

论文主要内容包括:1.介绍和评估了NAUTILUS;2.阐述了几个基于文法的变异,输入精简和生成策略;3.报告了几个广泛使用软件里的bug
Nautilus介绍
在学习fuzzing binary的时候,当我们遇到需要构造结构化的输入的是通过libprotobuf-mutator+protobuf来实现自定义输入数据的结构以及修改相应变异策略。但当我们所要fuzz的程序对我们的输入不仅有结构上的限制而且要求符合相应的语法和语义规则时,显然之前的方法只能保证变异出的输入符合相应的结构却很难确保语法和语义的正确性,这时就要使用基于文法的fuzz来解决。
在论文发表之前,存在的grammar-based fuzz都是没有使用代码覆盖率的作为引导的,而这篇论文的核心Nautilus则是第一款将代码覆盖引导和基于文法规则结合起来的能够有效的fuzz复杂输入结构的模糊器fuzzer。
CFG
Nautilus能产生符合语法的高度结构化输入主要因为他使用了上下文无关文法(CFG)。
CFG是编译原理里面一个重要概念,几乎所有程序设计语言都是通过CFG来定义的。论文提供了一个CFG的参考:
N: {PROG, STMNT, EXPR, VAR, NUMBER}
T : { a , 1 , 2 , = , r e t u r n 1}
R: {
PROG → STMT (1)
PROG → STMT ; PROG (2)
STMT → return 1 (3)
STMT → VAR = EXPR (4)
VAR → a (5)
EXPR → NUMBER (6)
EXPR → EXPR + EXPR (7)
NUMBER → 1 (8)
NUMBER → 2 (9)
一个可能的推导PROG→ STMT→ VAR = EXPR→ a = EXPR→ a = NUMBER→ a = 1.最终生成的字符串是a=1。该推导过程也可以使用生成语法树来表示,NAUTILUS主要操作生成语法树,并且将它作为进行结构化变异的内部表示。同时为了处理一些语言不是CFG的,NAUTILUS也允许使用额外的脚本来转换输入以扩展CFGs
Nautilus设计架构
为了明确设计的目标,作者提出了Nautilus所要解决的一些挑战:
1.生成语法和语义上有效的输入
2.不依赖语料库(作者认为对于程序新添加的或者隐蔽的部分常用的seed是难以执行到的)
3.对target有高覆盖率
4.好的表现力
将这些挑战考虑在内,Nautilus的总体架构如下:
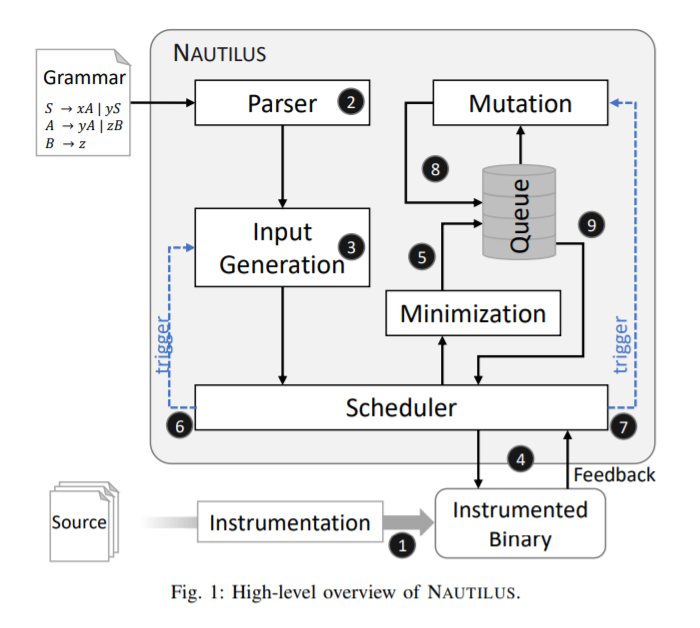
step1. 使用插桩编译目标源文件以得到执行时的代码覆盖反馈。
step2. fuzzer进程启动,解析用户提供的文法,之后从 scratch(?)产生1000个初始随机输入。
step3. 将输入传递给调度器。
step4. 之后NAUTILUS通过执行插桩编译后的文件测试新生成的输入是否触发任何新的覆盖。
step5. 如果种子触发了新的覆盖,NAUTILUS使用语法将其最小化并加入队列中。
step6&7. 同时如果新触发的代码块仍可以继续探索,调度器会对现存种子进行变异或生成一些新的种子。
step8. 对存放在队列里的种子,进行基于语法的变异并添加回队列。
step9. 队列里的种子用于随后的测试分析。
生成、精简、变异细节
基于CFG的种子生成
作者提到如果对于一个非终结符对应很多的规则选择,生成算法将选择不同的语法规则以使覆盖范围最大化。并提供了两种生成算法:naive generation and uniform generation
朴素生成
对一个有多种语法规则的非终结符,朴素生成会随机选择合适的语法规则。
例如上面的文法中,STMT对应两个语法规则(3)和(4),这是就产生了一个问题:如果选择了(4)非终结符会继续按照朴素生成的算法继续进行,以生成不同的结果;而如果选择了(3),retrun 1是终结符,派生就会停止。由于随机选择,因此(3)(4)概率均为50%,这样就对导致生成一半的重复结果。对此,作者在这种生成方式中增加了过滤器去检测近期是否有重复的输入生成。
均匀生成
相对与朴素生成算法遍历所有的可能,均匀算法将选择被建议的规则,避免掉入像STMT → return 1这种“偏斜”的分支中。
均匀算法基于该语法规则所能生成的子树数量进行选择。例如对于非终结符STMT,rule(3)能生成3种子树,rule(4)只能生成一颗子树,因此rule(3)被选择的次数将是rule(4)的三倍。
种子精简
在产生输入并执行之后, NAUTILUS将尝试对触发了覆盖率的种子进行精简,但前提是精简后的种子对代码的覆盖率应与精简前一致或更好。精简后的种子有利于减少执行测试的时间以及缩小之后潜在的变异集合。论文提供了两种精简策略:子树最小策略和递归最小策略。
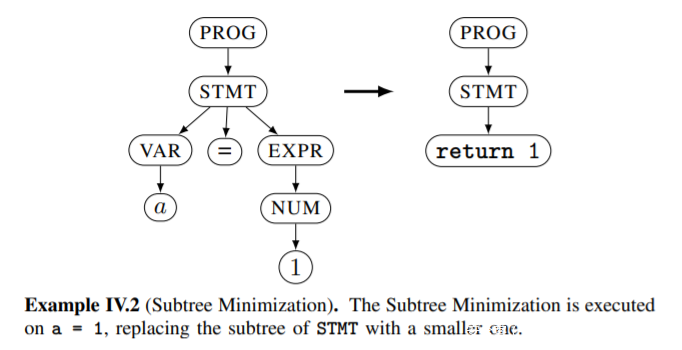
子树最小策略
正如其名称,该策略将经可能的在保证覆盖率的前提下选择最小的子树。对每一个非终结符,选择最小的子树并有序的替换每一个节点的子树为可能的最小子树并且检查变化后的规则所产生的种子是否仍能触发之前的代码块,如果可以,则替换之前的种子,否则将被丢弃。
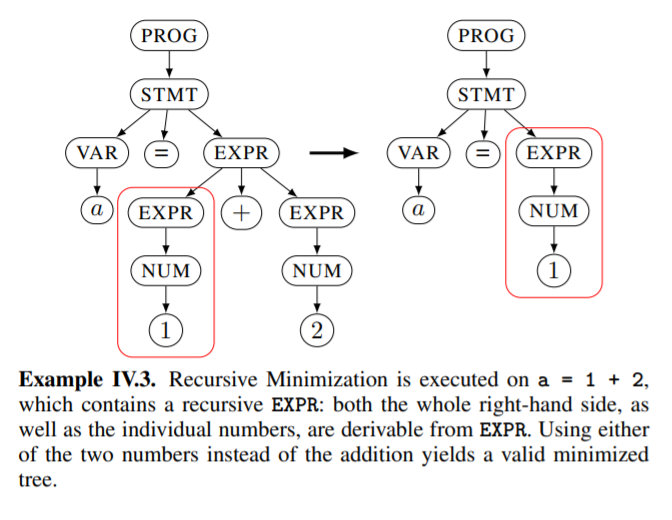
递归最小策略
该策略应用在子树最小策略之后,其目的通过识别存在的递归并替换为仅一次来减少有递归的节点的递归次数。
变异策略
在种子精简后,NAUTILUS使用多种方式去生成新的测试用例,除非特别规定,我们将统一采用下面所有的变异策略。
随机变异
随机选择一个树的节点并且用随机产生的以相同非终结符为根节点的子树替换,其大小是随机选择的并且最大的子树size作为一个配置参数。
规则变异
使用所有可能的规则所生成的子树去顺序替换每一个节点。
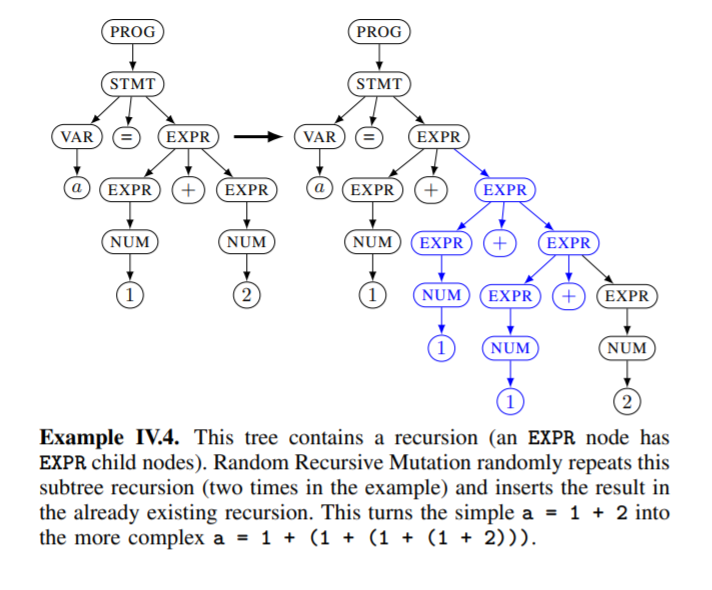
随机递归变异
随机选择生成树中的递归节点并重复2^n次(0<=n<=15)。这种变异所产生的树具有更高程度的嵌套。
拼接变异
将两个能发现不同路径的输入进行混合。具体做法为随机的选择一个内部节点作为将要被替换的子树的根节点,之后从队列里随机选择一个根节点是相同非终结符的子树去替换它。
AFL变异
在AFL中使用到的变异策略例如位反转,算术变异和魔术替换等。由于AFL变异是对字符串进行操作,因此子树在变异时要先转换成文本形式。这种变异有可能产生一些无效的树,有时可以用来发现语法分析器的bug。在AFL变异完后作为一种新的语法规则去替换原来的子树,但这种规则不会添加到文法当中,仅仅在生成树中保存。

测试用例生成
可以发现,正如作者所说的那样,NAUTILUS主要操作生成语法树来完成生成,精简和变异的策略。而当NAUTILUS得到了一个候选的生成树后,它需要利用该生成树来生成实际用于程序输入的二进制文件,这个过程称为”unparsing。
对于CFG来说,通过递归地定义一个unparsing function来将所有的未解析的子树连接起来。
但很多情况下输入语法并不是上下文无关的。因此,我们通过一个额外的unparsing脚本扩展规则定义,该脚本可以对所有未解析子树的结果执行任意计算,脚本支持也是该生成方法的一大优势。
例如XML中的一条产生式规则为TAG →<ID>BODY </ID>,在CFG中两个ID是相互独立的,因此可能会生成<a>foo</b>。如果通过unparsing脚本来扩展规则的定义为TAG →ID,BODY并且相应unparsing function定义为lambda |id,body| "<"+id+">"+body+"</"+id+">".从而能够生成一个有效的TAG
具体实现
NAUTILUS是利用Rust开发的,其整体架构类似于AFL。我们使用mruby解释器来执行用于扩展语法规则的unparsing脚本。与AFL类似,NAUTILUS需要对目标程序进行插桩,并分为以下几个阶段对目标进行模糊处理。
Phase1.目标插桩
NAUTILUS享用了AFL在源码插桩时中使用到的bitmap的概念。
自定义的编译器传递添加了基于目标程序中基本代码块的执行信息来更新bitmap的桩代码。此外,编译器还传递添加了一些在forkserver中运行应用程序的代码,以此来提高执行输入的速度。
Phase2.ANTLR语法分析器
NAUTILUS接受的语法输入可以是JSON形式,也可以是ANTLR编写的语法,为了支持ANTLR语法,集成了一个ANTLR Parser组件。ANTLR将输入的语法转化为语法生成树,并进行可视化显示,在ANTLR里面已经有200多种编程语言的语法公开可用。
Phase3.准备阶段
NAUTILUS根据提供的文法预先计算出一些数据,包括上面提到的在规则变异时会使用到的min(n)(对于每个非终结符n,用于计算以n作为起始非终结符的字符串所需应用的最小规则数),以及均匀生成时所需要的子树数量相关的信息p(n, l, r)和p(n, l)等。
Phase4.Fuzzing阶段
Fuzzing的工作流程如下图:
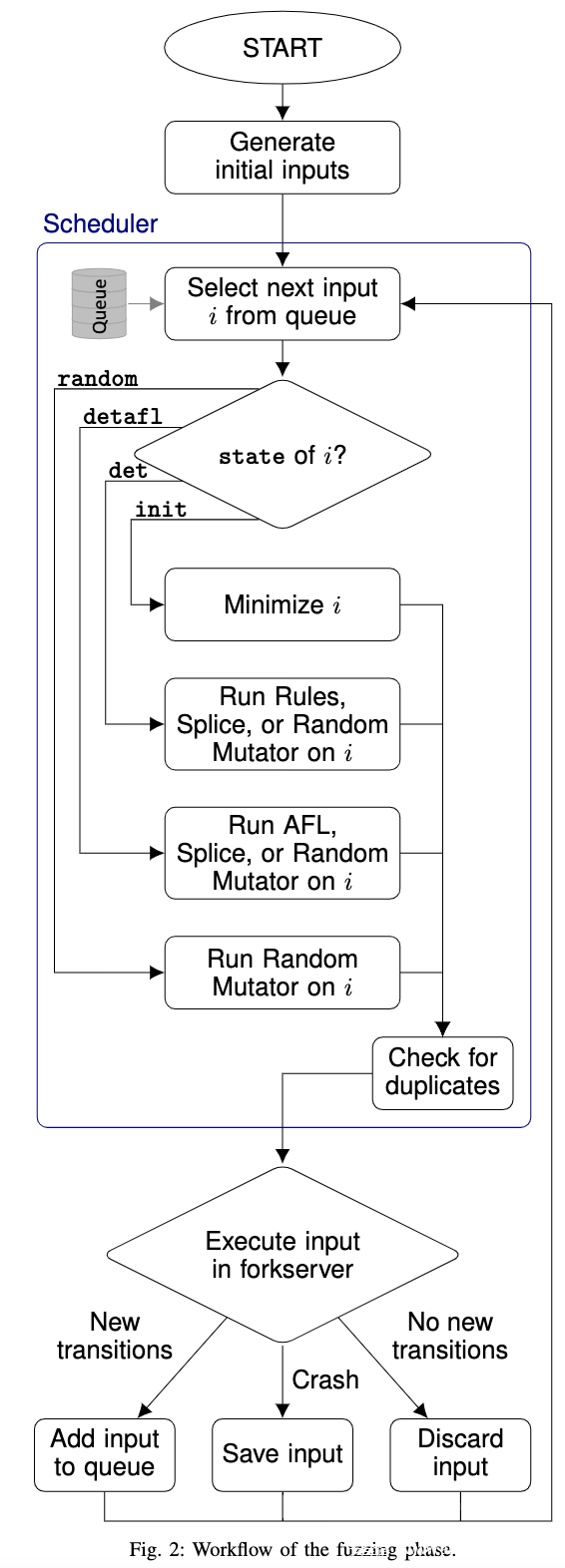
在生成一些初始输入之后,调度器决定接下来应该尝试哪个输入:(i)用某个特定的变异对现有输入进行变异,或者(ii)从头生成一个新的输入。调度程序按顺序处理队列中的每一项。
队列中的每个项都有一个状态,该状态指示从队列中取出它时将如何处理它。状态可以是以下情况:
init:如果一个输入触发了一个新的转换,那么它将保存在具有init状态的队列中。当调度器选择处于init状态的项时,将最小化该项,完成之后状态被设置为det。
det:det中的种子使用规则变异、随机(递归)变异和拼接变异进行变异。当完成规则变异后进入detfal状态。
detafl:对detafl中的种子进行AFL变异、随机递归变异和交叉变异,当AFL变异完成后进入random状态。
random:进行随机变异、随机递归变异和交叉变异,这里跟AFL不同的是在选择下一个种子前不需要完成这里每个阶段。在继续处理下一个输入之前,NAUTILUS只在每个输入上花费很短的时间。因此,可以快速地探索那些可能产生新覆盖率的输入,这可以实现类似AFLFast的效果。
在选择一个要执行的生成树之后,它将被解析为一个输入字符串。然后,用这个输入运行目标程序,使用一个类似于AFL使用的forkserver,它可以以一种高效的方式启动目标应用程序。有三种可能的状态:
1.目标程序在执行期间崩溃,之后产生此次崩溃的输入将被报存在一个单独的文件夹。
2.触发了新的路径,之后产生该输入的生成树将被添加到队列中。
3.没有触发任何新的路径,输入被丢弃。
本文主要记录了论文前两个部分的内容,第三部分对于NAUTILUS的评估作者提供了很多实验的数据和图片,大家可以直接去看原文。
如有错误之处还烦请各位指正。
参考:
https://www.syssec.ruhr-uni-bochum.de/media/emma/veroeffentlichungen/2018/12/17/NDSS19-Nautilus.pdf







发表评论
您还未登录,请先登录。
登录