
第5章. 实现
图6:UAFuzz工作流程概述
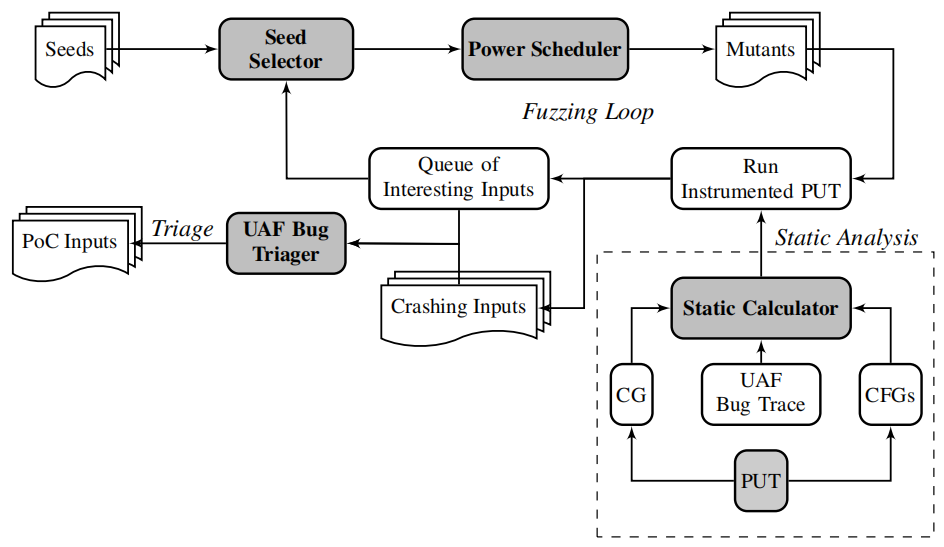
我们在一个叫UAFuzz的面向UAF的二进制级定向模糊测试器中实现了我们的成果。图6描述了UAFuzz主要组件的概述。整个系统的输入是一组初始种子,是从bug跟踪中提取的二进制和目标位置的PUT。而输出则是一组特有的bug触发输入。原型是建立在AFL 2.52b和QEMU 2.10.0 的基础上来进行模糊测试,而二进制分析平台BIN-SEC则是用于进行(轻量级)静态分析。
这两个主要组件共享了目标位置、时间预算和模糊测试状态等信息。
①我们已经实现了一个BINSEC插件来计算静态距离和切边信息,因此在UAFuzz仪器中使用 – 需注意,调用图和CFG是从IDA PRO二进制数据库(IDA PRO version 6.9)中检索而来的;
②在动态方面,我们对 AFL-QEMU进行了改进,以跟踪覆盖目标,动态计算种子得分和幂函数;
③最后,一个小脚本会让bug分类自动化。
内存开销:UAFuzz在运行时使用20个额外的共享内存字节:类似于最先进的基于源的DGF,我们使用8个字节来累积距离值,使用8个字节来记录用于存储当前种子距离的已执行的基本块数量,再加上用于当前种子目标跟踪的4个额外字节。
第6章. 实验评价
6.1研究课题
为了评估我们方法的有效性和效率,我们调查了四个主要研究课题:
RQ1:UAF bug复现能力。在可执行文件中的UAF bug复现方面,UAFuzz能否优于其他定向fuzzing技术?
RQ2:UAF开销。在检测时间和运行时开销方面,UAFuzz与其他定向fuzzing方法相比如何?
RQ3:UAF 分类。UAFuzz在多大程度上减少了发送到bug分类步骤的输入数量?
RQ4:个体贡献。每个单独的组件对UAFuzz的总体结果有多大的贡献?
前三个问题与现有的定向模糊测试技术相比,评估了UAFuzz的模糊化性能,而最后一个问题则旨在对UAFuzz背后的原理进行更精细的评估。最后,我们还在补丁测试环境中评估UAFuzz,因为它是定向fuzzing的另一个重要应用。
6.2安装设置评价
模糊测试器评价:我们的目的是用AFL-QEMU作为基准(二进制级基于覆盖率的模糊测试),将UAFuzz和最先进的定向模糊测试器(即AFLGO和 HAWKEYE)进行对比。遗憾的是,AFLGO和HAWKEYE都是作用于源代码的,虽然AFLGO是开源的,HAWKEYE却不可用。因此,我们实现了AFLGO和HAWKEYE的二进制版本,创造了AFLGOB和HAWKEYEB。我们密切关注原始文件,对于AFLGO,使用了源代码作为参考。基本上,AFLGOB和HAWKEYEB是在AFL-QEMU的基础上实现的,遵循UAFuzz的一般架构,但具有专用的距离、种子选择和功率调度机制。表2总结了我们对不同模糊测试器的实操和与原始对应对象的比较。
表2:灰盒模糊测试器的主要技术概述。我们自己的实现带有*标记。

我们评估了AFLGOB(见第6.3节)的实现,经过核算模拟开销后,发现它非常接近原始AFLGO。
UAF模糊测试基准:用于静态分析的标准UAF微观基准Juliet Test Suite,
对fuzzing来说过于简单。没有一个宏基准真实地评估了UAF检测器的有效性——广泛使用的LAVA也只包含了缓冲区溢出。因此,我们根据以下的原理来构建一个新的UAF基准:
①主题是真实的流行的以及相当大的安全关键程序;
②这个基准包括了现有的模糊测试器从模糊测试文献中发现的或从NVD中收集的UAF bugs。尤其是,我们包含了所有由定向模糊测试器发现的UAF bugs;
③bug报告提供了详细的信息(例如,buggy版本和堆栈跟踪),以便我们可以识别模糊测试器的目标位置。
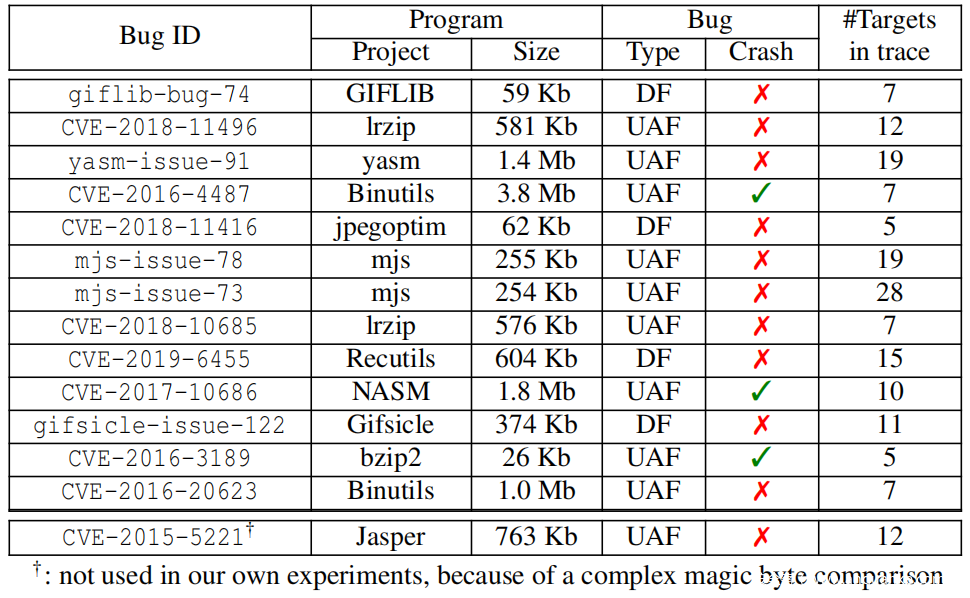
总之,我们有14个UAF漏洞(2个来自定向模糊测试器),超过12个真实的C程序,其大小在26 Kb至3.8 Mb不等。此外,选定的程序范围从图像处理到数据存档、视频处理和网络开发。因此,我们的基准代表了真实程序中不同的UAF漏洞。
表3概述了我们的基准(更多细节见附录A表5)。此外,第7节中的表4提供了与现有模糊测试基准的比较。请注意,我们在实验中并没有使用CVE-2015-5221,因为对所有被测试的定向模糊器来说,使用magic byte比较要么太难(24小时内无字典),要么太容易(使用有效的MIF种子)。
评价配置:我们遵循模糊化评估的建议,并在所有实验中使用相同的模糊化配置和硬件资源。实验进行了10次,时间预算取决于表5所示的PUT。我们使用空文件或开发人员提供的现有有效文件作为输入种子。我们没有使用任何令牌字典。所有实验均在具有32GB RAM和Intel Xeon CPU E3-1505M v6 @ 3.00GHz CPU 的Ubuntu 16.04 64位操作系统上进行。
表3:UAF模糊测试基准概述
6.3 UAF bug复现能力(RQ1)
图7:模糊测试性能总结(RQ1)
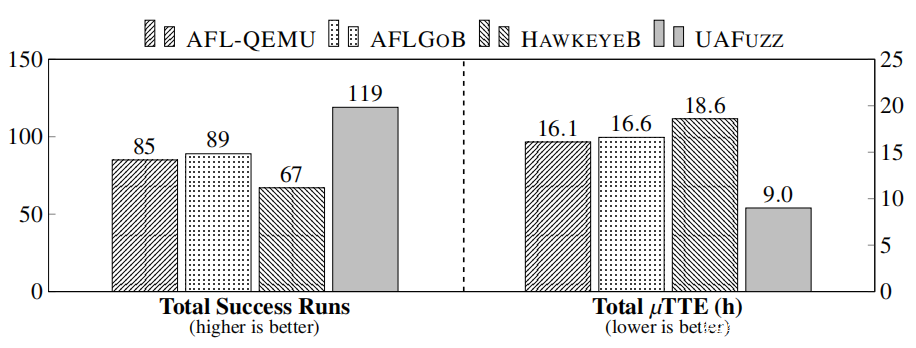
协议:我们使用 TTE(time to exposure)在13个UAF漏洞上比较不同的fuzzers (不使用recall Jasper),即第一个bug触发输入之前的时间,以及fuzzer触发bug的成功运行次数。如果fuzzer无法在时间预算内检测到bug,则将运行的TTE设置为时间预算。在现有工作之余,我们使用Vargha-Delaney 统计(Aˆ12)度量来评估一个工具优于另一个工具的可信度。请注意,代码覆盖率与评估定向模糊测试器的功能无关。
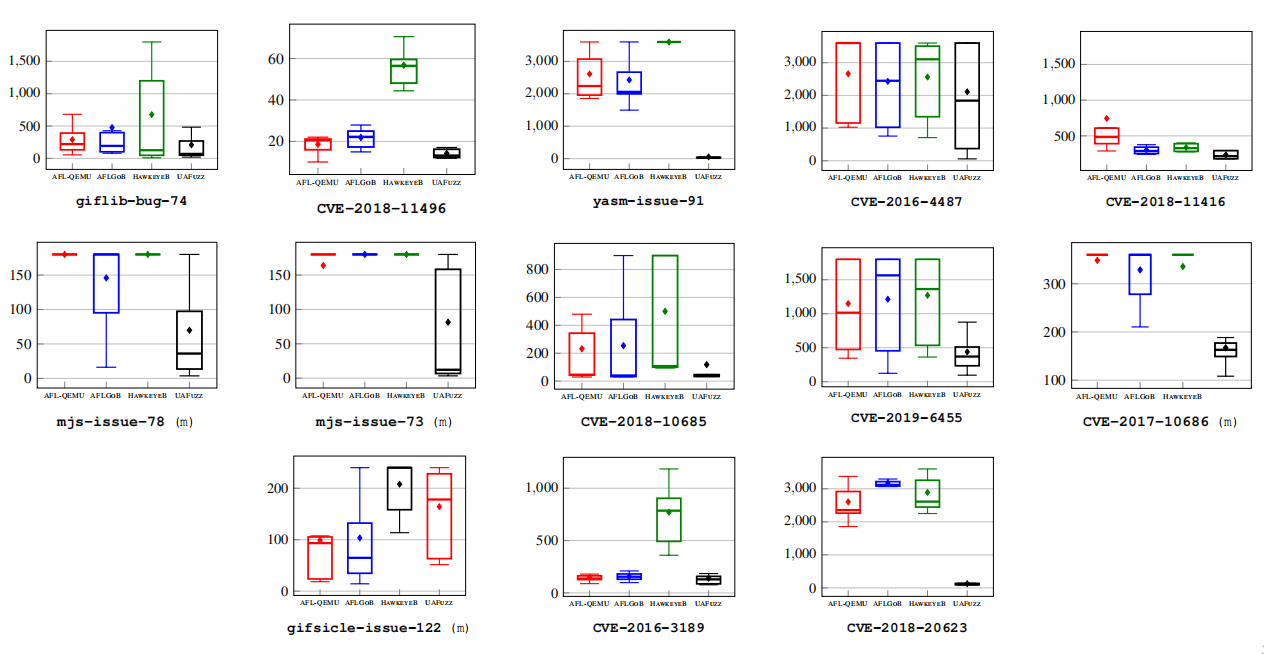
结果:图7显示了研究结果的综合视图(总成功运行率和TTE——我们用μTTE表示每个运行10次以上的样本的平均TTE)。附录B包含附加信息:每个基准样本(见表8)的详细统计数据、合并的Vargha-Delaney统计数据(见表6)和显示TTE变化(见图18)的箱线图。
图8:4个模糊测试器相对于我们的基准的模糊测试性能总结,由于AFLGO的编译问题CVE-2017-10686除外。
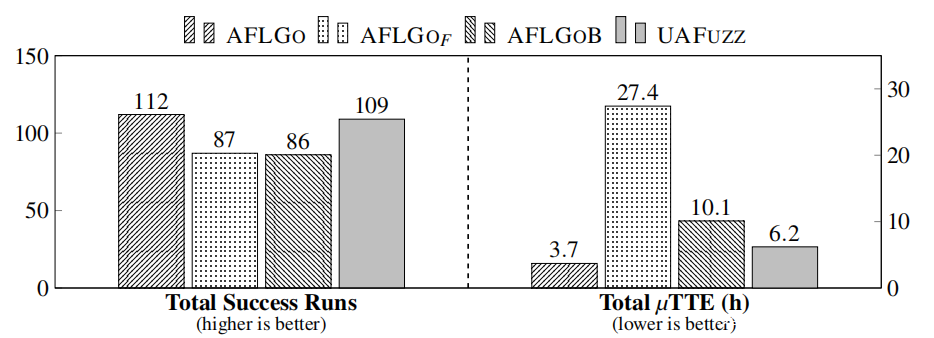
图7(以及表6和表8)显示,无论是在总成功运行率(与第二名的AFLGOB相比,总成功率+34%,高达+300%),还是在TTE(与第二名的AFLGOB相比,总成功率:2倍,平均成功率:6.7倍,最大成功率:43倍)方面,UAFuzz都明显优于其他fuzzers。在某些特定情况下(见表8),UAFuzz比AFLGOB节省了大约10000秒TTE,或者从0/10的成功率上升到7/10。如表6所示,UAFuzz相对于其他fuzzers的Aˆ12值也显著高于常规的大效应量0.71(与第二名的AFLGOB相比,平均值:0.78,中位数:0.80,最小值:0.52)。图18(见附录)最后显示了UAFuzz具有更稳定的性能。
| UAFuzz在UAF bug复现方面明显优于最先进的定向模糊测试器,这一结论有极高的可信度。 |
备注:我们可以注意到HAWKEYEB在这里的表现明显比AFLGOB和UAFuzz差。我们研究了这一点,发现这主要是由于计算目标相似性度量花费了大量运行时开销。实际上,根据HAWKEYE的原始文献,这种计算涉及到被测代码中函数总数的一些二次计算。在我们的样本中,这个数字很快显得很重要(高达772个),而目标(UAFuzz)的数量仍然很小(高达28个)。举几个例子:CVE-2017-10686:772个函数对应10个目标;gifsicle-issue-122:516个函数对应11个目标;mjs-issue-78:450个函数对应19个目标。
题外话:与基于源的AFLGO比较。我们希望评估我们对AFLGOB的实施与原始的AFLGO有多么接近,以便评估我们对研究结果的信任度–由于HAWKEYE不可用,我们就不对HAWKEYEB展开此操作了。
AFLGO的性能优于AFLGOB和UAFuzz(图8,附录中的表7),这不足为奇。这主要是因为QEMU的模拟运行时开销,这是一个有据可查的事实。尽管如此,令人惊讶的是,在4个样本中UAFuzz能比AFLGO更快地找到bugs,证明了它的有效性。然而,更有趣的是,图8还显示了,一旦考虑到模拟开销(产生AFLGOF,AFLGO预期的二进制级性能),那么AFLGOB与AFLGOF一致(甚至显示更好的TTE)–UAFuzz甚至显著优于AFLGOF。
| 一旦考虑到QEMU开销,AFLGOB的性能与原始AFLGO是一致的,都允许与UAFuzz进行公平比较。尽管如此,与基于源的定向模糊测试器AFLGO相比,UAFuzz在UAF上的性能相对较好,这体现了我们最初的模糊测试机制的优点。 |
6.4 UAF开销(RQ2)
图9:整体开销(RQ2)

协议:我们对(1)检测时间开销和(2)运行时开销都感兴趣。对于(1),我们简单地计算出UAFuzz的总检测时间,并将其与AFLGO的检测时间进行比较。对于(2),我们计算每秒执行UAFUZZ的总数,并将其以AFL-QEMU作为基准进行比较。
结果:图9显示了检测时间和运行时开销的整合结果(每秒执行的次数被在同一时间预算内执行的总次数所代替)。附加结果(见附录C)包括详细的检测时间(见图13)和运行时统计数据(见图15),以及AFLGOB和HAWKEYEB的检测时间(见图14)。
①图9和图13显示,在测试阶段,UAFuzz比最先进的基于源的定向fuzzer AFLGO快一个数量级(总共快14.7倍)。例如,UAFuzz处理二进制的大型程序readelf只需23秒(比AFLGO少64倍);
②图9和图15显示,UAFuzz每秒的执行总数几乎与AFL-QEMU(总共:-4%,平均:-12%)相同,这意味着它的开销可以忽略不计。
详细结果(见附录的图14)显示,HAWKEYEB有时明显慢于UAFuzz(2倍)。这主要是因为在具有许多函数的大型示例上(参见第6.3节)计算目标函数跟踪闭包的成本。
| UAFuzz拥有轻量级的检测时间和最小的运行时开销。 |
6.5 UAF分类(RQ3)
图10:bug分类摘要(RQ3)

协议:我们考虑到分类输入的总数(发送到分类步骤的输入数)、分类输入率TIR(生成的输入总数与发送到分类步骤的输入总数之比)和总分类时间(在分类步骤内花费的时间)。由于在模糊测试过程中其他模糊测试器无法识别到达目标的输入,因此我们在bug分类步骤(TIR=1)中保守地分析了这些模糊测试器生成的所有输入。
结果:整合结果如图10所示,详细结果如附录D表中9和图16所示。
①UAFuzz的总TIR为9.2%(平均值:7.25%,中位数:3.14%,最佳值:0.24%,最差值:30.22%)——保留99.76%的输入种子以供确认,除样品mjs外,始终小于9%;
②图16显示,UAFuzz在bug分类中花费的时间最小,即75秒(平均值:6秒,最小值:1秒,最大值:24秒),总加速比AFLGOB(最大值:130倍,平均值:39倍)高17倍。
| UAFuzz在后处理阶段减少了很大一部分(即90%以上)的分类输入。随后,UAFuzz在这一步骤中只花了几秒钟,与标准的定向fuzzer相比赢得了一个数量级。 |
6.6 个体贡献(RQ4)
协议:我们比较了原型的四个不同版本,相当于AFLGO和UAFuzz之间的一个连续体:(1) 以AFLGOB为代表的基本AFLGO;(2) AFLGOB–ss将我们的种子选择指标添加到AFLGOB;(3) AFLGOB–ds将基于UAF的函数距离添加到AFLGOB–ss;(4) UAFuzz将我们专用功率调度添加到AFLGOB-ds。我们考虑到前面提及的RQ1指标:成功运行数、TTE和Vargha-Delaney。我们的目标是评估这些技术改进是否会引起模糊测试性能的改进。
结果:成功运行和TTE的整合结果如图11所示。附录E包含了详细结果和Vargha-Delaney度量(见表10)。
如图11所示,我们可以观察到每个新组件的TTE和成功运行的次数都有所提高,这确实引致了模糊测试的改进。表10中Aˆ12值的详细结果显示了相同的明显趋势。
| 基于UAF的距离计算、功率调度和种子选择启发式分别有助于提高模糊测试性能,并将它们结合起来进一步改进,这证明了它们的优势和互补性。 |
6.7补丁测试和零日漏洞(零时差攻击)
补丁测试是DGF的另一个关键的实际应用。我们的想法是使用已知UAF bug的bug堆栈跟踪来指导PUT补丁版本的测试,而不是bug复现中的buggy版本。从漏洞挖掘的角度来看,好处是既可以尝试寻找buggy或不完整的补丁,又可以将测试的重点放在代码的先验薄弱部分,这可能会发现与补丁本身无关的bugs。
怎么做:我们遵循漏洞挖掘惯例。从最近对外公开的开源程序的UAF bugs开始,我们在所报告的bug堆栈跟踪中人工识别自代码进化以来相关调用指令的地址。我们关注3个被开发人员很好地模糊化和维护的广泛使用的安全关键程序,即GNU补丁、GPAC和Perl 5(总共73.7万行C代码和5个已知的bug跟踪)。
结果:总体来说,UAFuzz在GNU补丁、GPAC和Perl 5中发现并报告了5个新的UAF bugs和15个来自不同bug类的新bugs(详细信息见附录F,表11)。所有这些bugs都被证实了,20个bugs中有14个已经由开发者修复。想不到的是,在GNU补丁中发现的bug实际上是一个buggy补丁(见附录F)。
| UAFuzz已经在补丁测试背景下被证明是有效的,它在3个广泛使用的安全关键程序中发现20个未知漏洞。 |
6.8 效度威胁
实现:我们的原型是作为二进制级代码分析框架BINSEC的一部分实现的,它的效率和鲁棒性已经在先前的对抗性代码和托管代码的大规模研究中得到了证明,并且在流行的模糊测试器AFL-QEMU之上。UAFuzz的有效性和正确性已经通过实际程序中的几个bug跟踪以及Juliet Test Suite中的小样本进行了评估。已人工检查所有报告的UAF bugs。
基准:我们的基准是建立在真实代码和真实bugs的基础上的,它包含了近来著名开源代码的模糊测试技术发现的几个错误(包括由定向模糊测试器发现的所有UAF bugs)。目前,它是UAF模糊测试的最佳可用基准,见表5。
竞争对手:我们认为最先进的定向模糊测试技术,即AFLGO和HAWKEYE。遗憾的是,HAWKEYE不可用,AFLGO只对源代码有效。因此,我们选择在自己的二进制级模糊测试框架中重新实现这些技术。我们尽可能地密切关注可用的信息(可公开获得时的文章和源代码),并尽最大努力获得这两种技术的精确实现。再次申明,这些实现已经在实际程序和小样本上进行了检验,而且与AFLGO源(见第6.3节)的比较表明了,我们自己的AFLGO实现与原始实现是一致的。
第七章相关工作
定向灰盒模糊测试。我们前面已经讨论过AFLGO和HAWKEYE了。LOLLY提供了一个轻量级检测工具来测量输入的序列基本块覆盖率,但代价是运行时开销很大。SEEDEDFUZZ试图生成一组初始种子,以提高定向模糊测试性能。SEMFUZZ利用与漏洞相关的文本(如CVE报告)来指导模糊测试。1DVUL通过二进制补丁发现1-day漏洞。
UAFuzz是第一个针对UAF bug量身定制的定向模糊测试器,以及少数几个能处理二进制代码的fuzzer之一。
基于覆盖率的灰盒模糊测试。AFL是一种具有重大意义的覆盖率引导的灰盒模糊测试器。在过去的几年里,已经进行了大量的努力来改善它。此外,我们在将模糊测试与其他方法相结合方面,已经投入了大量努力,如静态分析、动态污点分析、符号执行或机器学习。
我们的技术与所有这些改进都是正交的,它们可以在UAFuzz中按原样重复使用。
UAF检测。精确的静态UAF检测是很困难的。GUEB是唯一一个用于UAF的二进制级静态分析器。该技术可与动态符号执行相结合以生成PoC输入,但存在可拓展性问题。另一方面,存在多个基于抽象解释、指针分析、模式匹配、模型检测或需求驱动指针分析的UAF源级静态检测器。所有静态检测器的共同弱点是它们无法推断触发输入——它们(静态检测器)只能证明它们(触发输入)不存在。
动态UAF检测器主要依赖于重量级的检测工具,并且会导致很高的运行时开销,对于闭源程序更是如此。ASan执行轻量级检测工具,但仅在源代码级别。
表4:现有基准概述

UAF模糊测试基准。虽然Juliet Test Suite(CWE-415,CWE-416)只包含极小的程序,但是现有的广泛使用的模糊测试基准也只包含很少的UAF bugs。此外,这些基准中有许多都包含了人为的bugs或人工程序。
我们构建了一个专门针对UAF bug的新基准,它包含12个真实代码和14个真实bug,以及用于模糊测试评估(参见表4)的详细信息。
第八章结论
UAFUZZ是第一个定向灰盒模糊测试方法,专门用于检测仅给定bug堆栈跟踪的UAF漏洞(二进制)。通过将标准的定向greybox模糊测试组件专门化于UAF方面,UAFUZZ在bug检测的时间和成功运行的次数方面都优于现有的定向fuzzer。我们的技术也只占用很少的开销,并且显著加快了bug分类步骤。UAFUZZ在bug复现和补丁测试中都被证明是有效的,它在GNU补丁、GPAC和Perl 5中发现了20个新的bugs-所有这些被发现的bugs都得到了开发者的认可,而且其中14个bugs已被修复。
表5:我们的UAF模糊基准概述——我们的研究中没有使用recall Jasper
表6:违反我们fuzzing基准的其他fuzzers在和UAFUZZ相对比情况下的bug复现概要。
有统计学意义的结果Aˆ12≥0.71标记为粗体。
表7:AFLGO的编译问题导致AFLGO的bug复现违反我们的基准(CVE-2017-10686除外)。红色的数字是最好的µTTEs
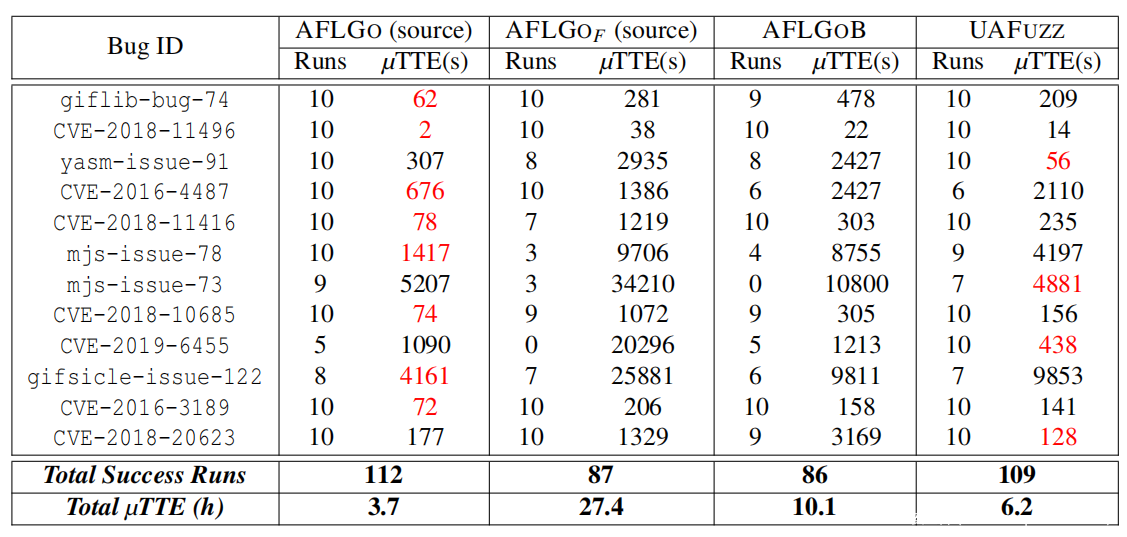
表8:4个违反我们基准的fuzzers的bug复现。有统计学意义的结果Aˆ12≥0.71标记为粗体。
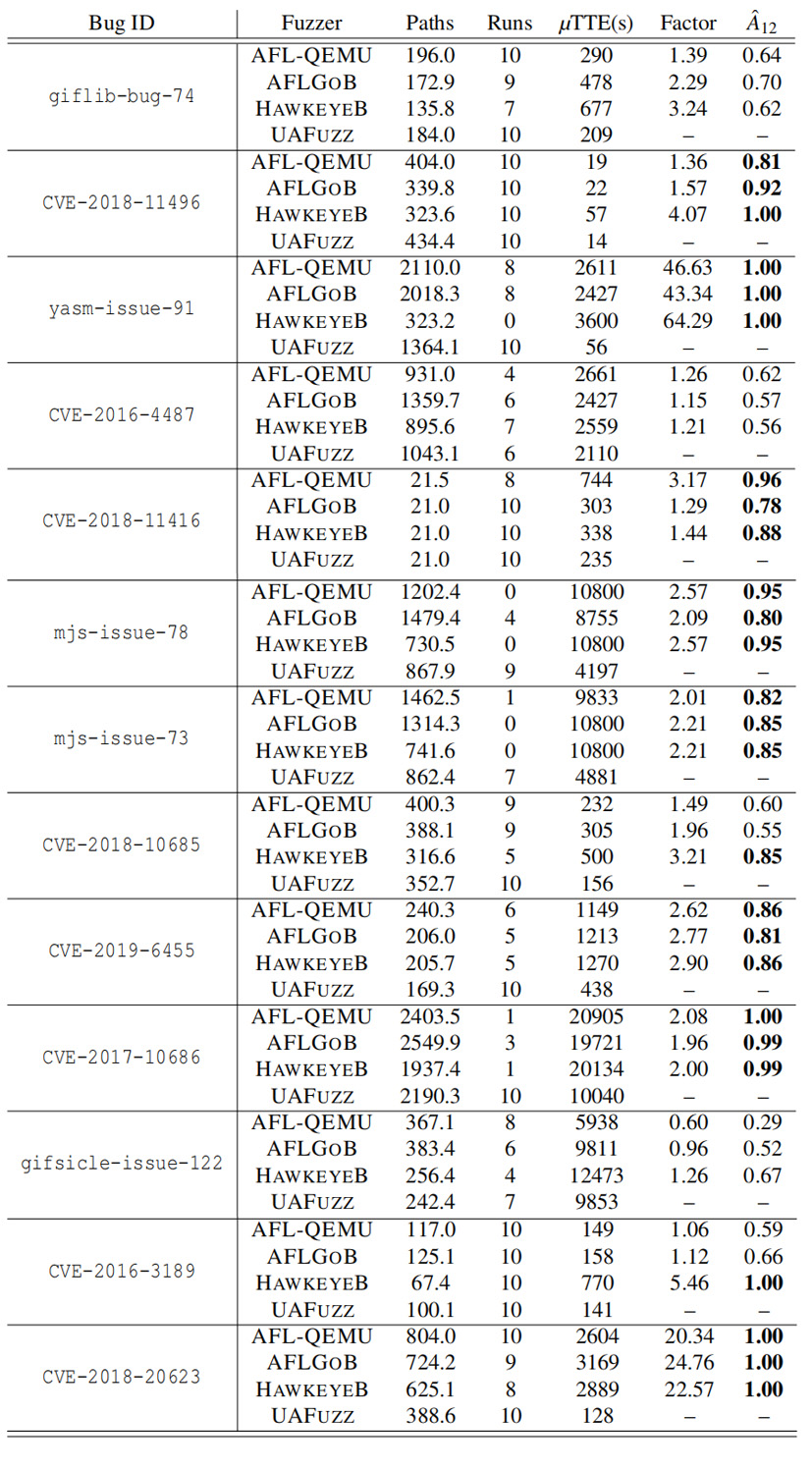
表9:与我们的受试对象相反的4个模糊测试器的平均分类输入数目。而对于UAFUZZ,TIR值在括号中。
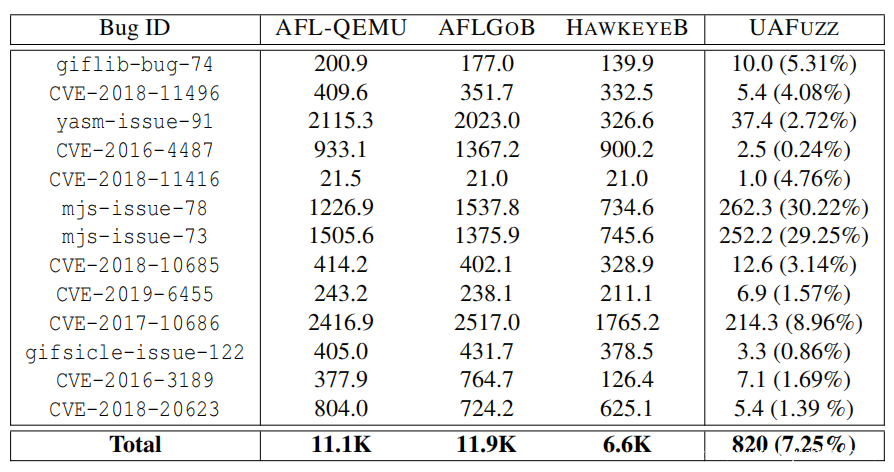
表10:违反我们基准的4个模糊测试器上的Bug复现。Aˆ12A和Aˆ12U表示AFLGOB和UAFUZZ的Vargha Delaney值。Aˆ12的具有统计意义的结果(例如Aˆ12A≤0.29或Aˆ12U≥0.71)用粗体显示。红色的数字是最好的µTTEs。
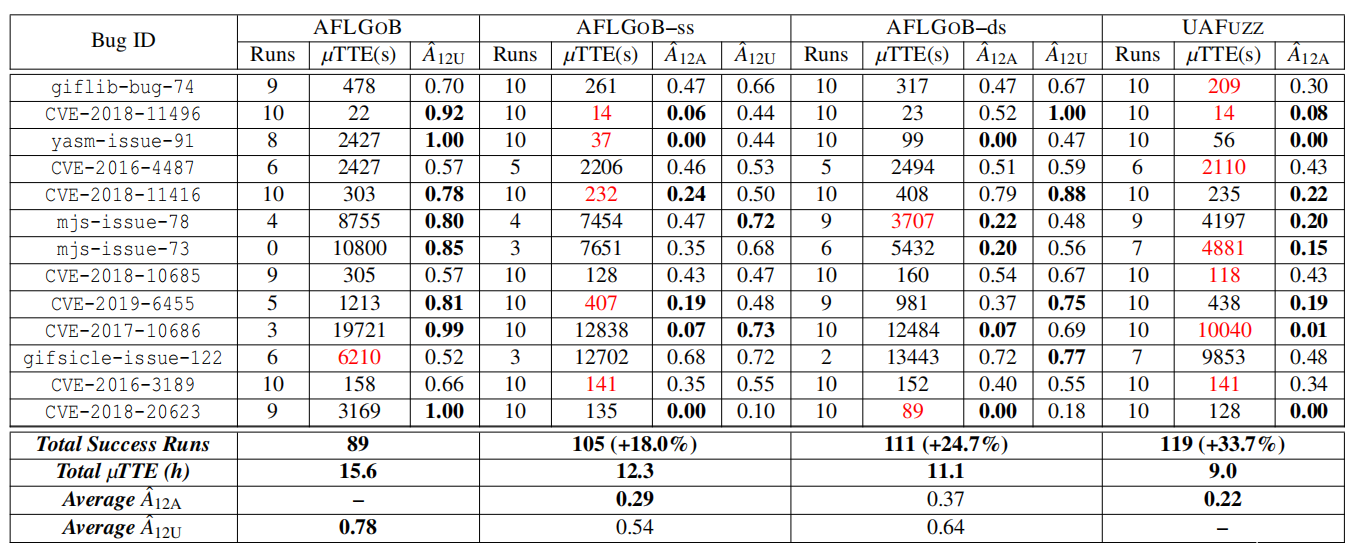
表11:我们的fuzzer报告的零日漏洞摘要。
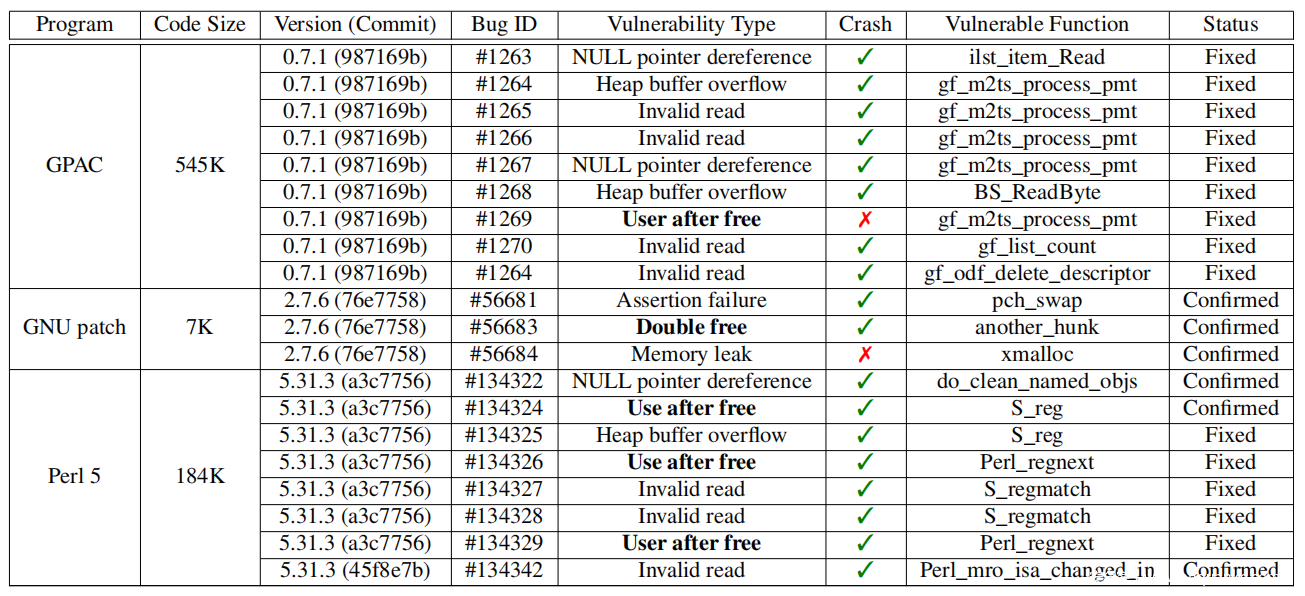
图12:yasm-issue-91的UAFUZZ模糊测试队列。
选定的要变异的输入以棕色强调。潜在的输入在水平虚线内。
图13:平均检测时间,以秒计算(由于AFLGO的编译问题,CVE-2017-10686除外)。
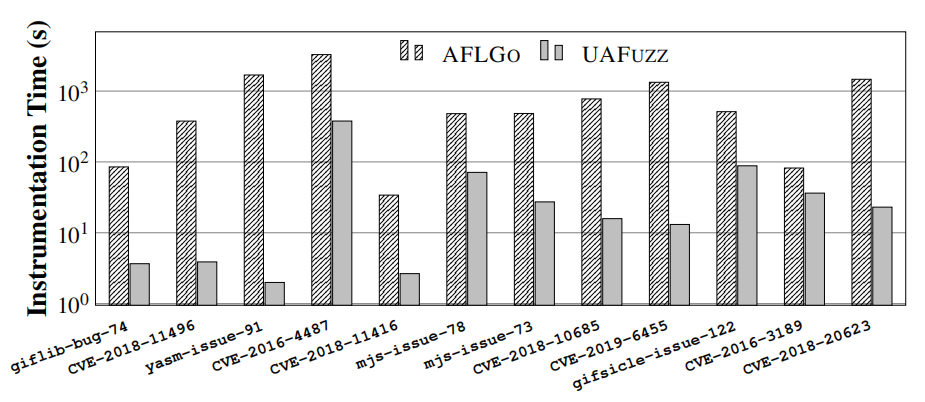
图14:平均检测时间,以秒计算。
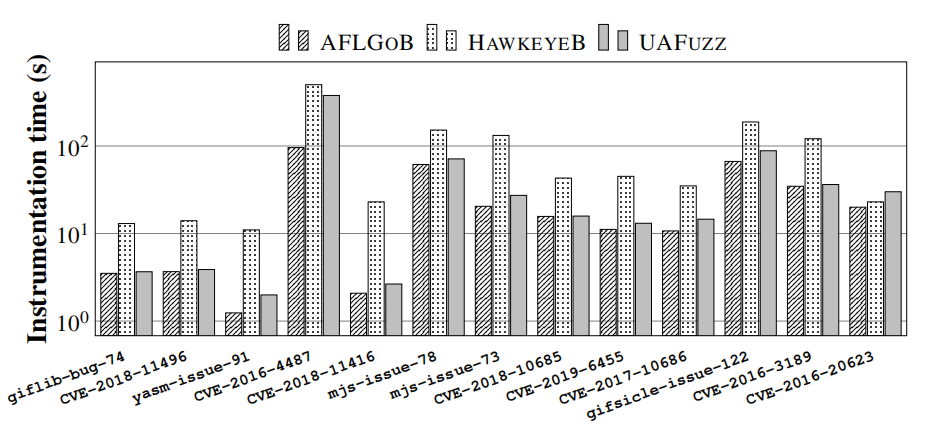
图15:所有运行中完成执行的总数。
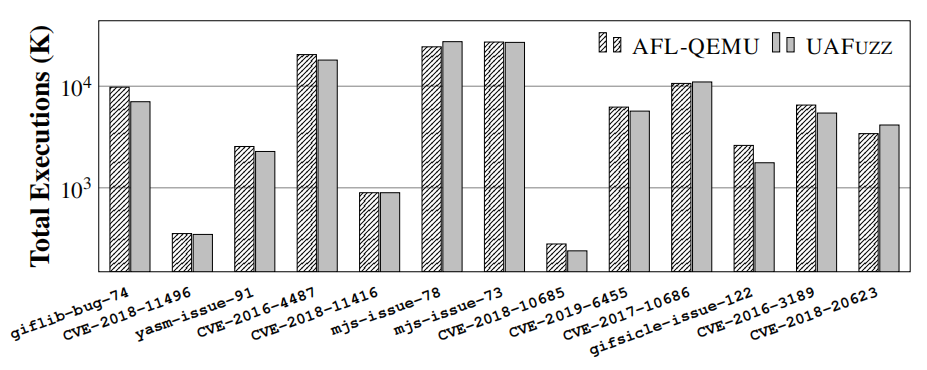
图16:平均分类时间,以秒计算。
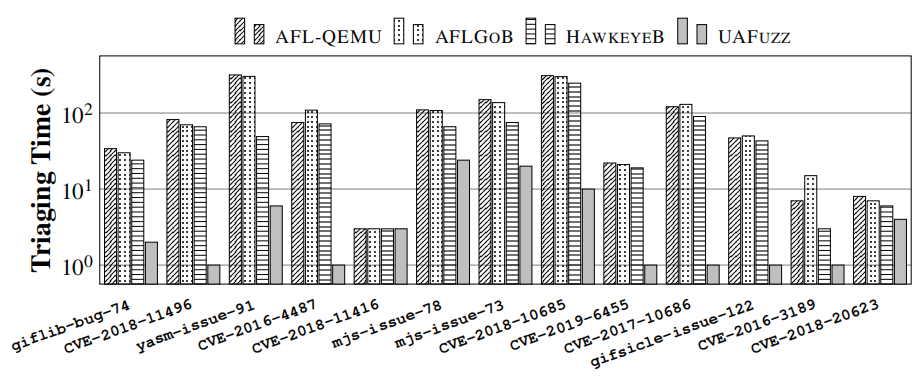
图17:VALGRIND产生的CVE-2018-6952的bug跟踪。

图18:除了标有“(m)”的对象(单位为分钟)外,4个模糊测试器的TTE,以秒为单位(TTE越低越好)。
清单3:GNU补丁中与UAF漏洞CVE-2018-6952相关的代码片段。








发表评论
您还未登录,请先登录。
登录