

0x01
本文全文以对抗样本攻击为导向,通过实战的方式,首先介绍并实现对抗样本攻击,然后分析对抗样本的性质、人类与AI决策时的差异,只有介绍防御对抗样本方案之一—对抗训练得到鲁棒模型,并通过基于梯度、基于特征可视化两种解释性技术来尝试解释模型决策行为。
0x02对抗样本攻击
我们这里使用ILSVRC竞赛中ImageNet数据集的一个子集。
首先要创建一个loader用于访问数据集,一个标准化函数用于对输入图片以及之后生成的对抗样本规范化处理,还需要一个label map,来指出数值和图片之间的对应关系。

数据集加载后可以打印出部分样本及其标签

数据准备好了,接下来我们加载模型,这里我们直接使用pytorch提供的预训练好的resnet18

首先我们来进行对抗样本攻击,对抗样本就是在原样本上添加人眼不可察觉的非随机扰动 后,导致模型对扰动后的样本做出误分类的结果。
生成对抗样本的想法是非常简单的,给定一个目标类t,我们希望找到一个扰动![]() ,当我们扰动加入原样本x后,会最大化目标类的似然;与此同时,我们希望扰动足够小,或者位于我们预定义的绕动集内,比如一个小的l2-ball内。我们可以用下面的式子来形式化定义
,当我们扰动加入原样本x后,会最大化目标类的似然;与此同时,我们希望扰动足够小,或者位于我们预定义的绕动集内,比如一个小的l2-ball内。我们可以用下面的式子来形式化定义
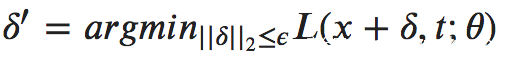
我们的任务就是在能够最大似然的同时,最小化上式(也就是找到最小的符合要求的扰动),我们可以使用PGD来实现
PGD是在《Towards deep learning models resistant to adversarial attacks》中被提出来的,该论文从鲁棒性优化的角度研究了神经网络的对抗鲁棒性,使用了一种natural saddle point (min-max) 公式来定义对对抗攻击的安全性。这个公式将攻击和防御放到了同一个理论框架中,使得我们可以对攻击和防御的性能有良好的量化。
论文的核心就是下面的鞍点问题
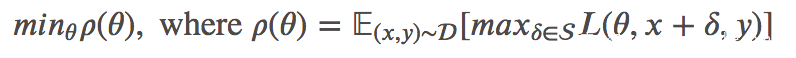
上面的公式包含一个最大化和一个最小化过程。最大化的意思是找到一个给定数据点 的能使损失函数最大化的对抗版本,这正是攻击问题。最小化的目标是优化模型参数,使得内部的对抗损失最小化,而这是一个防御问题。
作者对此鞍点公式相对应的优化场景进行了仔细的实验研究,提出了PGD这个一阶方法(利用局部一阶信息)来解决这个问题。PGD首先在原图附近允许的范围内(球形噪声区域)进行随机初始化搜索,然后进行多次迭代产生对抗样本。PGD是一种典型的一阶攻击,如果防御方法对PGD攻击有效,则该防御方法对其他的一阶攻击也有着很好的防御效果,公式如下
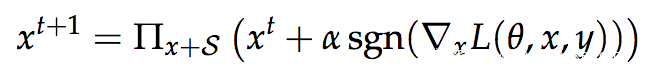
回到代码上来,我们先来指定目标类,如果攻击成功,那么对抗样本就会被模型误分类为目标类
这里我们可以设为1,通过label map的映射我们知道,目标类是金鱼

接下来我们实现L2PGD攻击,这里需要注意几个参数:
eps:对于l2范数而言,这是扰动的最大程度,比如eps=2则意味着||![]() |
|![]() <2
<2
Nsteps:投影梯度下降执行的次数
Step_size:投影梯度下降每一步的大小

创建对抗样本

为了验证攻击是否成功,我们需要让模型来判别这些对抗样本

从结果可以看出,模型把生成的对抗样本都判别为了1,即我们之前指定的目标类
为了更直观比较,我们可以将原样本、对抗样本以及模型对样本的预测结果都打印出来

图中,上面一排是原样本,下面一排是对应的对抗样本,对抗样本的上面是模型给出的预测,可以看到全部都被预测为了金鱼,同时对抗样本与原样本人眼基本不可区分,说明我们的攻击成功了。
0x03分析对抗样本
对抗样本所加上的扰动是否有意义呢?我们接下来研究一下。
为了提高效率,我们这里使用在CIFAR10数据集的子集上训练的线性分类器。
和前一部分一样,我们还是先加载数据

加载成功后,打印出部分样本看看
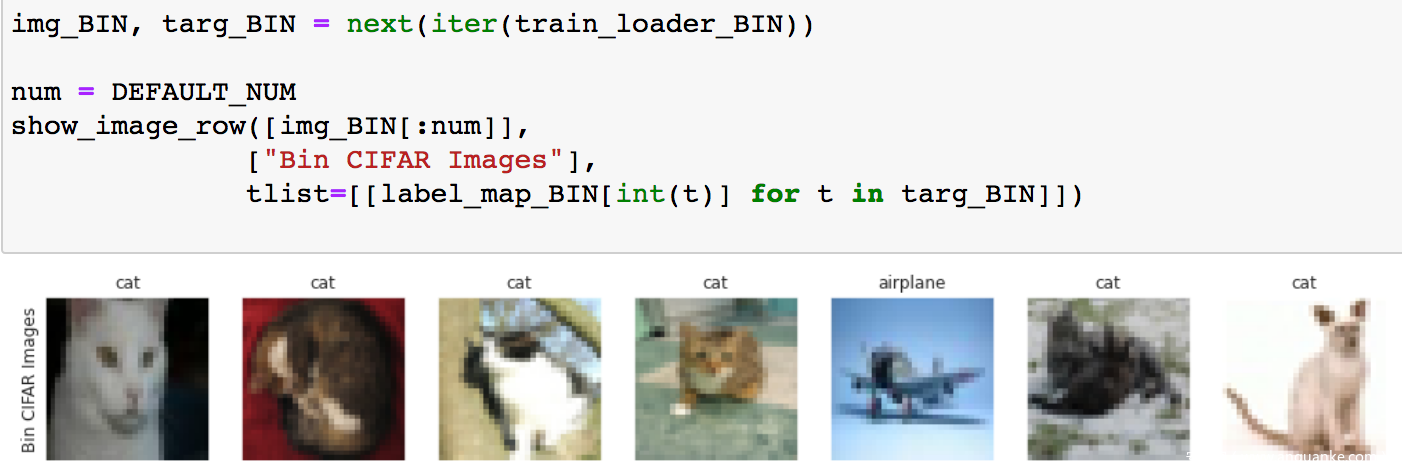
从上图可以看到,这个子集上共有两类:猫和飞机
接下来我们训练一个线性分类器。首先我们写一些必须的辅助函数

训练函数

然后开始训练
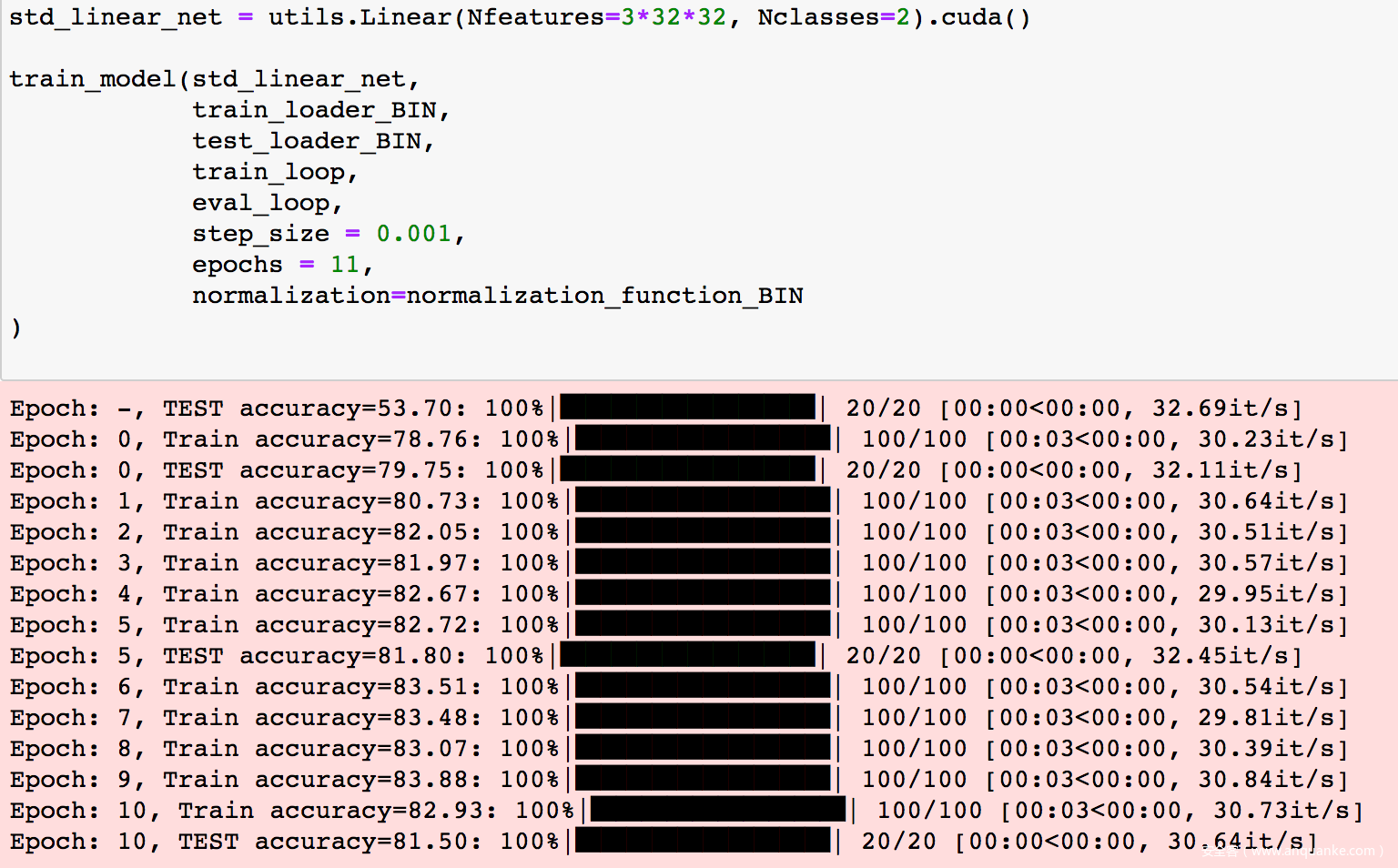
训练完成后,我们可以测试一部分样本,打印出图片及模型给出的预测
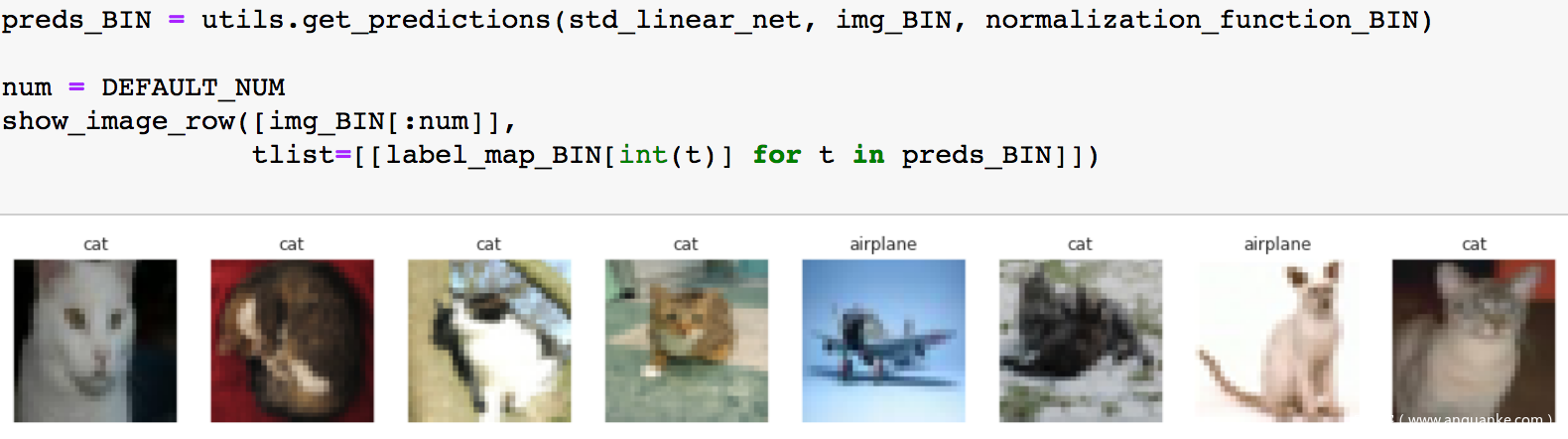
可以看到模型会做出正常的分类结果。
接下来我们稍微改动代码,做一个有意思的尝试,在对抗样本上训练模型看看会发生什么。
首先我们向所有训练集的图片添加对抗性扰动,使得模型会将其误分类(会将看起来是猫的图片分类为飞机,将看起来是飞机的图片分类为猫)
然后将所有可以成功欺骗模型的图片(即原图被模型判别为猫,对抗样本被判别为飞机;反之亦然)放在一起作为新的训练集(注意,此时的标签是模型预测的标签,换句话说,现在我们给看起来是猫的图片打上的标签是飞机,反之亦然),在其上进行训练
首先生成对抗样本
然后看看有多少样本可以欺骗模型
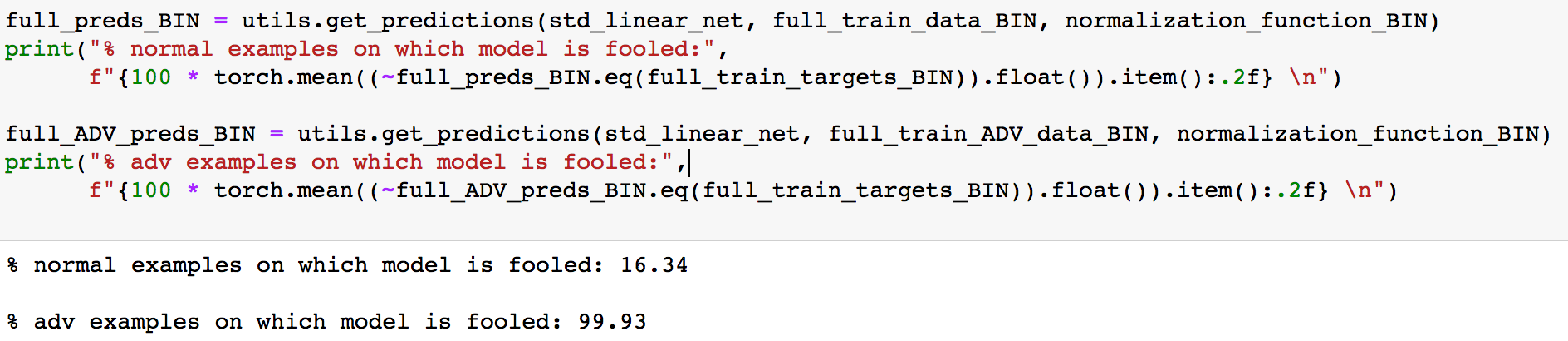
可以看到几乎全部的样本都可以成功欺骗模型,那么我们就不过滤了,直接将其作为新的训练集

注意看上图,上面一行是原图,下面一行是对抗样本,其标签是与原图完全相反的,比如第一张对抗样本看上去是猫,但是其被模型判断为飞机,其标签也就是飞机。
我们再来看看训练集和测试集的对比
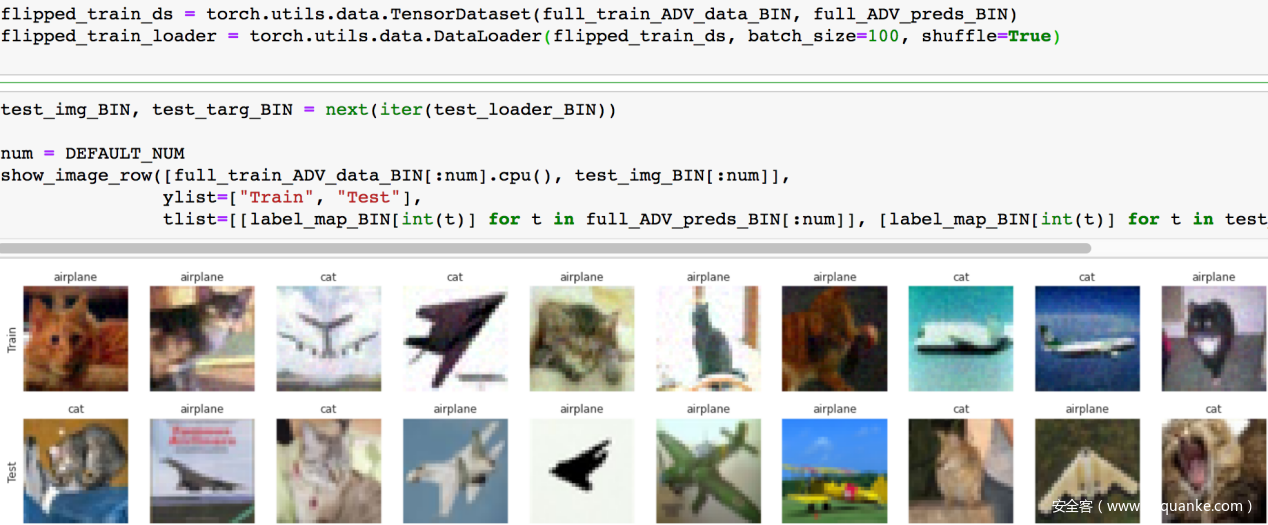
上面一行是训练集,下面一行是测试集,注意测试集中看起来是猫的图片其标签就是猫
那么我们考虑一个问题,作为人类,如果我们在上图的训练集上训练后,我们会学到[猫的对抗样本,飞机],[飞机的对抗样本,猫]这种标签对上怎样的映射关系?当在测试集上进行测试,我们会对测试集做出怎样的分类?
我们在对抗样本组成的训练集上训练一个新的模型
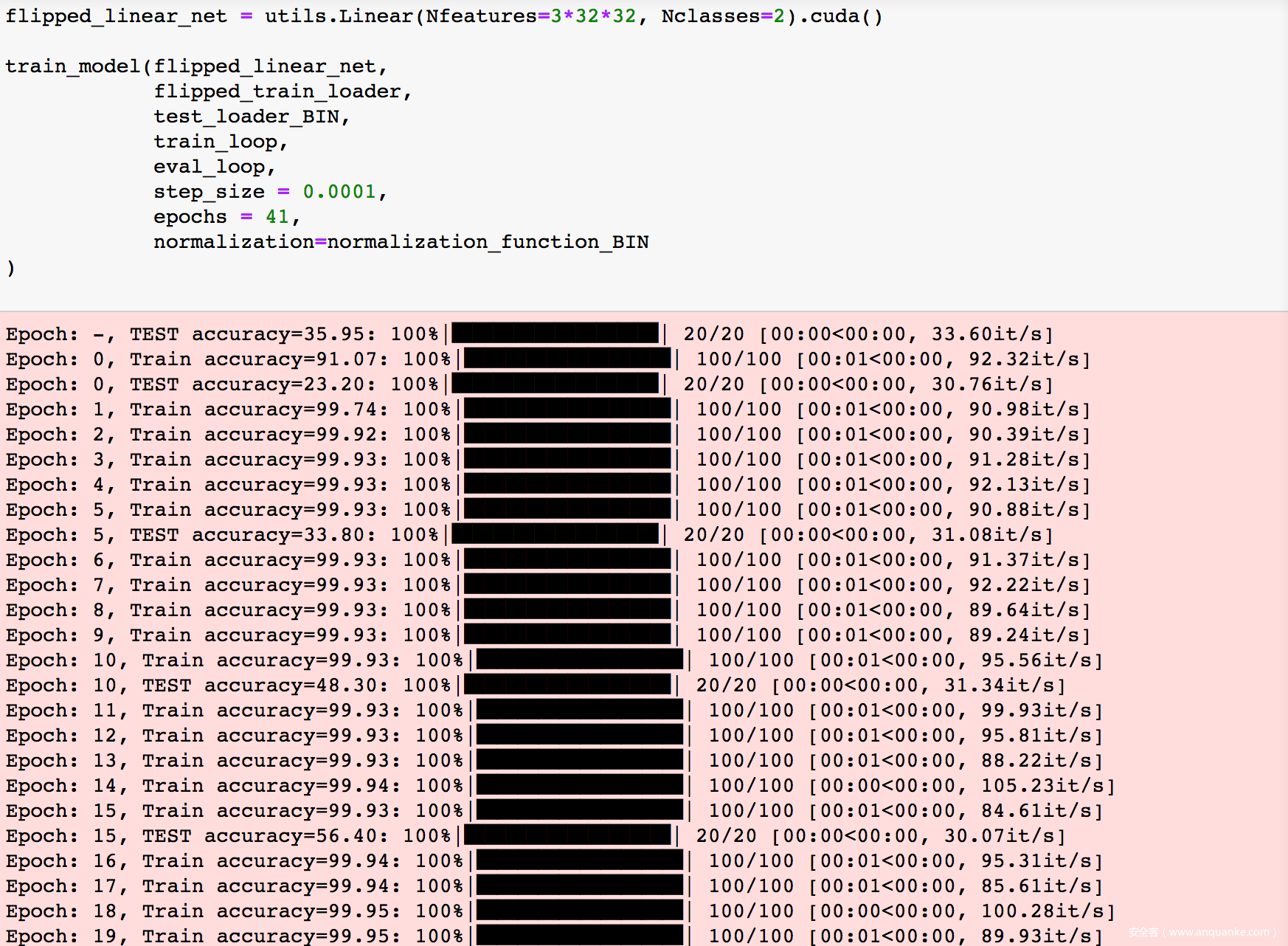
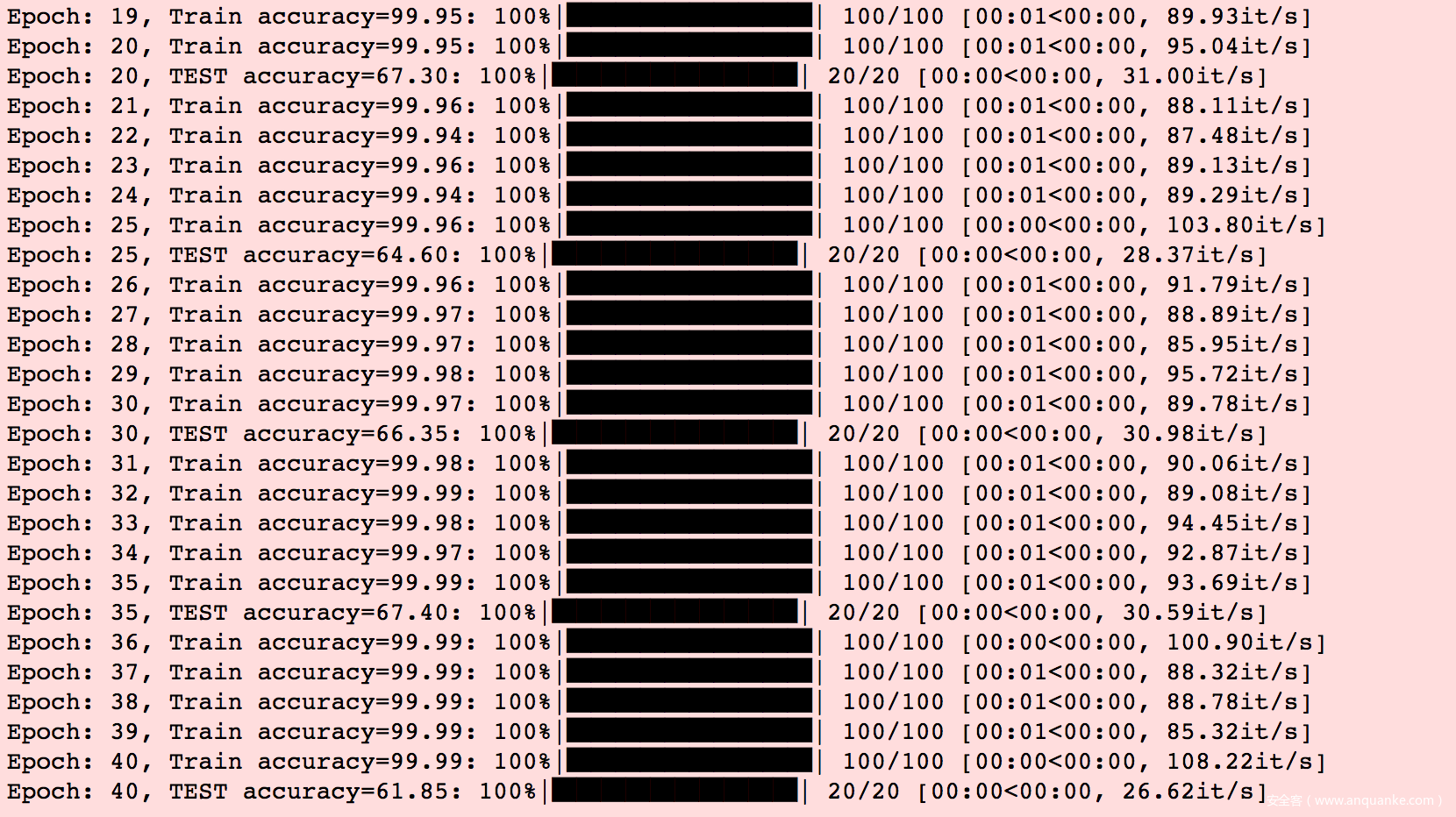
可以看到虽然模型是在对抗样本训练集上训练的,但是在测试集上的accuracy在60%左右
为了更直观一点,我们可以打印出图片及模型的预测
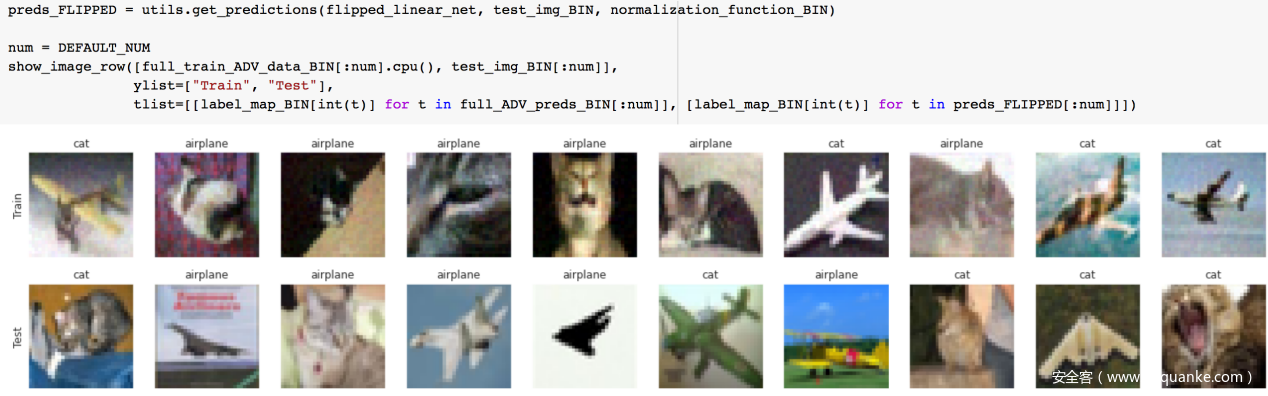
在上图中,看下面一排的前两张,第一张是猫,模型将其预测为猫,说明预测正确,第二张是飞机,模型将其预测为飞机,说明预测正确,其他图片以此类推。
如果是我们人来做的话会怎么样呢?
如果我们是在对抗样本训练集上训练的话,我们可能会学到的映射关系是:长得像猫的图片,给其标签打上飞机,长得像飞机的图片,给其标签打上猫;如果学到了这种映射,那么我们在面对测试集的前两张图片时,应该把第一张识别为飞机,第二张识别为猫才对。但是模型给出的预测结果与我们想象的不一样。
为什么会这样呢?
我们把图像中对人类有意义的特征称之为稳健特征,他们实际上都是指向错误标签的。因此如果人来做的话,在测试集上的准确率为0(正如我们前一段分析的一样),但是模型却可以达到60%的准确率,说明其在做决策时的依据和人类并不相同。这之间的区别一定是因为我们加入的对抗性扰动引起的,比如当我们向原标签为猫的图像中添加扰动使前一个模型认为它是飞机时,我们添加的必须是可以泛化到测试集上的飞机的特征。至于模型决策时的依据究竟是什么,尚无定论,感兴趣的师傅们可以参考XAI领域的最新进展。
0x04解释性方法
我们利用最经典的解释性方法:基于梯度的显著图。这些显著图会突出显示模型的预测对输入的哪些区域最为敏感。
我们计算loss相对于输入的梯度,对于输入的每个像素,梯度可以告诉我们,梯度可以告诉我们,如果稍微改变该像素,loss会如何变化
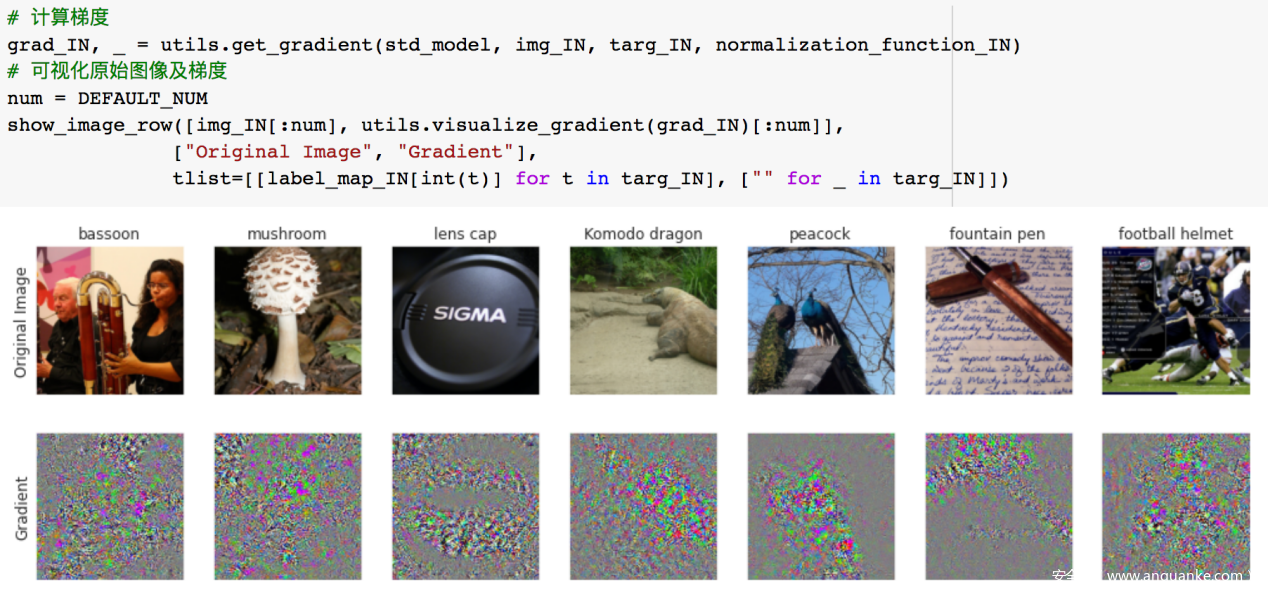
上图中打印出的梯度看上出有很多噪声,很难以此做出解释
为了有研究人员提出了SmoothGrad
代码实现如下
注意,在这里,我们是在在一堆附近的点上取梯度并平均它们的梯度,而不是取单个图像的梯度。
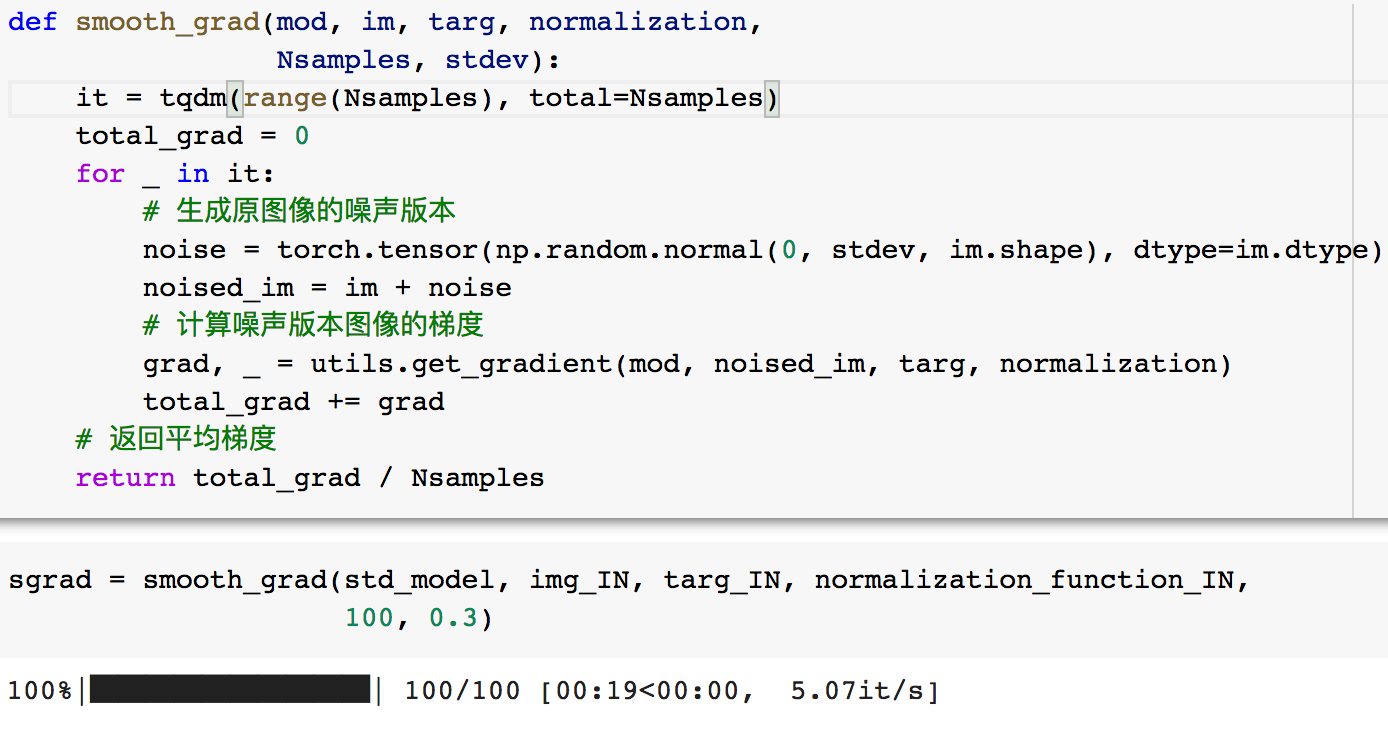
然后再次打印图片和梯度

可以看到SmoothGrad打印出的梯度相比于之前的梯度更加具有辨识度,也更符合我们雷人用于进行决策的特征。
由于对抗样本的存在,研究人员来开始尝试研究鲁棒模型,即能够在一定程度抵抗对抗样本攻击的模型。获得鲁棒模型的一种方法是使用对抗训练,这里我们不再是最小化原训练样本上的损失,而是最小化对抗样本上的损失。
我们这里不再自己训练了,直接加载一个预训练好的鲁棒模型Resnet50

加载数据集

我们使用我们之前的方法对鲁棒模型发动对抗样本攻击,看看是否可以攻击成功
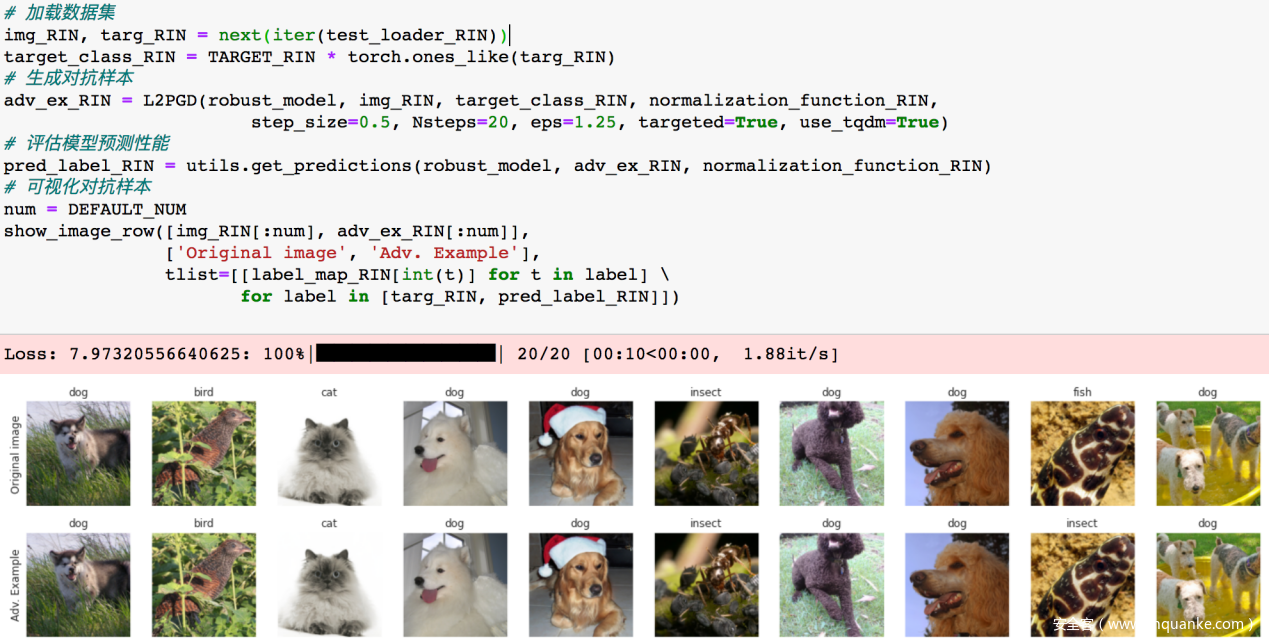
下面一排是对抗样本及模型给出的预测,可以看到模型并不会被对抗样本欺骗
那么怎样可以欺骗模型呢?最简单的思路就是增加扰动强度
我们把eps从1.25提升到100
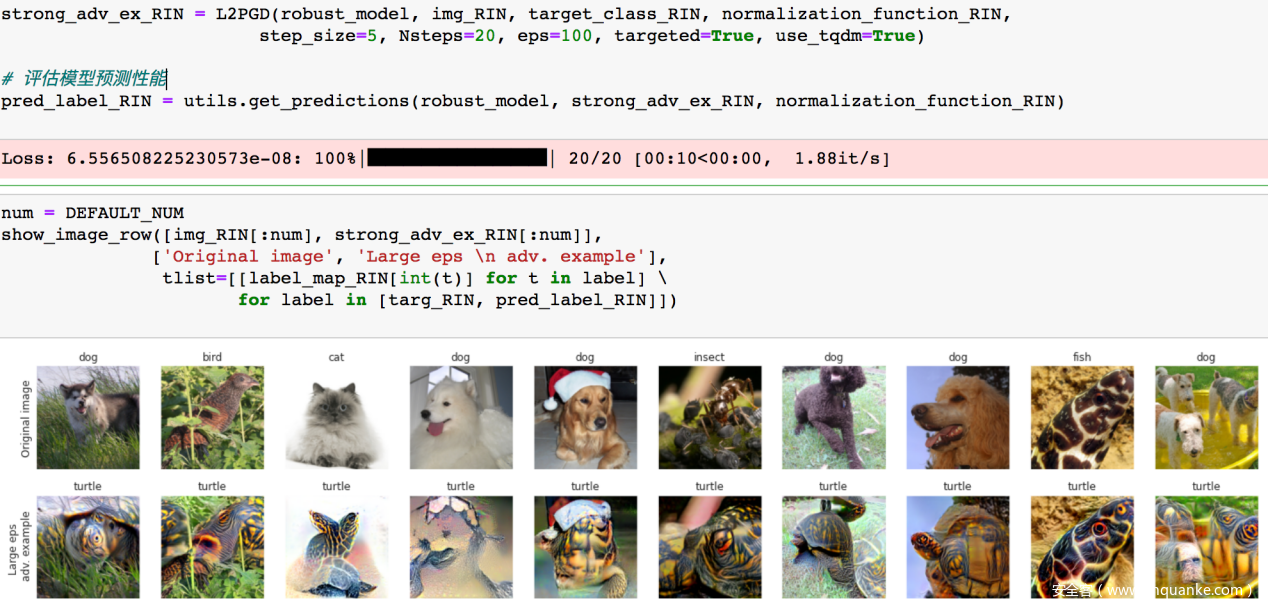
可以看到此时的对抗样本可以攻击成功,欺骗模型了,但是不足就是扰动太大了,以至于对抗样本与其对应的原样本视觉上区别很大
我们从上面的实验中知道了,对于鲁棒模型而言,当应用人眼不可察觉的扰动时 ,生成的对抗样本无效,当应用人眼可察觉的扰动时,对抗样本才会攻击成功。这是不是意味着鲁棒模型做决策所依赖的特征在一定意义上与人类相似?
我们还是打印出梯度看看

可以看到,鲁棒模型的一般梯度的辨别度甚至与普通模型的SmoothGrad效果还要好
这是用基于梯度的可解释性方法,我们再考虑另一种方法:特征可视化
此时我们的目标是找到一个最大化特征(深度网络中的特定神经元)的输入,而不是仅仅最大化损失(就像我们之前对梯度所做的那样)
首先获取特征向量

然后实现损失函数以进行特征可视化

应用其进行特征可视化
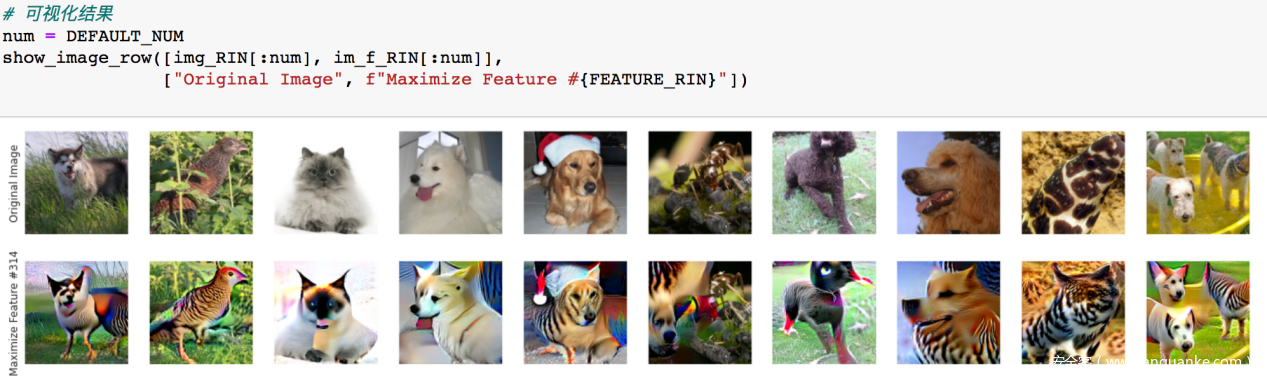
上下图对应比较得到的差别最大的地方就是我们要可视化的特征的最大化结果。
这是由于鲁棒模型做的,我们看看在一般模型上做特征可视化的情况
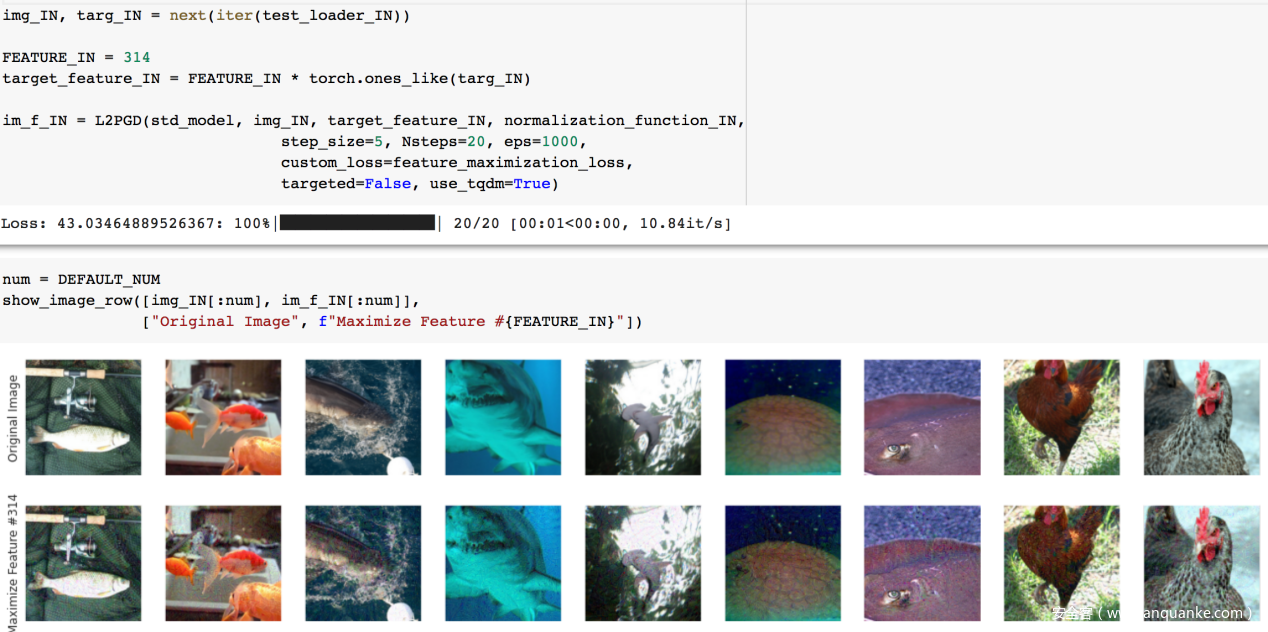
可以看到差别并不大,这说明鲁棒模型相对于一般模型而言其决策依据可能与人类决策依据更接近。
0x05对抗训练
之前我们提到了鲁棒模型的训练方法之一就是对抗训练,本质就是将对抗样本加入到训练集中,使得模型能够拟合对抗样本。我们也可以自己手动实现。

这里为了简单起见,我们训练一个鲁棒的线性模型
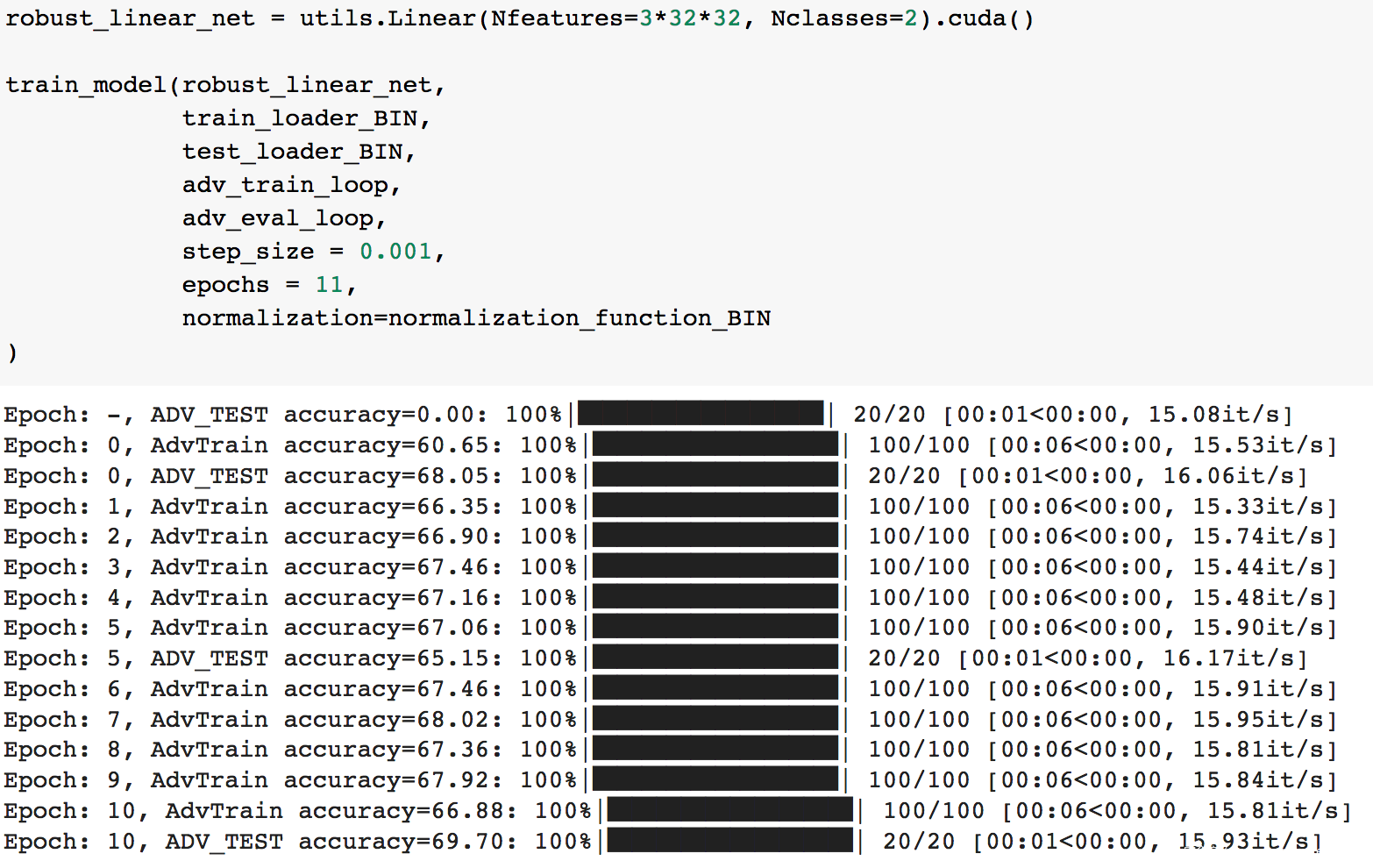
训练完毕后,我们看看它是否可以抵抗对抗样本攻击
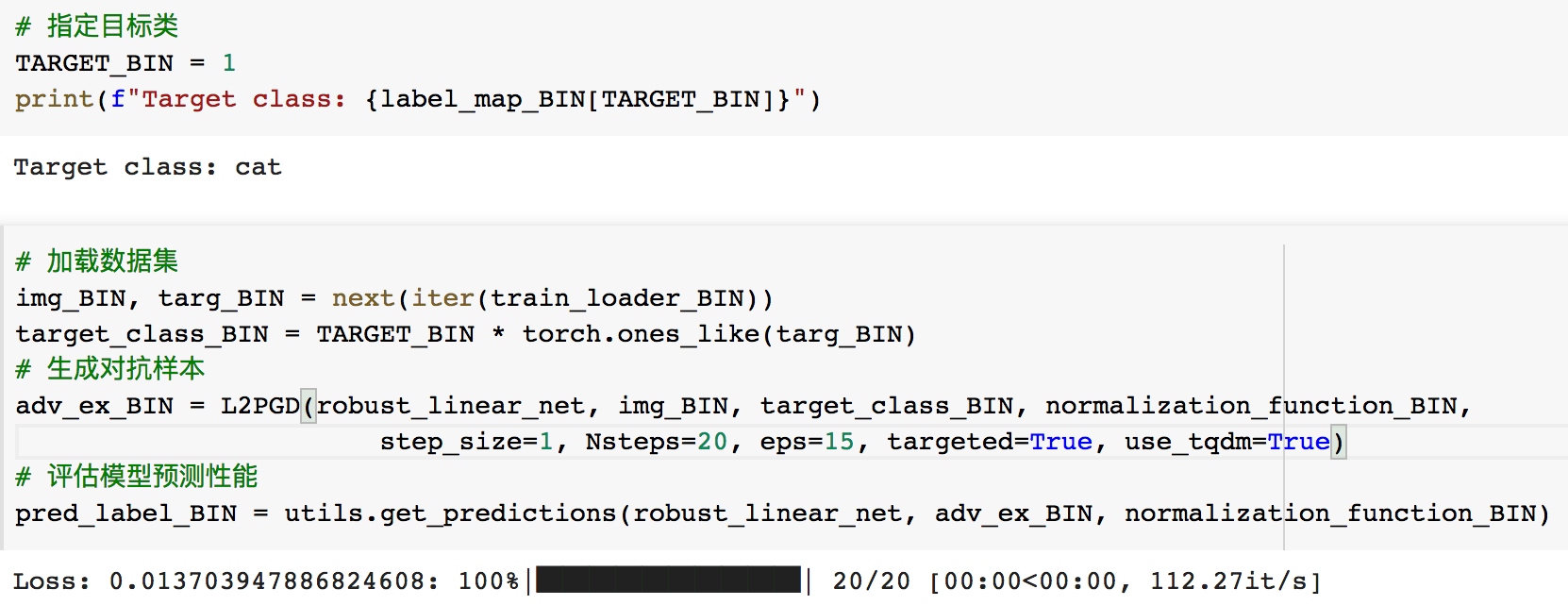
可视化对抗样本及模型给出的预测结果

可以看到,尽管对抗样本的扰动很大,但是模型还是不会被欺骗,说明其鲁棒性确实强。
0x06参考
1.Towards Deep Learning Models Resistant to AdversarialAttacks
2.A Survey on Explainable Artificial Intelligence(XAI): towards Medical XAI
3.Explainable Artificial Intelligence Approaches: A Survey
4.Recent Advances in Adversarial Training for Adversarial Robustness
5.Adversarial Training for Free!
6.What Do Adversarially Robust Models Look At?
7.The Curious Case of Adversarially Robust Models: More Data Can Help, Double Descend, or Hurt Generalization
8.Machine Learning: A Robustness Perspective(http://phdopen.mimuw.edu.pl/index.php?page=z20w1)
9.UIUC cs562(https://aisecure.github.io/TEACHING/CS562/CS562-Fall2021.html)







发表评论
您还未登录,请先登录。
登录