
第3章动机
清单2中的虚拟示例包含了一个由于缺少exit()调用而导致的UAF bug, 这是如CVE-2014-9296, CVE-2015-7199等此类bugs的一个常见的根本原因。程序读取文件并将其内容复制到缓冲区buf中。具体来说就是,由p指向的内存块被分配(见第12行),然后p_alias和p就会变成别名(见第15行)。两个指针指向的内存会在函数bad_func中释放(见第10行)。当释放的内存再次通过p_alias被解除引用时,就会出现UAF bug(见第19行)。
bug触发条件:当且仅当输入的前三个字节是“AFU”的时候,UAF bug才会被触发。为了快速检测这个bug,模糊测试器需要通过第13、5和18行条件陈述的if部分探索正确的路径,以便依次覆盖alloc、free和use这三个UAF事件。值得注意的是,这个UAF错误不会导致程序崩溃,因此现有的无杀毒的灰盒模糊测试器不会检测到这个内存错误。
基于覆盖率的灰盒模糊测试:从空种子开始,AFL快速生成3个新输入(比如,“AAAA”、“FFFF”和“UUUU”),分别触发3个UAF事件。这类种子不会触发bug。由于从空种子生成以“AFU”开头的输入的概率非常小,因此在跟踪UAF事件序列时,即使每个事件都很容易被触发,覆盖引导机制在这里也并不管用。
定向灰盒模糊测试:给定例如由ASan生成的bug跟踪(第14行-alloc,第17、6、3行-free,,第19行-use),DGF会防止模糊测试器探索不需要的路径(例如函数func中第7行的else部分),以防第5行的条件变得更复杂。尽管如此,定向模糊测试器还是有他们自己的盲点。例如,标准的DGF种子选择机制倾向于执行跟踪覆盖目标中许多位置的种子,而不是试图按给定顺序到达这些位置。例如,对于目标(A、F、U),标准DGF距离不区分覆盖路径A→F→U的输入s1和覆盖U→A→F的另一输入s2。在探索目标位置时缺乏次序,这使得UAFbug检测对于现有的定向模糊测试器来说非常具有挑战性。又比如:HAWKEYE提出的幂函数可能会给一个跟踪没有到达目标函数的种子分配很多能量,这意味着它可能在函数func中第7行else部分的虚拟示例中丢失。
清单2:激励示例

UAFuzz 的缩影:我们特别依赖于修改种子选择启发式算法,使其与执行跟踪(见第4.2章)所覆盖的目标数相关,并将目标排序感知种子度量引入DGF(见第4.3章)。在虚拟示例中,UAFuzz生成输入以向预期目标序列前进。例如,在包含4个输入的同一模糊测试队列中,由种子“AAAA”变异生成的变异“AFAA”被AFL丢弃,因为它不会增加代码覆盖率。然而,由于与队列中先前提及的全部4个输入(其得分为0或2)相比,该突变体具有目标相似性度量得分的最大值(即,包括第14、17、6、3行的4个目标),因此UAFuzz选择该突变体用于随后的模糊化活动。通过持续模糊化“AFAA”,UAFuzz最终生成一个bug触发的输入,例如“AFUA”。
评估:AFLGO(源级,带bug追踪)无法在2小时内检测到UAF bug,而UAFuzz(二进制级,带bug追踪)却能够在20分钟内触发它。另外,当UAFuzz识别一个潜在的buggy输入(正确的PoC输入!)并发送给VALGRIND确认时,AFLGO则是发送120个输入到bug 分类器。
第4章UAFuzz方法
UAFUZZ由几个组件组成,包括种子选择、输入度量、功率调度和种子分类。在详细说明这些方面之前,让我们先从方法的概述开始。
图2:UAFuzz的概述
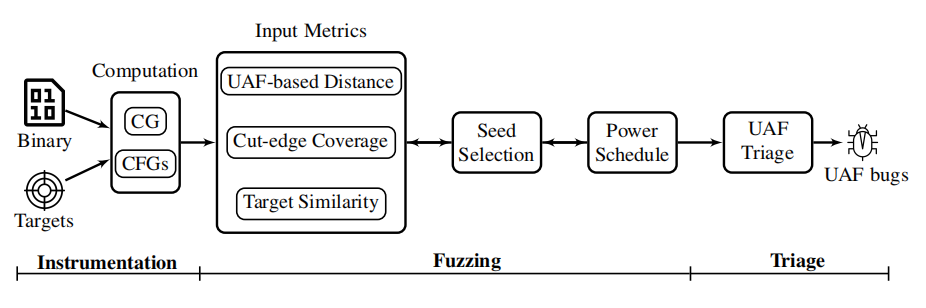
我们的目标是找到同时满足控制流(时间上的)和运行时间(空间上的)条件的输入来触发UAF bug。我们通过将UAF特性引入到DGF中来解决这个问题,以便根据UAF预期的bug跟踪生成更多依次到达目标的潜在输入。图2描绘了总体的情况。尤其是:
①我们提出了三种用于UAF漏洞检测的动态种子度量。距离度量粗略估算了种子与所有目标位置的距离有多接近,并考虑到种子执行跟踪按顺序覆盖三个UAF事件的需要。切边覆盖率度量测量了种子在重要决策节点上做出正确决策的能力。最后,目标相似性度量具体评估种子执行跟踪在运行时覆盖多少目标;
②我们的种子选择策略有利于种子在运行时覆盖更多目标。功率调度器根据模糊测试过程中每个选定种子的度量分数确定能量,详见第4.4节;
③最后,我们利用前面提及的度量来预先识别合适的PoC输入,这些输入被发送到分析工具(这里指VALGRIND)进行bug确认,从而避免了许多无用的检测。
4.1 Bug跟踪扁平化
bug跟踪是一系列堆栈跟踪,也就是即它是一个大对象,并不适合灰盒模糊测试所需的轻量级工具。我们需要从bug跟踪中提取的最有价值的信息是遍历基本块(和函数)的序列,这是一个更容易使用的对象。我们称之为提取bug跟踪扁平化。
操作如下:首先,三个堆栈跟踪中的每一个都被看作是调用树中的一条路径;因此,我们合并所有堆栈跟踪以重新创建该树。树中的一些节点有几个子节点;我们确保根据UAF事件的顺序对子节点进行排序(即,来自alloc事件的子节点先于来自free事件的子节点)。图3展示了图1中给出的bug跟踪树的示例。
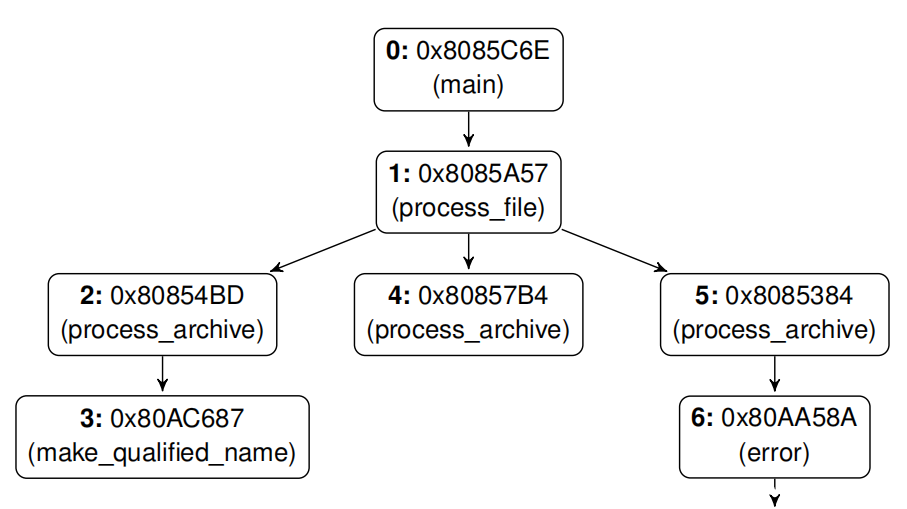
图3:CVE-2018-20623重建树(图1中的bug跟踪)。简单来说,该树的前序遍历是0→1→2→3(nalloc)→4(nfree)→5→6(nuse)。
最后,我们对这棵树进行一次前序遍历,得到一系列目标位置(及其相关函数),这些将在下面的算法中有用到。
4.2基于目标相似性的种子选择
Fuzzers生成大量的输入,因此从模糊测试队列中迅速地选择种子,以便在下一个fuzzing活动中进行变异,这对于提高效率至关重要。我们的种子选择算法基于两种见解。首先,我们应该优先处理与目标bug跟踪最相似的种子,因为定向模糊器的目标是找到覆盖目标bug跟踪的那些bugs。第二,目标相似性应该考虑排序(也就是顺序性),因为跟踪按顺序覆盖目标bug跟踪中的多个位置,比按任意顺序覆盖相同位置更接近目标。
4.2.1种子选择
定义1.最大可达输入(max-reachinginput)是一个其执行跟踪与目标bug跟踪T最为相似的输入s,其中最相似性意味着“与目标相似性度量t(s,T)相比具有最高值”。
在模糊测试过程中,我们主要选择和变异最大可达输入。然而,我们也需要提高代码覆盖率,因此UAFuzz也会选择覆盖了带小概率α(见算法1)的新路径的输入。在我们的实验中,选择模糊测试队列中不太优先的剩余输入的概率是1%,类似于AFL[1]。
算法2:IS_FAVORED:决定某一种子是否优先

4.2.2目标相似性度量
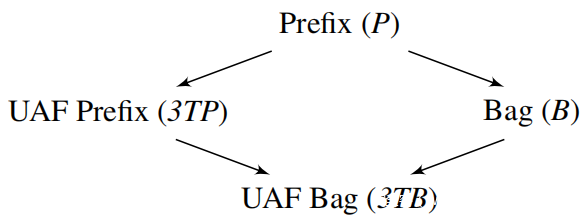
目标相似性度量t(s,T)测量种子s的执行与目标UAFbug跟踪T之间的相似性。我们定义了4个这样的度量,基于我们是否只考虑了bug跟踪(P)中覆盖目标的顺序,而不考虑(B)– P代表前缀,B代表包;我们考虑的是否为完整的跟踪,还是仅考虑了三个UAF事件(3T):
①目标前缀tP(s,T):通过执行s直到第一次发散而被T中的位置依次覆盖;
②UAF前缀t3TP(s,T):T的UAF事件通过执行s直到第一次发散而被依次覆盖;
③目标包tB(s,T):通过执行s覆盖T中的位置;
④UAF包t3TB(s,T):通过执行s覆盖T的UAF事件。
例如,使用清单2时,相对于UAF bug 跟踪 T,种子s “ABUA”的4个度量值是:tP(s,T) = 2,t3PT (s,T) = 1,tB(s,T) = 3,t3TB(s,T) = 2。
这4个度量有着不同的精确度。如果任意两个种子s1和s2:t(s1,T) ≥ t(s2,T) ⇒ t’(s1,T) ≥ t’(s2,T),则度量t比度量t’更精确。
图4比较了我们4个度量的相对精确度。
图4:目标相似性度量的精确度排阵图
4.2.3 结合目标相似性度量
使用精确的度量(如P)可以更好地评估朝着目标前进的过程。特别是,P可以从那些不匹配的种子中区分出与目标bug跟踪匹配的种子,而其他度量做不到。另一方面,不太精确的度量提供了精确度量不具备的信息。例如,P不测量后缀与目标bug跟踪所匹配的跟踪之间的任何差异,但谁会在第一个位置上(如清单2中的“UUU”和“UFU”)偏离目标跟踪呢,B便会如此。
为了从精确和非精确的度量中获益,我们用词典顺序将它们组合起来。因此,P-3TP-B度量被定义为:
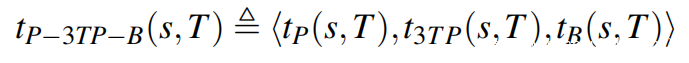
这种组合有利于首先覆盖前缀中大多数位置的种子,接着(在相同的情况下)是依次到达最多UAF事件数的种子,最后(在相同的情况下)是到达目标中最多位置的种子。在内部评估的基础上,我们默认使用P-3TP-B进行UAFuzz中的种子选择。
4.3基于UAF的距离
定向灰盒模糊测试器的主要组成部分之一是种子距离的计算,它是一项从种子s的执行跟踪到目标的距离计算。这里的主要启发是,如果s的执行跟踪接近目标,那么s接近覆盖目标的输入,这使得s成为一个有趣的种子。在现有的定向灰盒模糊测试器中,种子距离是计算到一个或一组位置的目标的距离。这不适用于UAF bug复现,它必须依次经过3个不同的位置。因此,我们建议修改种子距离计算,以考虑到按顺序到达各个地点的需要。
4.3.1 Zoom:种子距离的背景
现有的定向灰盒模糊测试器计算从种子s到目标T的距离d(s,T),如下所示。
AFLGO的种子距离[2]。种子距离d(s,T)被定义为s的执行跟踪中每个基本块m的基本块距离db(m,T)的(算术)平均值。
基本块距离db(m,T)是使用从m到“call”指令的基本块的过程内最短路径的长度来定义的,使用包含m的函数的CFG;以及使用调用图从包含m的函数到目标函数Tf(在我们的示例中,Tf是发生use事件的函数)的过程内最短路径的长度。
HAWKEYE的增强。这种种子距离计算的主要因素是计算调用图中函数之间的距离。为了计算这个值,AFLGO使用了每个边的权重为1的原始调用图。HAWKEYE通过提出增加的相邻函数距离(AAFD)改进了这种计算,AAFD将调用函数fa和被调用函数fb的边权值改为wHawkeye(fa, fb)。这个想法有利于调用图的边,在调用图中,被调用方可以在各种情况下被调用,即在不同的位置出现多次。
4.3.2 我们的基于UAF的种子距离
前面提及的种子距离没有考虑目标位置之间的任何顺序,但这对于UAF却是必不可少的。我们通过修改调用图中函数之间的距离来解决这个问题,以优先选择依次通过bug跟踪的三个UAF事件alloc、free和use的路径。这是通过使用轻量级静态分析降低调用图中可能在这些事件之间的边的权重来实现的。
此分析首先计算Ralloc、Rfree和 Ruse,即在bug跟踪中可以分别调用alloc、free或use函数的函数集 – use函数是发生use事件的函数集。然后,我们认为fa和fb之间的每个调用边都指示一个方向:要么向下(fa执行,然后调用fb),要么向上(fb被调用,然后执行fa)。使用此方法我们计算出,对于每个方向,通过沿该方向的边可以覆盖序列中的多少个事件。例如,如果fa∈Ralloc和fb∈Rfree∩Ruse,则取fa→fb调用边可能允许按顺序覆盖这三个UAF事件。为了找到double free,我们在这个计算中还包括允许按顺序到达两个free事件的调用边。
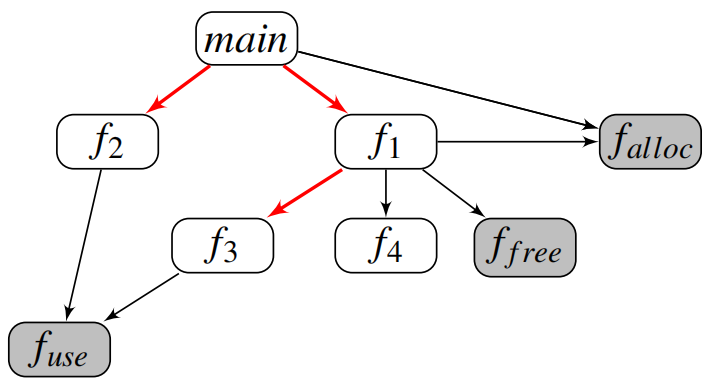
图5:调用图的示例,优先的边是红色的
然后,根据边允许覆盖的顺序事件的数量,我们通过降低其权重来优先选择从fa到fb的调用边。在我们的实验中,我们使用以下的ΘUAF(fa, fb)函数,β的值为0.25:
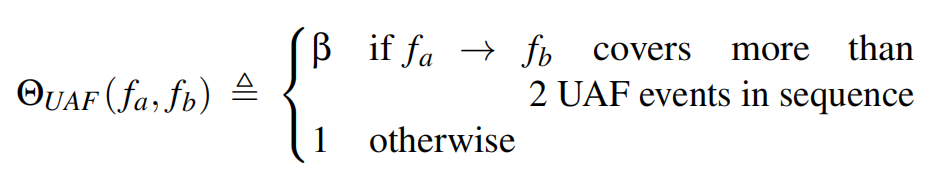
图5给出了一个使用上述ΘUAF函数的边优先的调用图示例。
最后,我们将我们的边权重修改与HAWKEYE的边权重修改结合起来:

像AFLGO一样,我们优先用到达目标最短的路径,因为它更可能只涉及少量的控制流限制,从而更容易被模糊化覆盖。因此,我们的基于距离的技术一般既考虑通过wHawkeye的调动关系,又考虑通过UAF依次覆盖UAF事件的调用关系。
4.4 功率调度
覆盖引导模糊器采用功率调度(或能量分配)来确定从选定输入中生成的额外输入的数量,这称为种子能量。它衡量我们应该花多长时间去模糊测试一个特定的种子。AFL[1]主要使用跟踪的大小、PUT的执行速度和添加到模糊测试队列中的时间等执行跟踪的特性来分配种子能量,而近来,包括定向和覆盖引导的模糊测试工作,提出了不同的功率调度。AFLGO采用模拟退火算法来为更接近目标位置的种子分配更多的能量(使用种子距离),而HAWKEYE则通过基于跟踪距离和函数级相似性的功率调度来解释通向目标的较短和较长的跟踪。
我们在这里提出了一个利用直觉的新的功率调度,在这些情况下,我们应该给种子分配更多的能量:
算法3:

算法4:

①更接近的种子(利用种子距离,见第4.3.2节);
②与目标更相似的种子(利用目标相似性,见第4.2.2节);
③在关键代码连接处做出更好决策的种子。
我们在下文中定义了一个新的度量来评估后一种情况。
4.4.1切割边缘覆盖率度量
为了在模糊测试过程中跟踪种子的进度,细粒度的方法将包含在插桩执行中,以便在基本块级别比较当前种子的执行跟踪与目标错误跟踪的相似性。但是由于运行时开销太大,这种方法会减慢模糊测试的速度,特别是对于大型程序。另一方面,如HAWKEYE所建议的,用一种更粗粒度的方法在函数级别测量相似性。然而,被调用方可以从单个调用方的不同位置多次出现。此外,到达目标函数并不意味着到达该函数中的目标基本块。
因此,我们提出了轻量级的切边覆盖率度量,是通过在边缘层测量进度(但仅在关键决策节点上测量进度),从而在上述两种方法之间找到一个中间点。
定义2:两个基本块源和汇之间的切边是决策节点的传出边,因此存在一条从源开始、经过该边并到达汇的路径。“非切边”是指不是“切边”的边,即没有从源到汇的路径穿过该边。
算法3显示了在给定一个经过测试的二进制程序和一个预期的UAF bug跟踪的情况下,如何在UAFuzz中识别切边和非切边。主要想法是识别并累积(扁平化)bug跟踪中所有连续节点之间的切边。例如,在图3的bug跟踪中,我们首先计算0到1之间的切边,然后计算1到2之间的切边,以此类推。由于bug跟踪是一系列堆栈跟踪,跟踪中的大多数位置都是“call”事件,因此我们计算从函数入口点到该函数中调用事件的切边。但是,由于扁平化,有时我们必须计算同一函数中不同点之间的切边(例如,如果在bug跟踪中,同一个函数调用alloc和free,我们则必须计算从alloc调用到free调用的边)。
算法4描述了如何在单个函数中计算切边。首先,我们必须收集决策节点,即源和汇基本块之间的条件跳转。这可以通过简单的数据流分析来实现。对于决策节点的每个传出边,我们检查它们是否允许到达sink基本块;哪些可以是切边,其他的则是非切边。注意,这个程序分析是程序内的,所以我们不需要构造一个程序内CFG。
我们的启发式是,使用更多切边和更少非切边的输入更有可能覆盖目标的更多位置。(听起来很拗口,读多两遍,其实很容易理解)假设Ecut(T)是给定预期UAF bug跟踪T的程序的所有切边的集合。我们定义种子s的切边得分es(s,T)为:

其中hit(e)表示边e被运用的次数,δ∈(0,1)则是覆盖非切边的惩罚种子的权重。在我们的主要实验中,根据我们的初步实验,我们使用δ = 0.5。为了处理环路引起的路径爆炸,我们还使用了AFL中的bucketing方法(也就是说,命中数被调整为二次幂)。
4.4.2能量分配
我们提出了一个功率调度函数,该函数使用我们提出的三个度量(指标)的组合为种子分配能量:前缀目标相似性度量tP(s,T)(第4.2.2节),基于UAF的种子距离d(s,T)(第4.3.2节),以及切边覆盖率度量es(s,T)(第4.4.1节)。我们的功率调度的想法是根据tP(s,T)序列中覆盖的目标数按比例分配能量给一个种子,并根据种子距离d和切边覆盖率es来确定校正因子。实际上,我们的幂函数(对应于算法1中的ASSIGN_ENERGY)被定义为:
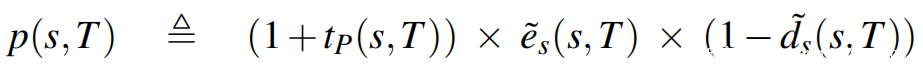
由于它们的实际值不如覆盖前缀的长度有意义,但它们允许对种子进行排序,因此我们应用最小-最大规格化[2]来获得规格化种子距离(d˜s(s,T))和规格化切边得分(e˜s(s,T))。
例如, 其中minD,maxD表示目前种子距离的最小值和最大值。注意,两个度量分数都在(0, 1),之间,也就是说,只有当分数不好时,才能减少分配的能量。
其中minD,maxD表示目前种子距离的最小值和最大值。注意,两个度量分数都在(0, 1),之间,也就是说,只有当分数不好时,才能减少分配的能量。
4.5 后处理和错误分类
由于UAF bug通常是隐晦的,因此由定向模糊器生成的所有种子必须先验发送到bug 分类器(通常是像VALGRIND这样的分析工具),以确认它们是否是触发输入的bug。然而,这可能是非常昂贵的,因为模糊测试器会生成大量的种子,且bug分类器也很贵。
幸运的是,目标相似性度量允许UAFuzz在运行时计算每个模糊化输入的覆盖目标的序列。一旦创建并执行了每个种子,就可以免费获得这条信息。我们充分利用它来预先识别触发疑似bug的种子,也就是说,依次覆盖三个UAF事件的种子。然后,bug分类器只在这些预先确定的种子上运行,其他种子则回被直接丢弃 — 这可能会节省大量的bug分类的时间。
参考(部分):
[1] Aflfl. http://lcamtuf.coredump.cx/afl/, 2020.
[2] Aflflgo. https://github.com/aflgo/aflgo, 2020.
[3] Aflflgo’s issues. https://github.com/aflgo/aflgo/issues, 2020.
[4] Binsec. https://binsec.github.io/, 2020.
[5] Circumventing fuzzing roadblocks with compiler transformations.https://lafintel.wordpress.com/2016/08/15/circumventing-fuzzing-roadblocks-with-compiler-transformations/, 2020.
[6] Cve-2018-6952. https://savannah.gnu.org/bugs/index.php?53133,2020.
[7] Darpa cgc corpus.http://www.lungetech.com/2017/04/24/cgc-corpus/,2020.
[8] Double free in gnu patch. https://savannah.gnu.org/bugs/index.php?56683, 2020.
[9] Dr.memory. https://www.drmemory.org/, 2020.
[10] Gnu patch. https://savannah.gnu.org/projects/patch/, 2020.
[11] Google fuzzer testsuite. https://github.com/google/fuzzer-test-suite, 2020.
[12] Gueb: Static analyzer detecting use-after-free on binary. https://github.com/montyly/gueb, 2020.
[13] Ida pro. https://www.hex-rays.com/products/ida/, 2020.
[14] Libfuzzer. https://llvm.org/docs/LibFuzzer.html, 2020.
[15] OSS-Fuzz: Continuous Fuzzing Framework for Open-Source Projects.https://github.com/google/oss-fuzz/, 2020.
[16] Oss-fuzz: Five months later, and rewarding projects.https://opensource.googleblog.com/2017/05/oss-fuzz-five-months-later-and.html, 2020.
[17] Rode0day. https://rode0day.mit.edu/, 2020.
[18] Sockpuppet: A walkthrough of a kernel exploit for ios 12.4.
https://googleprojectzero.blogspot.com/2019/12/sockpuppet-walkthrough-of-kernel.html, 2020.
[19] Uaf fuzzing benchmark.https://github.com/uafuzz/UAF-FuzzBench, 2020.
[20] Us national vulnerability database.https://nvd.nist.gov/vuln/search, 2020.







发表评论
您还未登录,请先登录。
登录