

前言
最近发现一个AFL的学习资料:https://github.com/mykter/afl-training。
本文主要记录了我学习Fuzzing Workshop的过程,以及中间遇到的问题和思考。
希望能够对大家学习fuzzing或者AFL有所帮助。
这个workshop由几个challenge组成,这些challenge的目的是用AFL在开源软件里复现漏洞。漏洞主要包括下面几个,每个漏洞都有自己的特色。比如libxml是无状态的库,ntpq是网络服务类程序,date是因为环境变量导致的溢出。
(1)libxml: CVE-2015-8317
(2)openssl的心脏滴血: CVE-2014-0160
(3)ntpq:CVE-2009-0159
(4)sendmail : CVE-1999-0206, CVE-2003-0161
(5)date:CVE-2017-7476
(6)CGC的CROMU_00007
创建环境
这里采用docker方式创建学习环境。
首先,进入到仓库下的environment,基于dockerfile构建镜像。
docker build . -t fuzz-training
运行容器,需要使用—privileged选项,才可以使用一些脚本limit_memory或者gdb这些工具。
sudo docker run --privileged -ti --name=afl-train -e PASSMETHOD=env -e PASS=password ghcr.io/mykter/fuzz-training /bin/bash
运行该命令配置系统环境,这样afl启动的时候就不会出现echo core的提示了。
cd AFLplusplus
./afl-system-config
现在在docker里测试一下小程序。
对小程序源码编译,编译的时候顺便插桩一下。
cd quickstart
CC=afl-clang-fast AFL_HARDEN=1 make
测试一下编译的程序是否能够运行:
./vulnerable
输入回车后应该会出现下面的结果
Usage: ./vulnerable
Text utility - accepts commands and data on stdin and prints results to stdout.
Input | Output
------------------+-----------------------
u <N> <string> | Uppercased version of the first <N> bytes of <string>.
head <N> <string> | The first <N> bytes of <string>.
用种子输入测试程序
./vulnerable < inputs/u
结果:
CAPSme
现在用fuzzer去测试
afl-fuzz -i inputs -o out ./vulnerable
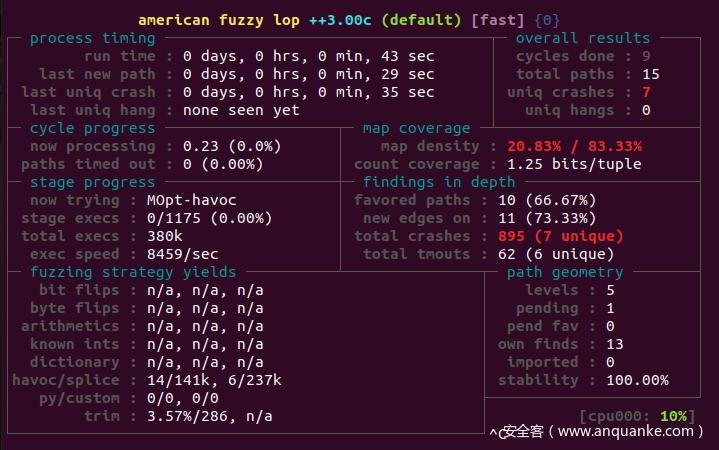
执行完上面的命令后,应该出现的是下面的结果。
Harness
这一章节主要是讲怎么写harness,来让afl测试代码片段。如果对afl如何将数据送到目标程序比较熟悉的话,可以跳过这一章节,直接看challenge。下面的图(来源该仓库的文档 https://github.com/mykter/afl-training/tree/main/harness) 描述了AFL的模块关系。
input存放给定的初始种子输入,然后给afl进行fuzz。
queue用来存放触发了状态变换的测试样例,并且将测试样例送到afl去进行变异。
crashes存放触发crashes的输入。
最中心的afl-fuzz组件主要是产生输入的。一般是将测试样例进行添加,删除,变换若干个字符。产生的输入喂给右半部分的程序。程序将执行该输入的信息,比如覆盖率,反馈给afl-fuzz。要获取覆盖率这类信息,还需要afl-gcc,afl-clang-fast等编译器插桩来实现。

假设我们要测试library.c(如下)的代码,我们要如何测试呢?
void lib_echo(char *data, ssize_t len){
if(strlen(data) == 0) {
return;
}
char *buf = calloc(1, len);
strncpy(buf, data, len);
printf("%s",buf);
free(buf);
// A crash so we can tell the harness is working for lib_echo
if(data[0] == 'p') {
if(data[1] == 'o') {
if(data[2] =='p') {
if(data[3] == '!') {
assert(0);
}
}
}
}
}
int lib_mul(int x, int y){
if(x%2 == 0) {
return y << x;
} else if (y%2 == 0) {
return x << y;
} else if (x == 0) {
return 0;
} else if (y == 0) {
return 0;
} else {
return x * y;
}
}
教程告诉我们fuzz的准备工作有三:
(1)代码需要是可执行的。
(2)需要插桩,来让AFL高效地运行
(3)需要将fuzzer生成的数据送到库函数里。而这就需要写个harness来将外部输入送到库函数里。这个可以从命令行指定文件来实现或者直接在标准输入里输入。
为了测试上面的两个函数,我们写个main函数,来调用这个library.h的函数。
#include "library.h"
#include <string.h>
#include <stdio.h>
void main() {
char *data = "Some input data\n";
lib_echo(data, strlen(data));
printf("%d\n", lib_mul(1,2));
}
然后,使用下面的命令进行编译。
AFL_HARDEN=1 afl-clang-fast harness.c library.c -o harness
如果插桩成功,应该是如下结果:

但是如果就这样直接afl-fuzz ,会发现AFL提示:odd,check syntax!
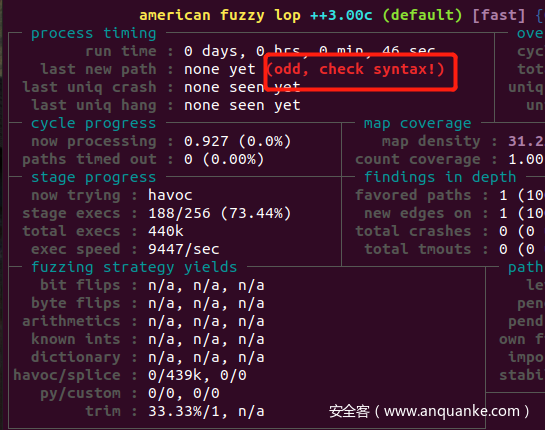
原因很明显,是因为刚刚写的harness根本没有从外部获取输入。所以,我们需要修改harness,让他从stdin获取输入,并且将输入喂给目标函数。如果对标准输入输出的概念不太了解,可以用man命令(man 3 stdin)简单了解一下。
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include "library.h"
// fixed size buffer based on assumptions about the maximum size that is likely necessary to exercise all aspects of the target function
#define SIZE 50
int main() {
// make sure buffer is initialized to eliminate variable behaviour that isn't dependent on the input.
char input[SIZE] = {0};
ssize_t length;
length = read(STDIN_FILENO, input, SIZE);
lib_echo(input, length);
}
现在再进行fuzz就不会有那个提示了。这个harness,只是在前面的基础上加了一个read函数,读取标准输入,并将输入作为lib_echo的参数。而afl可以自动生成输入,喂给stdin,从而将输入传到lib_echo,达到测试函数的目的。另外,也可以发现afl会将生成的输入直接从stdin传递,那么对于一些命令行程序,带argv参数那种,afl又是如何处理的呢?这个问题先放着,看后面做完挑战,是否能够得到解答。
接下来测试的lib_mul函数,这个函数需要两个输入,又要如何解决呢?作者给出的harness如下,主要看19到25行。就是多了个read函数输入第二个参数。
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include "library.h"
// fixed size buffer based on assumptions about the maximum size that is likely necessary to exercise all aspects of the target function
#define SIZE 100
int main(int argc, char* argv[]) {
if((argc == 2) && strcmp(argv[1], "echo") == 0) {
// make sure buffer is initialized to eliminate variable behaviour that isn't dependent on the input.
char input[SIZE] = {0};
ssize_t length;
length = read(STDIN_FILENO, input, SIZE);
lib_echo(input, length);
} else if ((argc == 2) && strcmp(argv[1], "mul") == 0) {
int a,b = 0;
read(STDIN_FILENO, &a, 4);
read(STDIN_FILENO, &b, 4);
printf("%d\n", lib_mul(a,b));
} else {
printf("Usage: %s mul|echo\n", argv[0]);
}
}
这部分主要是教怎么写harness,作者还给了个小练习。要求从argv读取文件名,并打开特定的文件,将内容读到一个缓冲区内,并将buffer内容传到目标函数里。简单写了一下,仅供参考。
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include "library.h"
// fixed size buffer based on assumptions about the maximum size that is likely necessary to exercise all aspects of the target function
#define SIZE 100
int main(int argc, char* argv[]) {
char input[SIZE] = {0};
FILE *fp = fopen(argv[1],"r");
ssize_t length;
fread(input,length,1,fp);
lib_echo(input, length);
fclose(fp);
}
接下来就开始测试真实程序~
Libxml2
第一个挑战是复现 CVE-2015-8317。
libxml2是一个热门的XML库。这类库很适合用来fuzzing,理由有六个:
(1)经常解析用户提供的数据
(2)使用不安全的语言写的
(3)无状态
(4)没有网络和文件系统交互
(5)官方发布的API是很好的目标,不需要去识别和隔离内部的组件
(6)快
这次的教程尝试复现CVE-2015-8317。
输入以下命令来对libxml编译插桩,并且加上ASAN的选项。
cd libxml2
CC=afl-clang-fast ./autogen.sh
AFL_USE_ASAN=1 make -j 4
然后接下来需要写个harness来测试libxml的几个核心函数。可以发现下面的harness中出现了很多下划线带AFL的函数。这些函数可以在AFL的LLVM模式的文档(https://github.com/google/AFL/blob/master/llvm_mode/README.llvm) 里找到说明。
这里主要说下AFL_LOOP(1000),这个指的是启用AFL的persistent 模式。对于一些无状态的API库,可以复用进程来测试多个测试样例,从而减少fork系统调用的使用,进而减少OS的开销。
#include "libxml/parser.h"
#include "libxml/tree.h"
#include <unistd.h>
__AFL_FUZZ_INIT();
int main(int argc, char **argv) {
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; // must be after __AFL_INIT
xmlInitParser();
while (__AFL_LOOP(1000)) {
int len = __AFL_FUZZ_TESTCASE_LEN;
xmlDocPtr doc = xmlReadMemory((char *)buf, len, "https://mykter.com", NULL, 0);
if (doc != NULL) {
xmlFreeDoc(doc);
}
}
xmlCleanupParser();
return(0);
}
编译harness。
AFL_USE_ASAN=1 afl-clang-fast ./harness.c -I libxml2/include libxml2/.libs/libxml2.a -lz -lm -o fuzzer
写个初始输入seed。
mkdir in
echo "<hi></hi>" > in/hi.xml
开始fuzz,-x表示设定fuzzer的字典。@@类似占位符,表示输入的位置。因为harness用的是argv作为输入,而不是stdin,所以这里用的是@@。
afl-fuzz -i in -o out -x /home/fuzzer/AFLplusplus/dictionaries/xml.dict ./fuzzer @@
大概跑了218min,可以发现出现了12个crash。

Heartbleed
这个challenge是复现著名的心脏滴血漏洞。
配置并build openssl
cd openssl
CC=afl-clang-fast CXX=afl-clang-fast++ ./config -d
AFL_USE_ASAN=1 make
harness:
#include <openssl/ssl.h>
#include <openssl/err.h>
#include <assert.h>
#include <stdint.h>
#include <stddef.h>
#include <unistd.h>
#ifndef CERT_PATH
# define CERT_PATH
#endif
SSL_CTX *Init() {
SSL_library_init();
SSL_load_error_strings();
ERR_load_BIO_strings();
OpenSSL_add_all_algorithms();
SSL_CTX *sctx;
assert (sctx = SSL_CTX_new(TLSv1_method()));
/* These two file were created with this command:
openssl req -x509 -newkey rsa:512 -keyout server.key \
-out server.pem -days 9999 -nodes -subj /CN=a/
*/
assert(SSL_CTX_use_certificate_file(sctx, "server.pem",
SSL_FILETYPE_PEM));
assert(SSL_CTX_use_PrivateKey_file(sctx, "server.key",
SSL_FILETYPE_PEM));
return sctx;
}
int main() {
static SSL_CTX *sctx = Init();
SSL *server = SSL_new(sctx);
BIO *sinbio = BIO_new(BIO_s_mem());
BIO *soutbio = BIO_new(BIO_s_mem());
SSL_set_bio(server, sinbio, soutbio);
SSL_set_accept_state(server);
/* TODO: To spoof one end of the handshake, we need to write data to sinbio
* here */
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
uint8_t data[100] = {0};
size_t size = read(STDIN_FILENO,data,100);
if (size == -1){
printf("Failed to read from stdin \n");
return (-1);
}
BIO_write(sinbio, data, size);
SSL_do_handshake(server);
SSL_free(server);
return 0;
}
写好harness后,编译。
AFL_USE_ASAN=1 afl-clang-fast++ -g handshake.cc openssl/libssl.a openssl/libcrypto.a -o handshake -I openssl/include -ldl
然后开始fuzz,这次采用的是stdin输入,所以就没有使用占位符@@了。
/home/fuzzer/workshop/AFLplusplus/utils/asan_cgroups/limit_memory.sh -u fuzzer afl-fuzz -i in -o out ./handshake
如果出现swapoff -a的提醒,需要在宿主机上使用命令swapoff -a暂时关闭交换分区。
大概跑10min以内会出现一个crash,我挂在那里跑了三个小时,也只有三个crash。
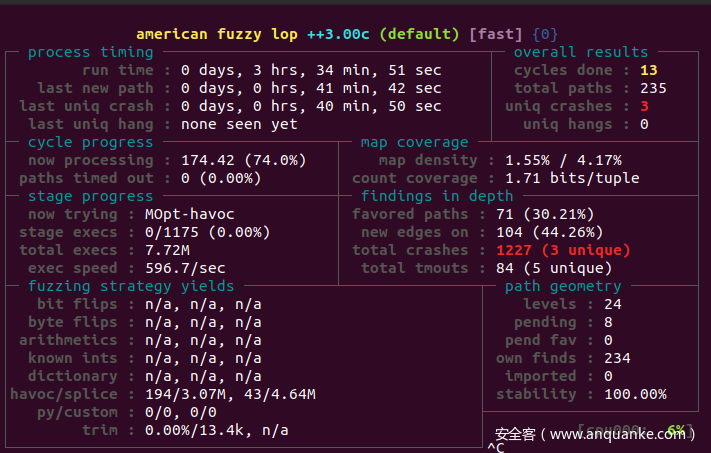
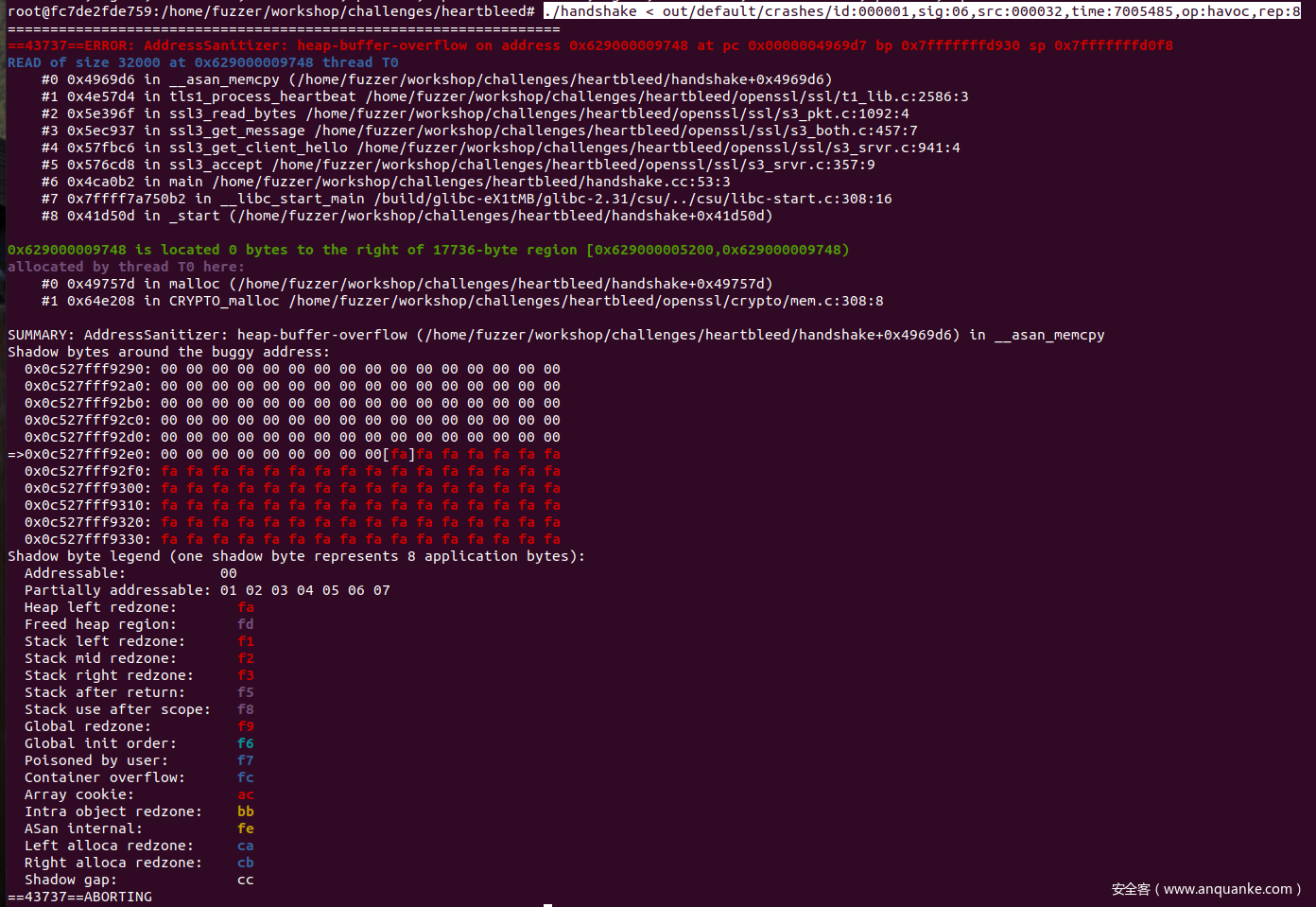
用生成的crash运行下源程序,会发现ASAN打印出了心脏滴血漏洞的相关信息。
ntpq
ntpq是向服务器查询信息,返回给用户的程序。这个challenge主要是看能不能找到CVE-2009-0159(https://xorl.wordpress.com/2009/04/13/cve-2009-0159-ntp-remote-stack-overflow/) 这个漏洞,以及如何用AFL测试这种网络服务类的应用程序。
在测试前,先写下test harness,将这个harness复制倒nptq的main函数里去。
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
int datatype=0;
int status=0;
char data[1024*16] = {0};
int length=0;
#ifdef __AFL_HAVE_MANUAL_CONTROL
while (__AFL_LOOP(1000)) {
#endif
datatype=0;
status=0;
memset(data,0,1024*16);
read(0, &datatype, 1);
read(0, &status, 1);
length = read(0, data, 1024 * 16);
cookedprint(datatype, length, data, status, stdout);
#ifdef __AFL_HAVE_MANUAL_CONTROL
}
#endif
return 0;
编译ntpq,注意是在ntpq4.2.2那个文件夹。另外一个4.2.8p10是修补过漏洞的。
CC=afl-clang-fast ./configure && AFL_HARDEN=1 make -C ntpq
然后进行fuzz,初始输入随便放点简单的字符串,我放了一个hello进去。
afl-fuzz -i in -o out -x ntpq.dict ntp-4.2.2/ntpq/ntpq
可以发现,才跑一会就冒出一大堆crash。
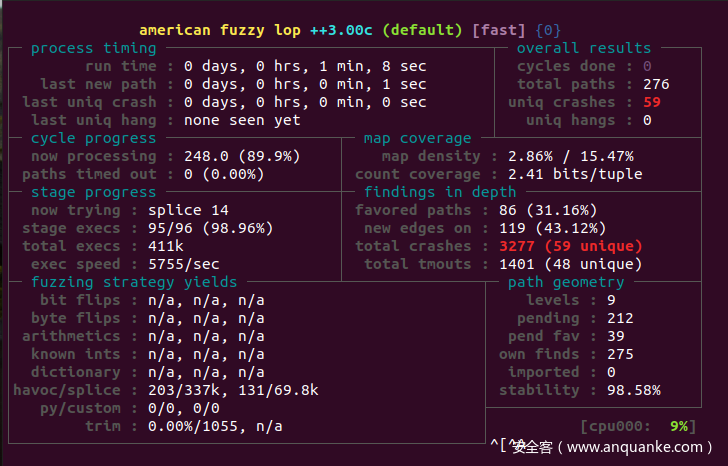
由于修补过的ntpq的cookedprint函数是6个参数了,所以之前的harness没法直接用了。直接使用修补过的ntpq的main函数进行fuzz,一时半会并没有跑出多少crash。
这次的challeng还附带了如何查询覆盖率的教程。
首先,加上覆盖率的选项对ntpq进行编译。
CC=clang CFLAGS="--coverage -g -O0" ./configure && make -C ntpq
然后运行插桩后的ntpq,输入为queue里的所有文件。这些文件对应着触发新路径的输入。
for F in out/default/queue/id* ; do ./ntp-4.2.8p10/ntpq/ntpq < $F > /dev/null ; done
然后编译覆盖率信息为gcov的report。
cd ./ntp-4.2.8p10/ntpq/ && llvm-cov gcov ntpq.c
查看覆盖率的报告。
./ntp-4.2.8p10/ntpq/ntpq.c.gcov
可以发现行号前面多了数字,井号和减号。井号表示没有执行该行。减号表示这行没有代码。
sendmail
这次的challenge主要是研究初始输入seed对于fuzzer的影响。复现的CVE是:CVE-1999-0206, https://samate.nist.gov/SRD/view_testcase.php?tID=1301
由于这次的testharness已经写好了,我们只要输入以下命令,编译sendmail程序,设置初始输入seed为a,然后开始fuzz。
make clean
CC=afl-clang-fast make
mkdir in
echo a > in/1
afl-fuzz -i in -o out ./m1-bad @@
大约过了20s,afl发现了crash。
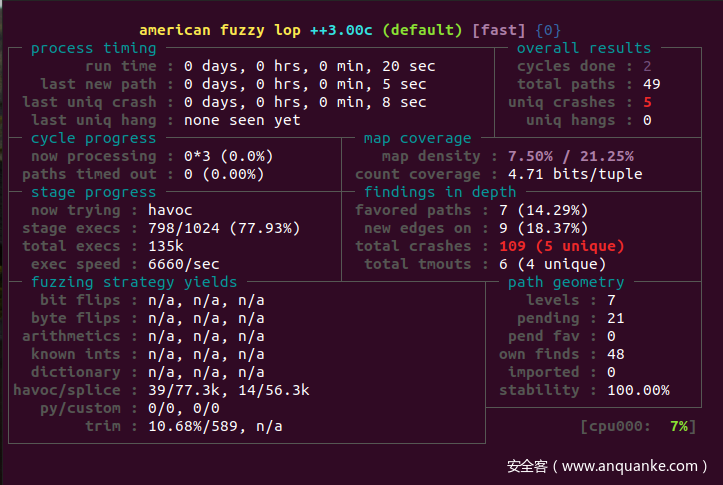
现在让我们修改一下seed,再跑一下看看。
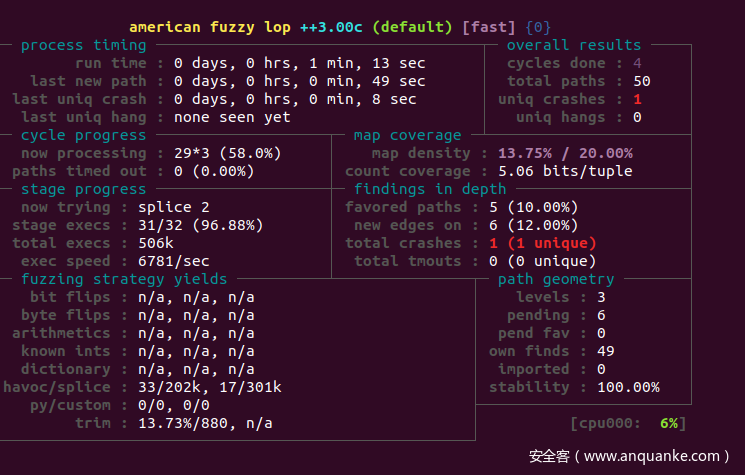
echo -e "a=\nb=" > in/multiline
直到过了1分钟才发现crash。emm这和作者说的不一样啊。看起来AFL有很大的玄学成分。
然后可以尝试把生成的crash,用afl-tmin处理一下,得到精简的测试样例。
afl-tmin -i id:000000,sig:06,src:000047,time:11346,op:havoc,rep:8 -o shrinked ../../../m1-bad @@
我试了6个crash的测试样例,分别得到如下精简后的测试样例。发现这几个都还挺像的,但是又不完全一样。
#1
0000000000000000000000000000000000000000000=
000000000000000000000000000=
#2
0000000000000000000=
0000000000000000000000000000000=
00000000000000000000=
#3
0000000000000000000000000000000000000=
000000000000000000000000000000000=
#4
000000000000000000000000000000000000=
0000000000000000000000000000000000=
#5
00000000000000000000000000000000000000000000=
00000000000000000000000000=
#6
00000000000000000000000000=
00000000000000000000000000000000000000000000=
官方的answer.md给出的结论是:没得到相同的结果是afl-tmin并不能在不触发crash的情况下精简输入,所以他们是不同的。(暂时没理解为啥)
1305文件夹里是CVE-2003-0161(https://samate.nist.gov/SRD/view_testcase.php?tID=1305) 。Fuzz的流程和前面一样,写harness,编译,设置初始输入,调用afl-fuzz进行fuzz:
cp prescan-overflow-bad-fuzz.c prescan-overflow-bad.c # 直接用作者写好的harness
CC=afl-clang-fast AFL_USE_ASAN=1 make #编译
echo -n "michael@mykter.com" > in/seed #设置初始输入为邮箱地址
afl-fuzz -i in -o out ./prescan-bad
这个漏洞需要AFL多花些时间才能找到。等生成crash的测试样例后,会发现输入有一堆反斜杠。同时,还会有很多0xFF字符。然而需要触发漏洞的话,需要的是一连串的<0xff>对。通过对测试样例突变,afl最终会找到触发漏洞的样例。AFL在某个时候触发漏洞,但是我们并不知道afl啥时候会找到。所以这是个很好的例子去判断什么时候停止fuzzing。AFL会快速的跑完好多周期,但没有新增的路径。由于这些周期时间比较短,就导致代码覆盖率工具很有可能会显示覆盖率达到了100%。
可以采用Deferred initialization的方式来提高AFL的性能,大概提高1.5x,最合适的地方是放在read函数前。也就是下面这几行代码。
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
另外,就是持久化模式可以提高4x的性能。因为这个测试程序很小,大概只要扫描五十个字符串,所以fork占用了很大部分的时间。但这样做安全吗?在第一个循环后的测试还有代表性吗?所以需要确认全局变量保留的状态不会影响后续调用parseaddr函数的过程。如果发现这样做不安全,为了性能考虑,可以考虑将harness修改成无状态的。
date
本次的challenge是去复现CVE-2017-7476,一个由环境变量引起的漏洞。
编译date
cd coreutils
./bootstrap #可能会有一些带po后缀文件的错误,但可以忽视
patch --follow-symlinks -p1 < ../coreutils-8.29-gnulib-fflush.patch#不然make会报错
CC=afl-clang-fast ./configure #如果是root用户需要加上这个选项FORCE_UNSAFE_CONFIGURE=1
AFL_USE_ASAN=1 make
./src/date
这个bug主要是由环境变量引起的。当我们运行date命令时,加上环境变量会导致不同的程序执行命令。
./src/date
Sat Sep 25 00:52:42 UTC 2021
TZ='Asia/Tokyo' ./src/date #加上环境变量TZ后
Sat Sep 25 09:53:06 JST 2021
可以先运行下poc看看结果
TZ="aaa00000000000000000000aaaaaab00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000" ./src/date --date "2017-03-14 15:00 UTC"
不出意外应该可以看到ASAN报出了堆溢出。
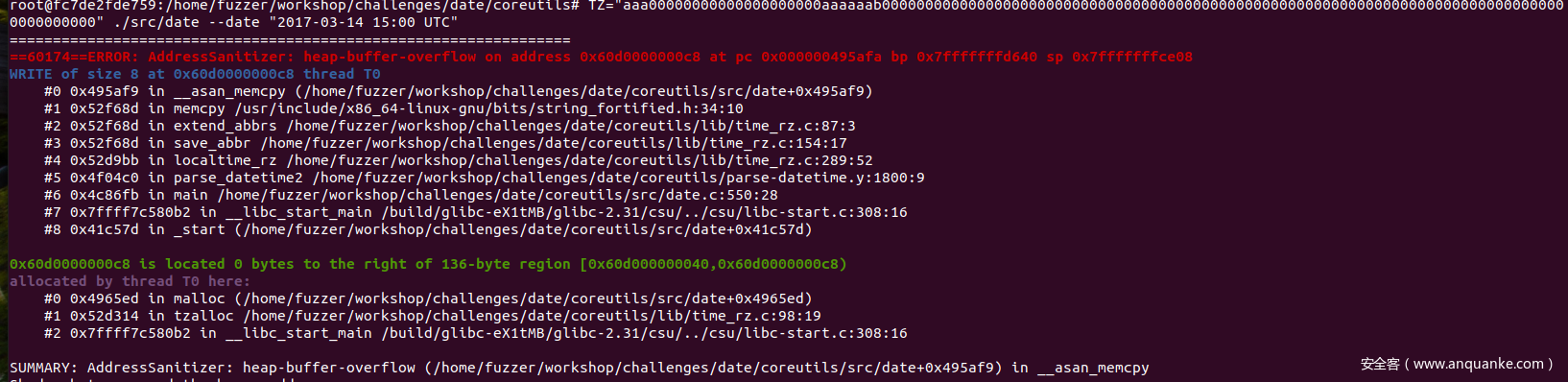
那么如何fuzz环境变量呢?
HINT.md给出了三个方案:
(1)找到源码里所有读取环境变量TZ的地方,然后替换为从stdin读取。
(2)写一个harness,来设置环境变量,然后修改date.c的main函数
(3)使用LD_PRELOAD来代替getenv函数的调用,这样就可以将环境变量的值传到标准输入里去
Answer.md推荐使用第二种方案。
对于第一种方案,需要覆盖代码中的每一部分,很难确定每个地方都替换了stdin。
对于第三种方案,虽然重用性比较高,但是就入门而言,需要花费的功夫还是比较多。
添加下列代码到src/date.c的main函数的开始。这部分代码是参考AFL的utils/bash_shellshock 文件夹下的补丁来实现的。主要是从标准输入读取一个值,将这个值设置为环境变量,从而达到了实现fuzz环境变量的目的。
static char val[1024 * 16];
read(0, val, sizeof(val) - 1);
setenv("TZ", val, 1);
然后重新编译。
make clean
AFL_USE_ASAN=1 make -j
试着运行程序,可以发现我们修改成功了。
./src/date
Europe/London #标准输入
Sat Sep 25 01:23:30 Europe 2021 # 标准输出
设置种子输入,并进行fuzz
echo -n "Europe/London" > in/london
#使用ASAN的fuzz
/home/fuzzer/AFLplusplus/utils/asan_cgroups/limit_memory.sh -u root afl-fuzz -i in -o out -- src/date --date "2017-03-14T15:00-UTC"
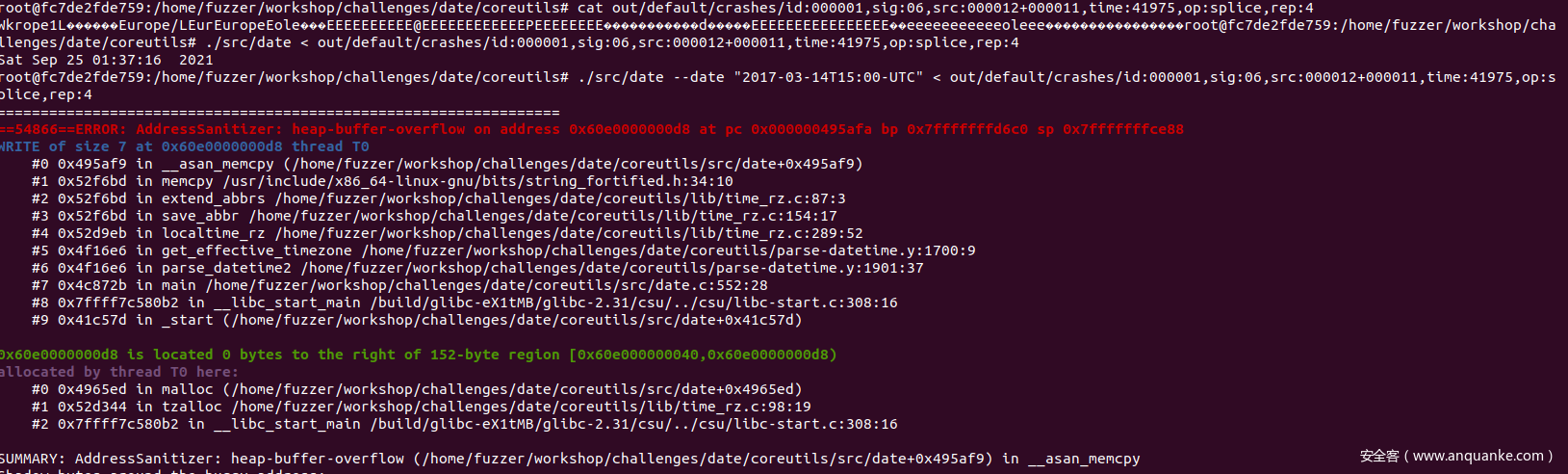
挖了三分钟就有三个crash了,让我们来看看挖到的crash是不是前面的PoC。
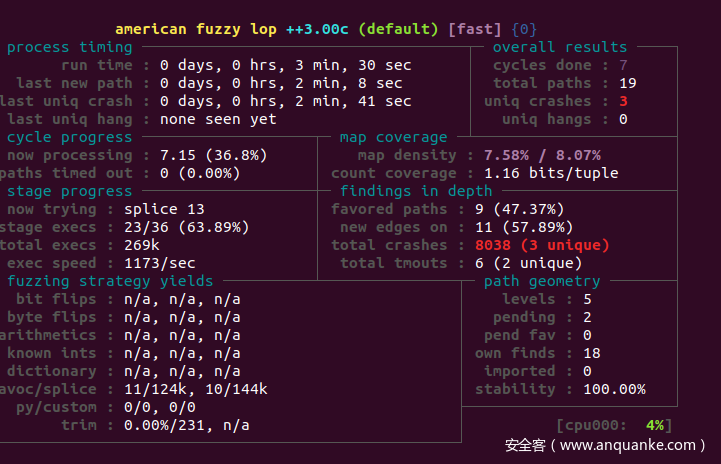
运行crash
./src/date --date "2017-03-14T15:00-UTC" < out/default/crashes/id:000001,sig:06,src:000012+000011,time:41975,op:splice,rep:4
可以发现我们成功复现了CVE。也说明fuzz环境变量那边成功了。
cyber-grand-challenge
最后的challenge是CGC比赛的一个二进制。程序里有两个漏洞,一个容易找,一个很难用fuzzing找。
编译
CC=afl-clang-fast AFL_HARDEN=1 make
afl-fuzz -i in -o out ./cromu_00007
跑了20分钟,发现了6个crash。

简单用afl-tmin看了下,这几个crash应该都是同一个类型的。
另外,教程中还用afl-analysis分析了一下sample样例
afl-analyze -i sample.input ./cromu_00007
会得到下面的结果。
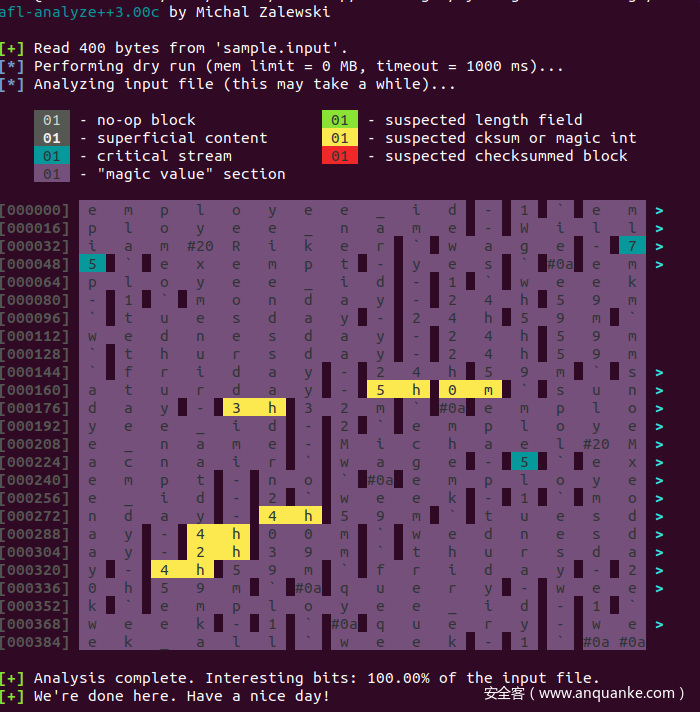
如果用导致crash的输入用afl-analysis分析,会发现得到的结果会超级长,而且有很多checksummed block。这么来看,好像体现出了正常输入和异常输入的区别。就是不知道原理是啥,感觉是不是有些机器学习的工作可以基于这些数据来进行分类。
总结
之前对AFL只有一个比较模糊的认识,这次做完workshop之后,才发现AFL并不像我以前认为的是那么万能的,也并不是一个傻瓜式工具。如何写test harness,如何溯源crash,什么时候停止fuzz,什么情况下使用AFL的一些选项(持久化模式等)都有一定的讲究。在复现漏洞时,也时常让我惊叹,卧槽,这么快就挖到洞了。当然,也有的时候,跑了很久一个crash都没有,比如sendmail的1305那个挑战。后续可能会在去看看进阶的workshop的内容(https://github.com/antonio-morales/EkoParty_Advanced_Fuzzing_Workshop)。
这次的学习记录感觉写得有点水,建议大家还是直接看workshop的文档,做完了workshop再看这篇像是实验报告的文章,也许会别有一番滋味。
参考链接:
[1] AFL的LLVM Mode, https://kiprey.github.io/2020/07/AFL-LLVM-Mode/
[2] AFL的LLVM 模式官方文档, https://github.com/google/AFL/blob/master/llvm_mode/README.llvm
[3] CVE-2003-0161, https://samate.nist.gov/SRD/view_testcase.php?tID=1305
[4] CVE-1999-0206, https://samate.nist.gov/SRD/view_testcase.php?tID=1301
[5] CVE-2009-0159:https://xorl.wordpress.com/2009/04/13/cve-2009-0159-ntp-remote-stack-overflow/
[6] Fuzzing with workshop : https://github.com/mykter/afl-training (这个链接里还有很多优质的参考资料)
[7] Advanced Fuzzing workshop:https://github.com/antonio-morales/EkoParty_Advanced_Fuzzing_Workshop







发表评论
您还未登录,请先登录。
登录