论是取topk还是舍入都会影响模型性能,对于topk而言,k越小,则攻击效果越差;对于舍入而言,舍入的精度越低,攻击效果越差。这意味着,如果要防御该类型攻击,最简单的办法就是尽量减少模型输入泄露的信息。
接下来分析代码实现以及实际复现过程
我们使用MNIST数据集训练受害者模型,受害者模型选择线性模型
首先加载数据
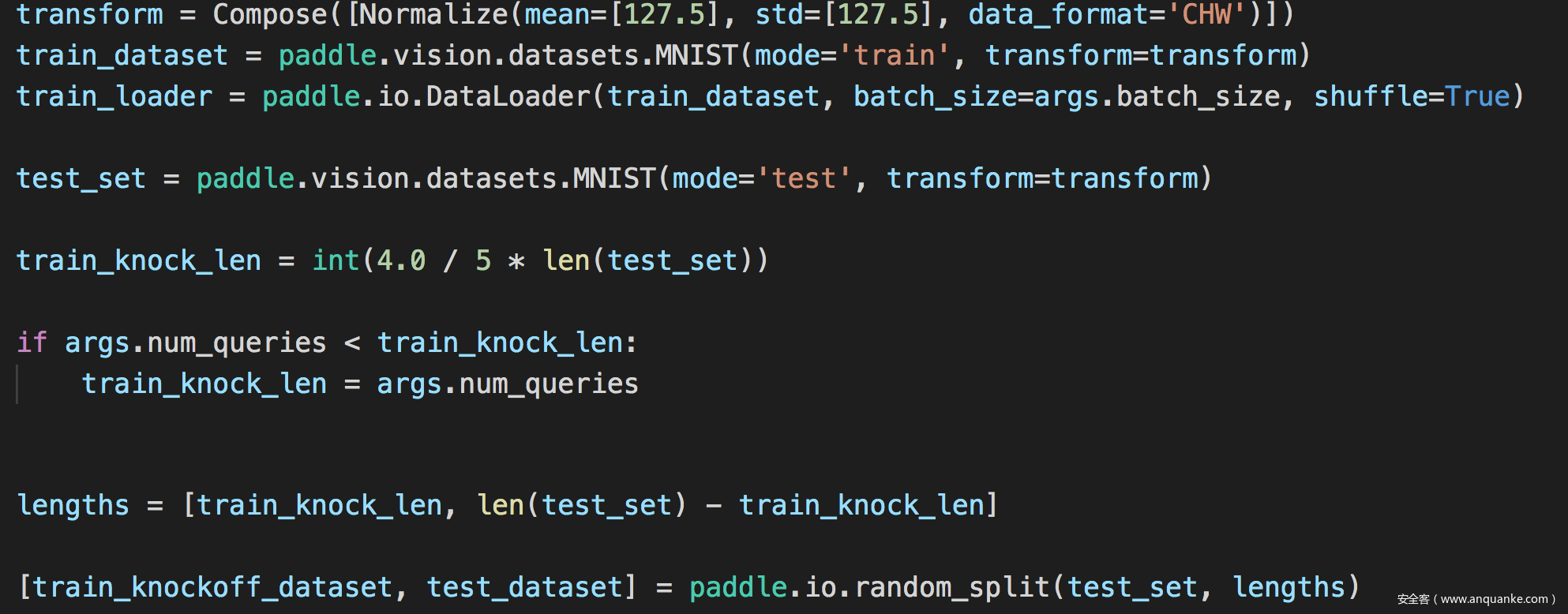
并定义受害者模型
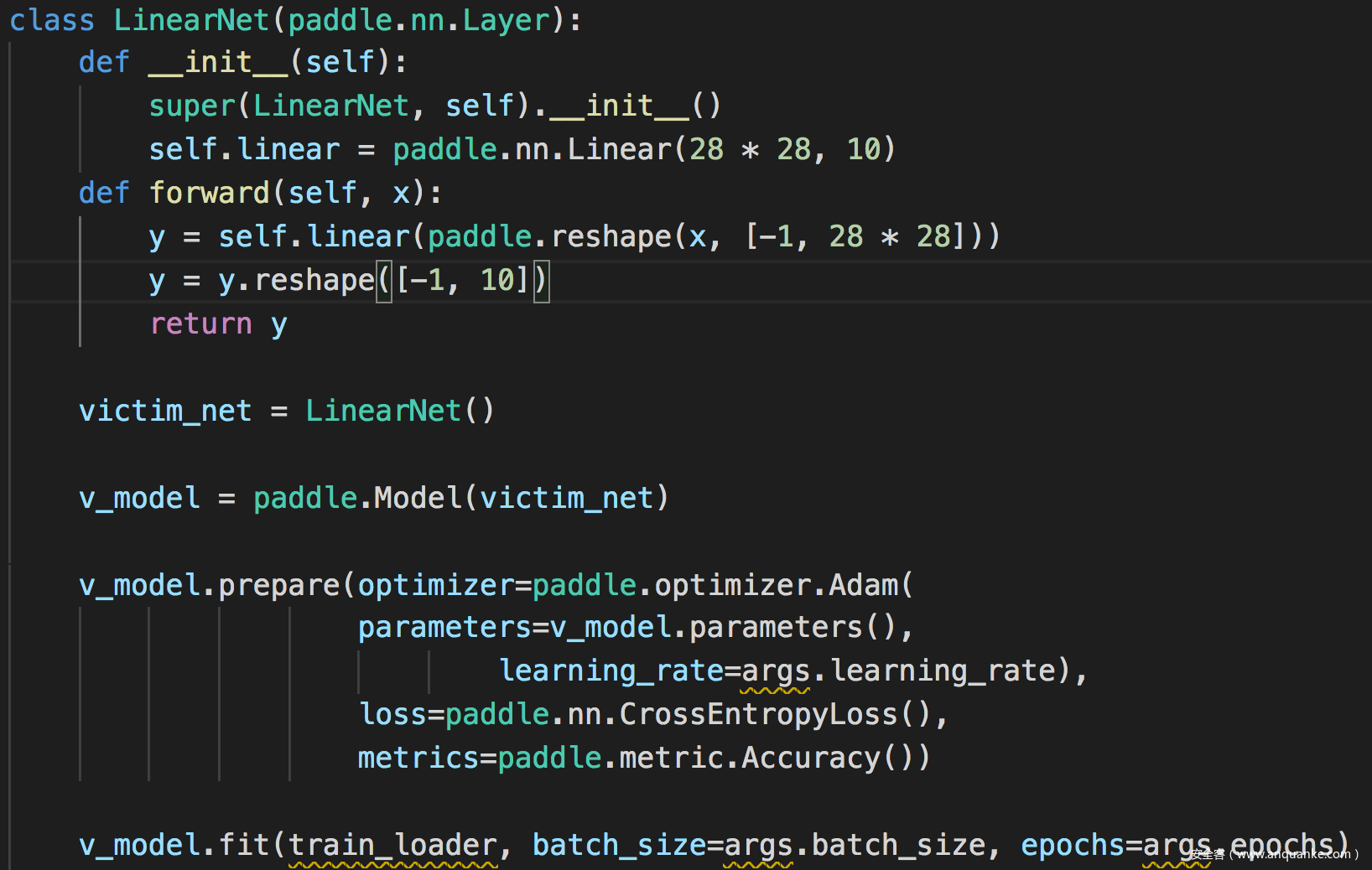
然后发动攻击

此处extract函数定义为:
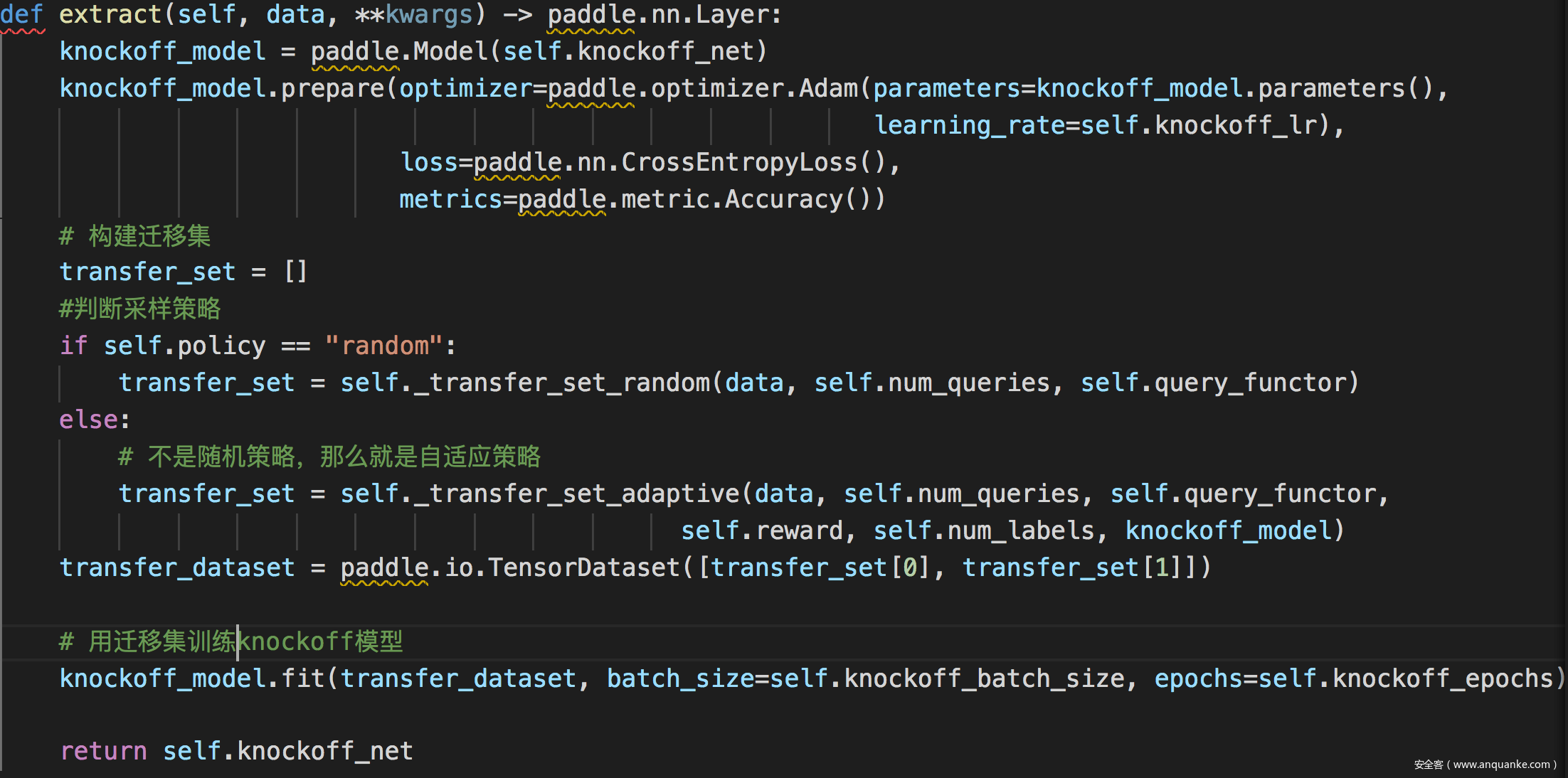
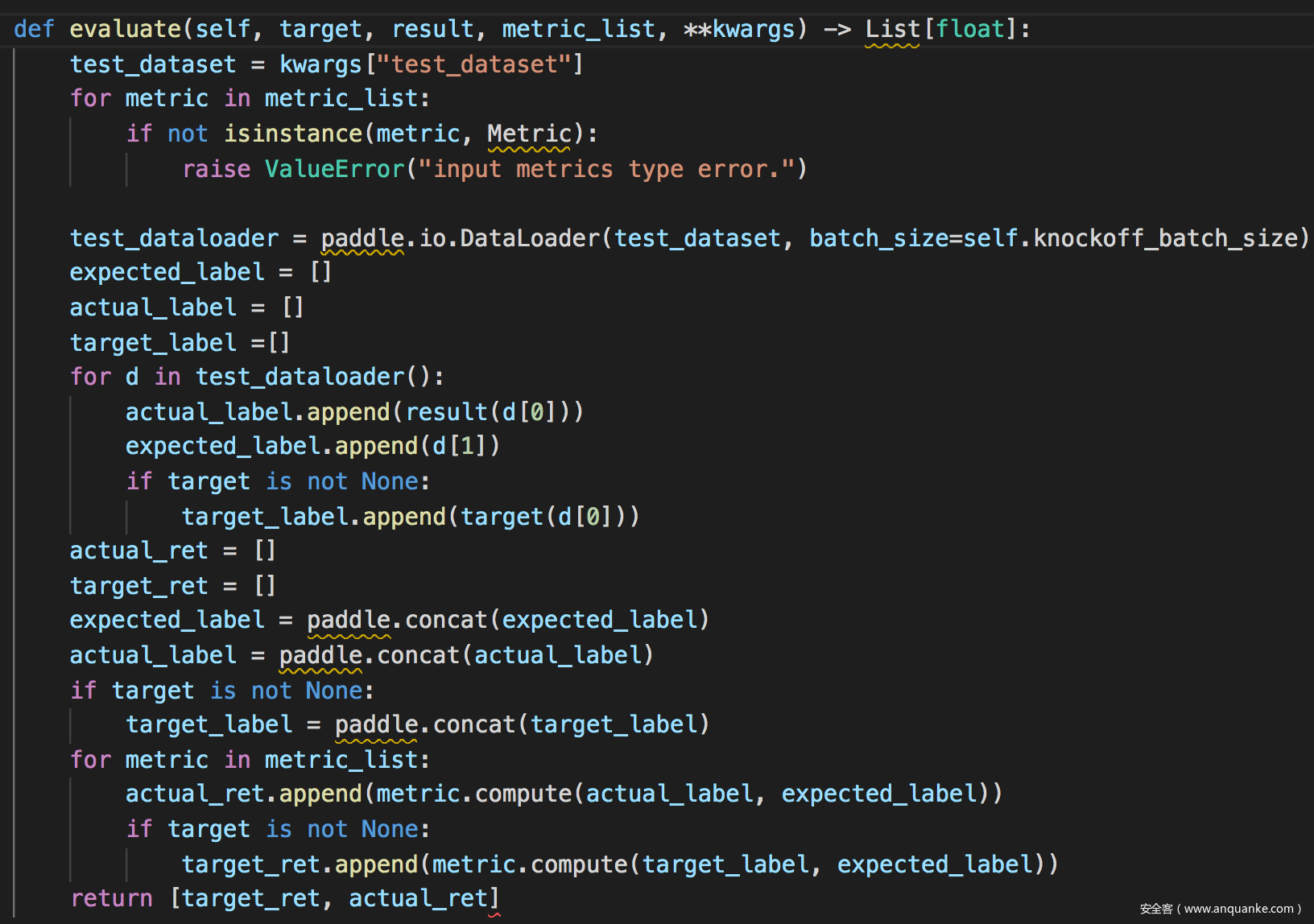
然后需要评估,这里就是简单计算模型的性能:

evaluate函数定义为:
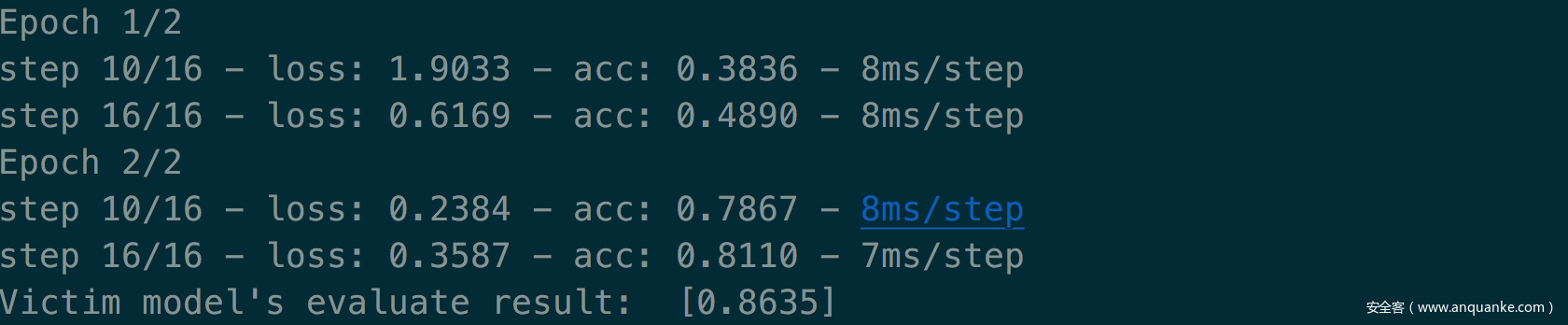
当采样策略采用随机策略时,选择mnist数据集作为攻击数据集(此时跟受害者数据集标签100%重叠),选择线性模型作为攻击模型,以此作为基准,攻击效果如下
保持与基准实验其他条件相同,不过使用resnet作为攻击模型
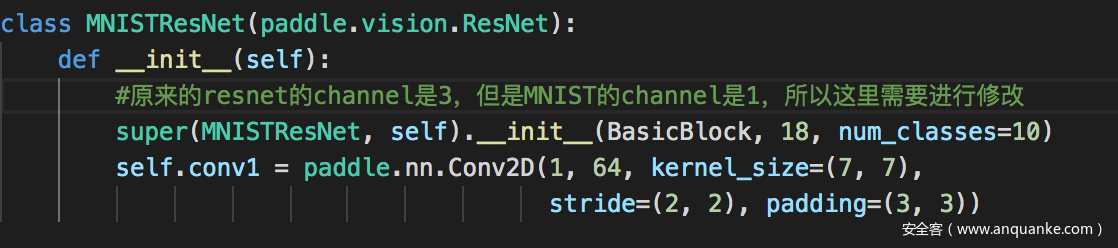
结果如下
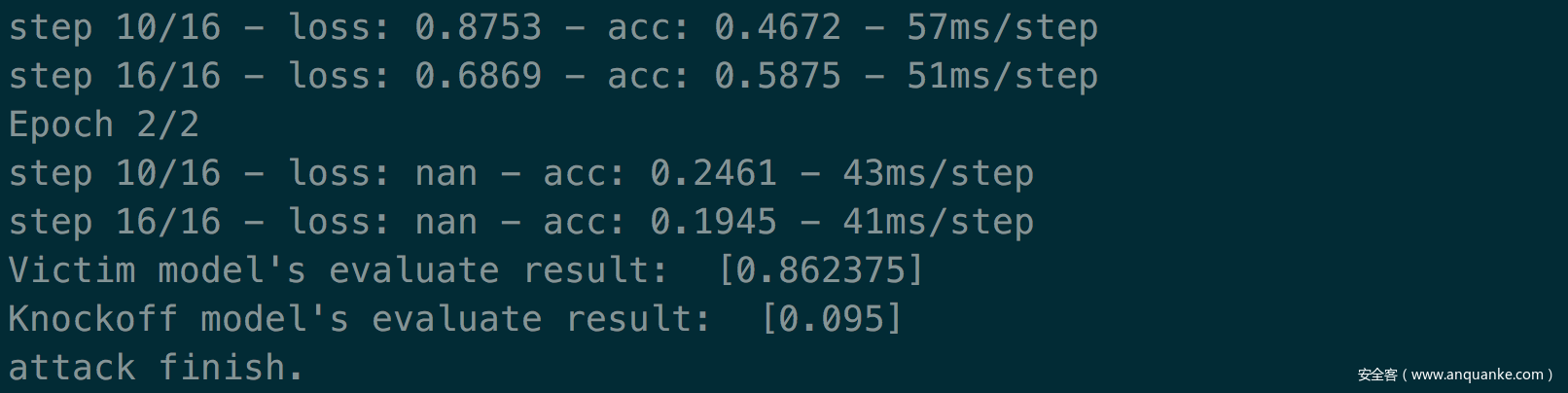
可以看到,由于攻击模型和目标模型架构完全不同,所以攻击效果很差
保持与基准实验其他条件相同,不过使用fmnist数据集作为攻击数据集(此时跟受害者数据集标签0%重叠)

效果如下
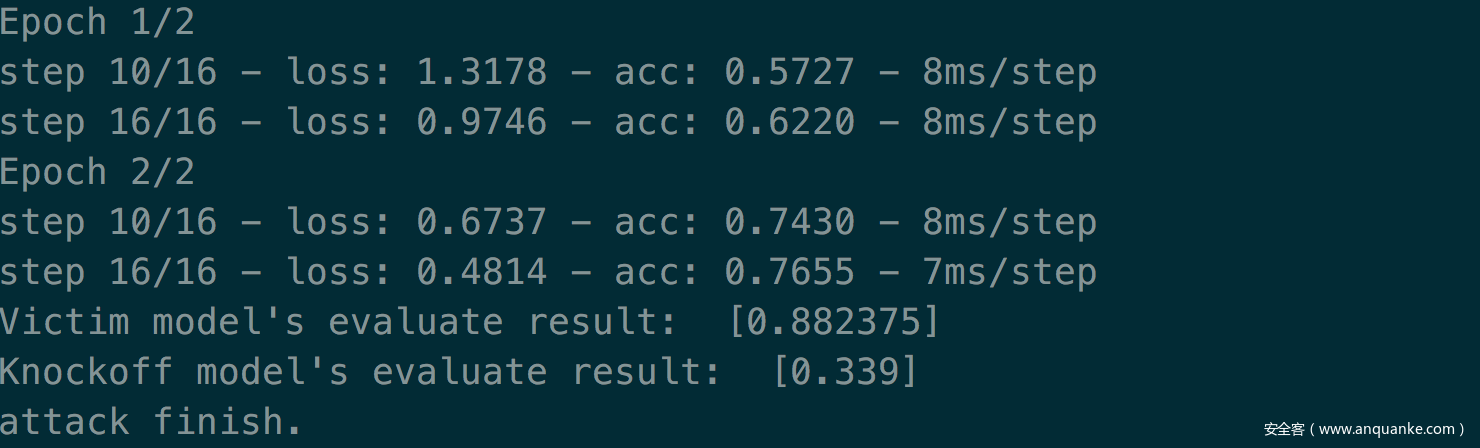
可以看到,攻击效果很差
保持与基准实验其他条件相同,不过采样策略采用自适应策略

攻击效果如下
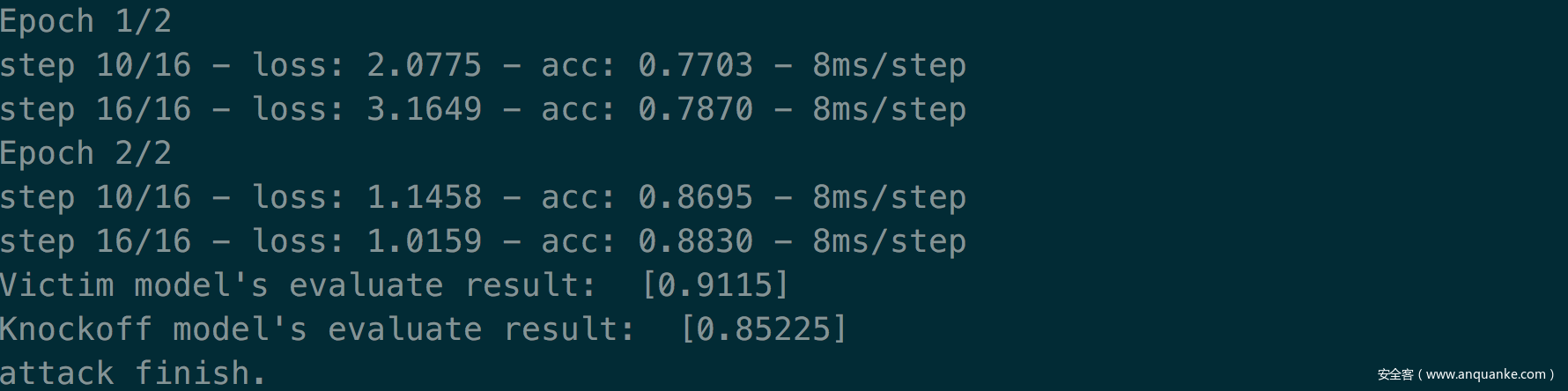
当采样策略采用自适应策略,不过仅使用loss机制时(在前文我们已经说过,存在三种损失,上一个实验我们综合了三种损失,而这个实验我们仅使用loss),攻击效果如下
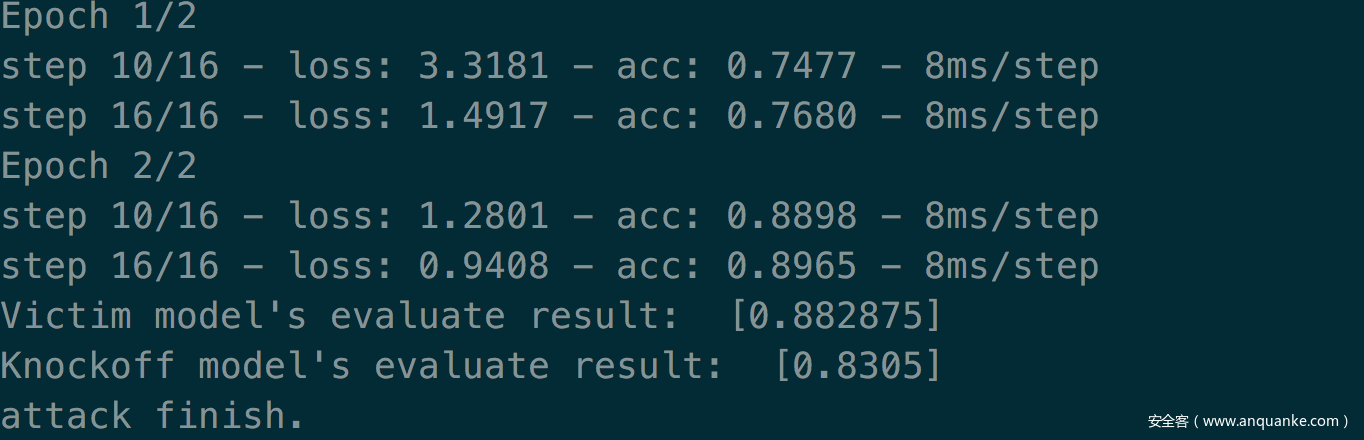
综合这两个实验可以看到当综合三种机制时,攻击效果更好
参考
1.Knockoff Nets: Stealing Functionality of Black-Box Models
2.https://github.com/PaddlePaddle/PaddleSleeve
3.Model Extraction and Defenses on Generative Adversarial Networks
4.http://www.cleverhans.io/2020/05/21/model-extraction.html
5.Model Extraction Attacks on Recurrent Neural Networks
6.Data-Free Model Extraction







发表评论
您还未登录,请先登录。
登录