

前言:
最近啃了FuzzingBook,然后记录一个关于入坑fuzzing的学习历程
Fuzzing简介:
首先是关于软件测试:
软件测试主要是三种方式:
- 手工测试
- 半自动化测试
- 自动化测试
作者觉得Fuzzing是一种介于自动化和半自动化的测试方法
其核心思想是自动或半自动的生成随机数据输入到一个程序中,并监视程序异常,如崩溃,断言(assertion)失败,以发现可能的程序错误,比如内存泄漏。模糊测试常常用于检测软件或计算机系统的安全漏洞。
——维基百科:模糊测试
就Fuzzing来说,模糊测试主要有两个重要的模块组成Fuzzer和Runner
下面是其类图:
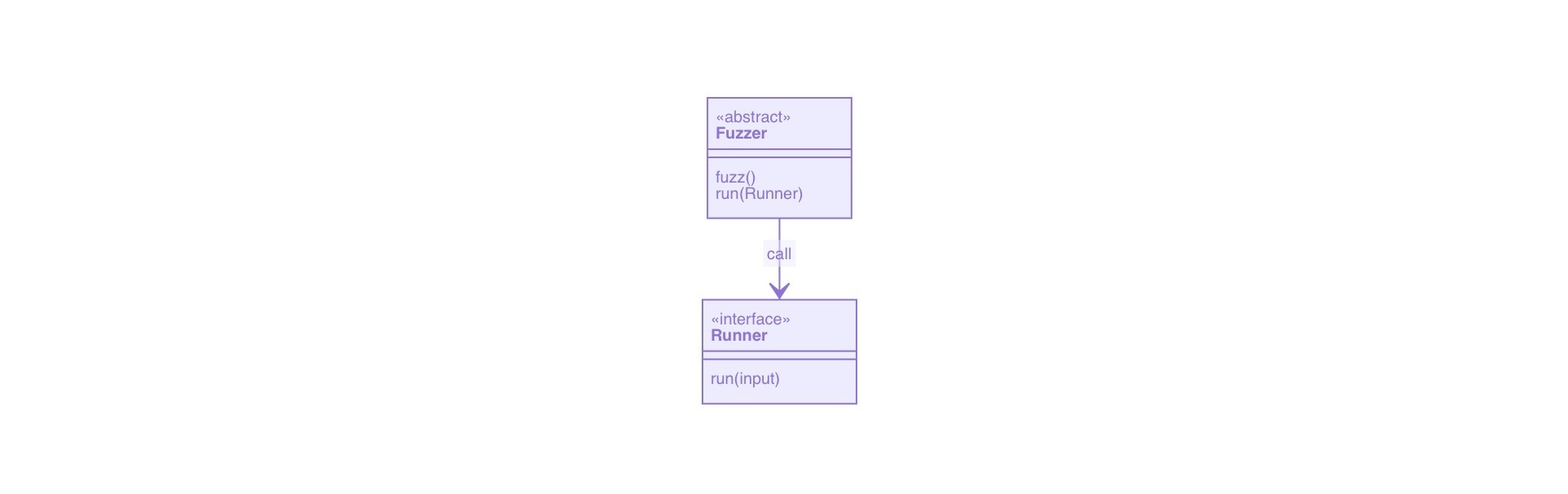
一个很简单的调用关系来进行简单的包装,Runner类主要负责将数据输入程序,以及监控程序的运行状态,这次我们先重点介绍Fuzzer
Fuzzer
对于模糊测试来说,很重要的一点就是对数据进行模糊处理,所以一般在实现上都会单独把Fuzzer模块抽离出来
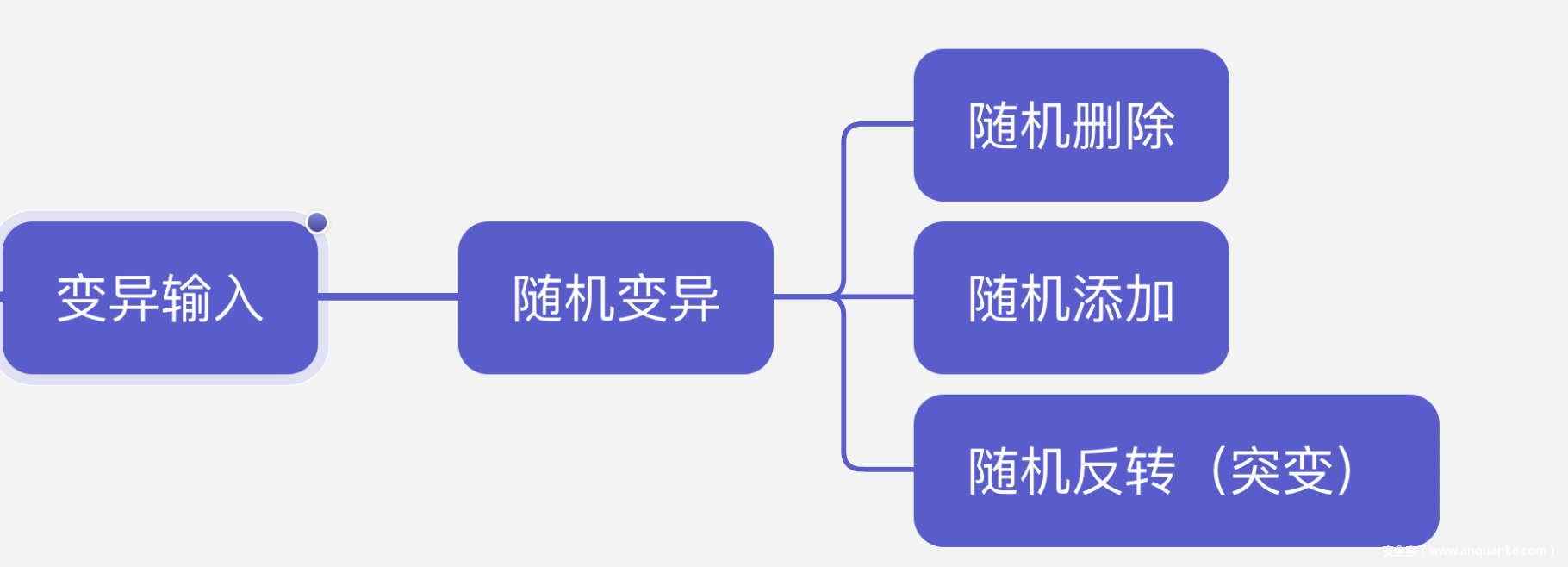
如上图所示,对于数据变异常用的三种基础的方式是随机删除,随机添加,随机反转(filp),下面是简单的实现代码,我们后续的工作也是基于其来进行的构建
def del_random_chr(s):
if s is None:
return self.insert_random_chr(s)
pos = random.randint(0, len(s))
return s[:pos]+s[pos+1:]
def insert_random_chr(s):
pos = random.randint(0, len(s))
new_s = chr(random.randrange(32, 127))
return s[:pos]+new_s+s[pos:]
def flip_random_chr(s):
if s is None:
return self.insert_random_chr(s)
pos = random.randint(0, len(s)-1)
bit = 1<<random.randint(0, 6)
return s[:pos]+chr(ord(s[pos])^bit)+s[pos+1:]
为了跟完善一点,在fuzzingbook中,作者将其包装成一个类
class Mutator(object):
def __init__(self):
self.mutators = [
self.del_random_chr,
self.insert_random_chr,
self.flip_random_chr
]
def del_random_chr(self, s:str):
if s is None:
return self.insert_random_chr(s)
pos = random.randint(0, len(s))
return s[:pos]+s[pos+1:]
def insert_random_chr(self, s:str):
pos = random.randint(0, len(s))
new_s = chr(random.randrange(32, 127))
return s[:pos]+new_s+s[pos:]
def flip_random_chr(self, s:str):
if s is None:
return self.insert_random_chr(s)
pos = random.randint(0, len(s)-1)
bit = 1<<random.randint(0, 6)
return s[:pos]+chr(ord(s[pos])^bit)+s[pos+1:]
def mutate(self, s):
mutator = random.choice(self.mutators)
return mutator(s)
在这一部分中,主要是包装数据进行基础变异处理的一些方法,还不能成为Fuzzer
下面是一个Fuzzer的基类
class Fuzzer(object):
def __init__(self):
pass
def fuzz(self):
return ""
def run(self, runner:Runner=Runner()):
return runner.run(inp=self.fuzz())
def runs(self, runner:Runner=PrintRunner(), trials=10):
outcomes = [self.run(runner) for i in range(trials)]
return outcomes
基类的构建主要是为了Runner和Fuzzer联系起来,可以看见其仅仅提供基础的run方法,主要是将我们进行fuzz处理后的数据输入到Runner里面去,由Runner传递给我们Target程序
有了上面的基础部件,我们下面就能够实现一个简单突变Fuzzer
class Seed(object):
def __init__(self, data):
self.data = data
def __str__(self):
return self.data
__repr__ = __str__
class PowerSchedule(object):
def assignEnergy(self, population):
for seed in population:
seed.energy = 1
def normalizedEnergy(self, population):
energy = list(map(lambda seed: seed.energy, population))
sum_energy = sum(energy)
norm_energy = list(map(lambda nrg: nrg/sum_energy, energy))
return norm_energy
def choose(self, population):
self.assignEnergy(population)
norm_energy = self.normalizedEnergy(population)
seed = np.random.choice(population, p=norm_energy)
return seed
class MutationFuzzer(Fuzzer):
def __init__(self, seeds, mutator, schedule):
self.seeds = seeds
self.mutator = mutator
self.schedule = schedule
self.inputs = []
self.reset()
def reset(self):
self.population = list(map(lambda x: Seed(x), self.seeds))
self.seed_idx = 0
def create_candidate(self):
seed:Seed = self.schedule.choose(self.population)
candidate = seed.data
trials = min(len(candidate), 1 << random.randint(1, 5))
for i in range(trials):
candidate = self.mutator.mutate(candidate)
return candidate
def fuzz(self):
if self.seed_idx < len(self.seeds):
self.inp = self.seeds[self.seed_idx]
self.seed_idx += 1
return self.inp
self.inp = self.create_candidate()
self.inputs.append(self.inp)
return self.inp
- Seed类主要是为了对种子数据进行一些包装,使得我们能够赋予种子数据一些相关数据,方便我们后续对数据的处理
- PowerSchedule类相当于一个调度表,主要目的是为了通过种子数据的权级关系来引导后续数据的生成,简单点说,就是对种子数据的权重进行管理
- 相对核心的MutationFuzzer类,其继承于Fuzzer基类,同时能将我们的所给种子数据进行突变模糊
测试代码:
seed_input = "http://www.google.com/search?q=fuzzing"
mutation_fuzzer = MutationFuzzer(seeds=[seed_input], mutator=Mutator(), schedule=PowerSchedule())
for i in range(10):
print(mutation_fuzzer.fuzz())
输出:
$> python3 mutator_test.py
http://www.google.com/search?q=fuzzing
http:/ww.gooc:le.co/earcH?q<nuzinYg
ht#tp!://ww7.gogle&com/seamrch?q=cfuozzing
zLIhtp:/www.g1oogxencOm/bpsgarch?qw=fuzzing
ht+t[r/www.google.com/search?1=furzng
`ttq:3/7wg.goggne>com/sarch?=uuzinw
http://www.google.com[/search?q=fuzzing;
http://www.g%oogl.c`omd-se]rc?qfi9o
htp:/cww.qgoglg.coi/search?pfuzajg
http:/+www.eoogle.coe/ search?q=fuzzing
确实将数据进行了模糊处理,但其似乎太发散了,基本不在我们可控范围内,所以我们需要考虑一种方案,其能够引导我们的Fuzzer来生成数据,相当于一种具有引导性的Fuzzer,所以我们需要学习一个新的概念:Code Coverage(代码覆盖率)
Code Coverage:
代码覆盖(英语:Code coverage)是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。 ——维基百科:代码覆盖率
关于代码覆盖率,其实顾名思义,说简单了也就是我们输入的数据,能够让程序的那些代码得倒执行以及其执行的次数,包括其执行次数占总数的一个比例。
在FuzzingBook中,其作者举了一个🌰:
/* CGI decodeing as c program */
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define DEBUG 0
typedef unsigned int bool;
bool true = 1;
bool false = 0;
int hex_values[256];
#define HEX_VALUES_LENGTH sizeof(hex_values)/sizeof(int)
void init_hex_values() {
for (int i = 0; i < HEX_VALUES_LENGTH; i++) {
hex_values[i] = -1;
}
for (char i='0'; i<='9'; i++) {
hex_values[i] = i-'0';
}
for (char i='a'; i<='f'; i++) {
hex_values[i] = i-'a'+0xa;
}
for (char i='A'; i<='F'; i++) {
hex_values[i] = i-'A'+0xA;
}
}
bool cgi_decode(char *s, char *t) {
while (*s!='\0')
{
switch (*s)
{
case '+':
*t++ = ' ';
break;
case '%':
{
int dight_high = *++s;
int dight_low = *++s;
if (hex_values[dight_high]<0 && hex_values[dight_low]<0) {
return false;
}
*t++ = (hex_values[dight_high]<<4) + hex_values[dight_low];
}
break;
default:
*t++ = *s;
break;
}
s++;
}
*t = '\0';
return true;
}
int main(int argc, char const *argv[])
{
init_hex_values();
// #if DEBUG
// for (int i=0; i<HEX_VALUES_LENGTH; i++) {
// printf("%c:0x%x\n", i, hex_values[i]);
// }
// #endif
if (argc>=2) {
char* s = (char*)argv[1];
char* t = malloc(strlen(s)+1);
bool ret = cgi_decode(s, t);
printf("%s\n", t);
return ret;
}
printf("cgi_decode: usage: cgi_decode STRING\n");
return 0;
}
终端:
$> gcc cgi_decode.c --coverage -o cgi_decode
$> ./cgi_decode 'Send+mail+to+me%40fuzzingbook.org'
$> gcov cgi_decode.c
File 'cgi_decode.c'
Lines executed:92.86% of 42
cgi_decode.c:creating 'cgi_decode.c.gcov'
然后在生成的.c.gcov文件中如图所示
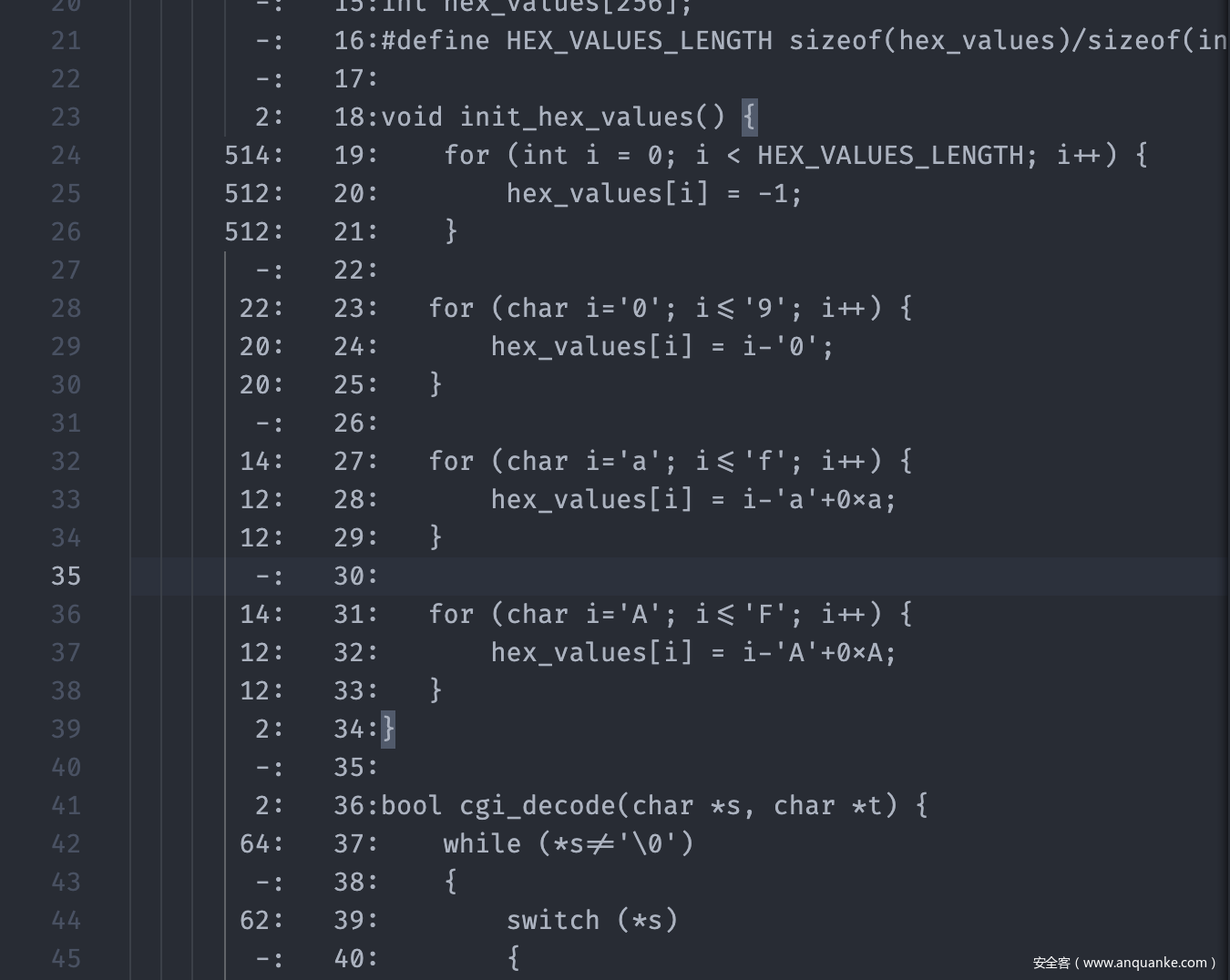
最左边就是每一行代码执行到的次数
对于python代码,作者构建了一个Coverage类来记录代码覆盖率:
class Coverage(object):
def traceit(self, frame, event, arg):
if self.original_trace_function is not None:
self.original_trace_function(frame, event, arg)
if event == "line":
function_name = frame.f_code.co_name
lineno = frame.f_lineno
self._trace.append((function_name, lineno))
return self.traceit
def __init__(self):
self._trace = []
def __enter__(self):
self.original_trace_function = sys.gettrace()
sys.settrace(self.traceit)
return self
def __exit__(self, exc_type, exc_value, tb):
sys.settrace(self.original_trace_function)
def trace(self):
return self._trace
def coverage(self):
return set(self.trace())
这样的话就可以通过这个Coverage类来使用with语句来记录代码覆盖率
测试代码:
with Coverage() as cov:
cgi_decode("a+b")
print(cov.coverage())
终端:
$> python3 coverage_test.py
{('cgi_decode', 24), ('cgi_decode', 30), ('cgi_decode', 43), ('cgi_decode', 33), ('cgi_decode', 23), ('__exit__', 38), ('cgi_decode', 32), ('cgi_decode', 45), ('cgi_decode', 29), ('cgi_decode', 25), ('cgi_decode', 22), ('cgi_decode', 28), ('cgi_decode', 44), ('cgi_decode', 31), ('cgi_decode', 21), ('cgi_decode', 34)}
了解代码覆盖率之后,我们就可以使用代码覆盖率,来引导我们的Fuzzer来生成数据,相当于一种具有引导性突变的Fuzzer,我们称为GreyboxFuzzer,下面是实现这个类的代码
class GreyboxFuzzer(MutationFuzzer):
def reset(self):
super().reset()
self.coverages_seen = set()
self.population = []
def run(self, runner: Runner):
result, outcome = super().run(runner=runner)
new_coverage = frozenset(runner.coverage())
if new_coverage not in self.coverages_seen:
seed = Seed(self.inp)
seed.coverage = runner.coverage()
self.coverages_seen.add(new_coverage)
self.population.append(seed)
return (result, outcome)
在MutationCoverageFuzzer类的Run方法中,我们实际上至少比较了每一次Runner执行后的,其输入的数据是否让程序执行到新的代码块,如果有则记录下来,同时将这一次的数据加入到进行帅选到种子列表中,作为下次突变的数据种子,这样就有机会让我们Fuzzer生成出来的数据能够广的代码覆盖率。
下面是MutationFuzzer和GreyboxFuzzer的测试对比, 依然使用FuzzingBook中的测试例子,也是一个很有趣的🌰
Target程序代码:
def crashme (s):
if len(s) > 0 and s[0] == 'b':
if len(s) > 1 and s[1] == 'a':
if len(s) > 2 and s[2] == 'd':
if len(s) > 3 and s[3] == '!':
raise Exception()
MutationFuzzer测试代码:
seed_input = "good"
blackbox_fuzzer = MutationFuzzer([seed_input], Mutator(), PowerSchedule())
n = 30000 # 测试次数
blackbox_runner = FunctionCoverageRunner(crashme)
with Timer() as t:
blackbox_fuzzer.runs(blackbox_runner, trials=n)
all_cov, greybox_coverage = population_coverage(blackbox_fuzzer.inputs, crashme)
print(t.elapsed_time())
print(all_cov)
print(max(greybox_coverage))
终端:
$> python3 mutator_test.py
1.489651209
{('crashme', 3), ('__exit__', 38), ('crashme', 2)}
3
GreyboxFuzzer测试代码
seed_input = "good"
n = 30000
greybox_fuzzer = GreyboxFuzzer([seed_input], Mutator(), PowerSchedule())
runner = FunctionCoverageRunner(crashme)
with Timer() as t:
greybox_fuzzer.runs(runner, trials=n)
all_cov, greybox_coverage = population_coverage(greybox_fuzzer.inputs, crashme)
print(t.elapsed_time())
# print(runner.coverage())
print(all_cov)
print(max(greybox_coverage))
print(greybox_fuzzer.population)
终端:
$> python3 greyboxFuzzer.py
1.7056656000000001
{('crashme', 3), ('crashme', 6), ('crashme', 2), ('crashme', 5), ('crashme', 4), ('__exit__', 38)}
6
[good, bEgd, bar$Egdi, badEdi, bad!Egi]
下面是FuzzingBook所给出的一张对比图,可以直观的发现,没有代码覆盖率引导的普通数据变异很难覆盖完程序的路径,而通过代码覆盖率的引导,Fuzzer生成的数据能逐渐的覆盖程序的路径。
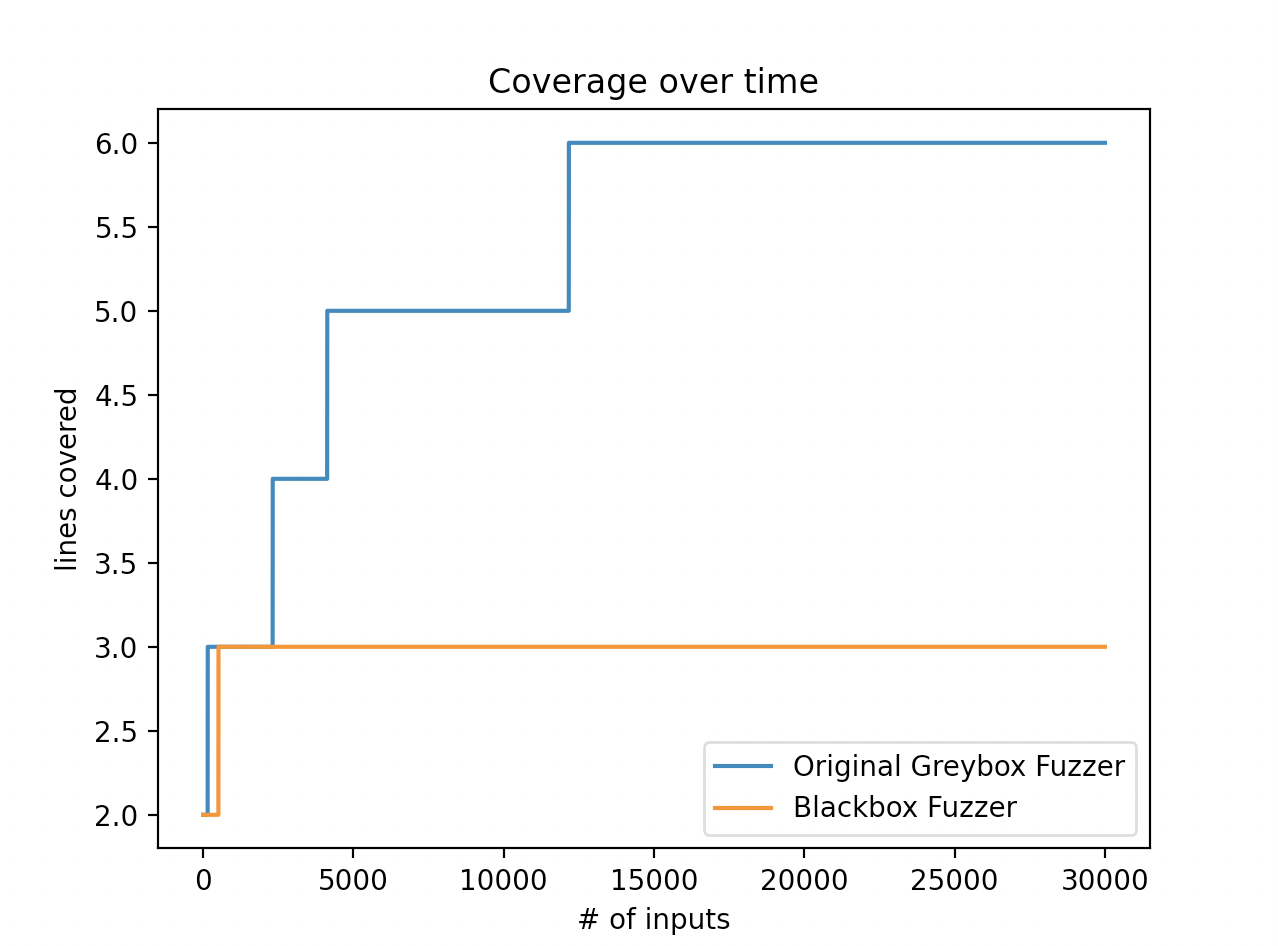
AFLFastSchedule:
在我们Fuzz crashme这个例子中,通过上节的实验我们可以发现使用代码覆盖率来引导我们的Fuzzer,可以使其变得更有目的性的去生成变异数据,但其耗时还是相对较长,且fuzzing出来的的数据也相对较多,那么有没有优化的方案呢?
在FuzzingBook中,作者使用如下公式来计算种子数据的权重
e(s) =\frac{1}{f(p(s))^e}
实际上很容易理解:
- s是种子,作为一个参数
- 函数p用来获取该种子所覆盖的路径hash值
- 函数f用来获取该路径已经被种子覆盖的次数
- e是一个指数常量,用来扩大数量级,通过调整这个e的常量值,我们能减少fuzz的次数, 来提升fuzzer的效率
AFLFastSchedule类实现代码:
class AFLFastSchdule(PowerSchedule):
def __init__(self, exponent):
self.exponent = exponent
self.path_frequency = {}
def assignEnergy(self, population:List[Seed]):
for seed in population:
seed.energy = 1 / (self.path_frequency[getPathID(seed.coverage)] ** self.exponent)
AFLFastSchedule类继承PowerSchedule,重写了assignEnergy方法,重新通过上诉公式来计算种子的权重
CountGreyboxFuzzer类实现代码:
class CountingGreyboxFuzzer(GreyboxFuzzer):
def __init__(self, seeds, mutator: Mutator, schedule: AFLFastSchdule):
super().__init__(seeds, mutator, schedule)
self.schedule = schedule
def reset(self):
return super().reset()
def run(self, runner: Runner):
result, outcome = super().run(runner)
path_id = getPathID(runner.coverage())
if path_id not in self.schedule.path_frequency:
self.schedule.path_frequency[path_id] = 1
return result, outcome
self.schedule.path_frequency[path_id] += 1
return result, outcome
CountGreyboxFuzzer类继承GreyboxFuzzer,主要重写run方法,将检测代码路径是否已被执行替换为增加路径已执行次数,相比较原来的普通greyboxFuzzer,这样当下一次种子调度器在帅选种子时,就有权重变化了。
通过公式的描述,我们可以发现当一个路径被覆盖多次时,他的权重会减少,而较新的路径的权重反而更大,而目前我们的种子调度器帅选种子主要依赖其权重,那么这就相当于种子调度器在帅选种子来进行变异时,会逐渐逐渐往新路径选择,这在一定程度上更能引导我们的Fuzzer去变异出代码覆盖率更广的数据。
下面是实验结果:
Test_CountingGreyboxFuzzer:
def test_countingGreyboxFuzzer(e):
seed_input = "good"
exponent = e
n = 10000
fast_schedule = AFLFastSchdule(exponent)
bostgreybox_fuzzer = CountingGreyboxFuzzer([seed_input], Mutator(), fast_schedule)
runner = FunctionCoverageRunner(crashme)
with Timer() as t:
bostgreybox_fuzzer.runs(runner, trials=n)
_, bostgreybox_coverage = population_coverage(bostgreybox_fuzzer.inputs, crashme)
print(t.elapsed_time())
# print(all_cov)
print(max(bostgreybox_coverage))
print(bostgreybox_fuzzer.population)
print(fast_schedule.path_frequency)
当e常量为5,fuzz次数为10000时
终端:
$> python3 greyboxFuzzer_test.py
0.723850758
6
[good, bg, ba, bad, bad!]
{'457ea827d94ad12c048397ad55d1d030': 6005, '193f98a7531d0e9a97a787562b595798': 2743, '80819e22a0983ebc96997fa6fe569ca8': 942, '00deafe57bb3539da4ee5a01d5fb4ebe': 260, 'c9a83c563333fdb248e6a10e56aa1f12': 50}
当我们调整e为15,trials为4000时
终端:
$> python3 greyboxFuzzer_test.py
0.251615932
6
[good, bg=oyodx, ba7g=oyodz,, badBag(yoC>,, bad!sgymIn}C1<]
{'fbdecb7cc922b14d42f4a4a4d5dc191a': 1318, 'a2229a3e7370c6970c660ec9f7e2a67b': 763, '1968f4fca86e35f60decaae9699c760d': 502, '4ea124940551c3bbb6d1f68e8337375e': 212, '79723bb9baab9395463be50202282c3e': 205}
可以发现,通过一定调整exponent常量,我们可以接近一个更有效率的测试次数值
下图是三个不同的Fuzzer的效率对比
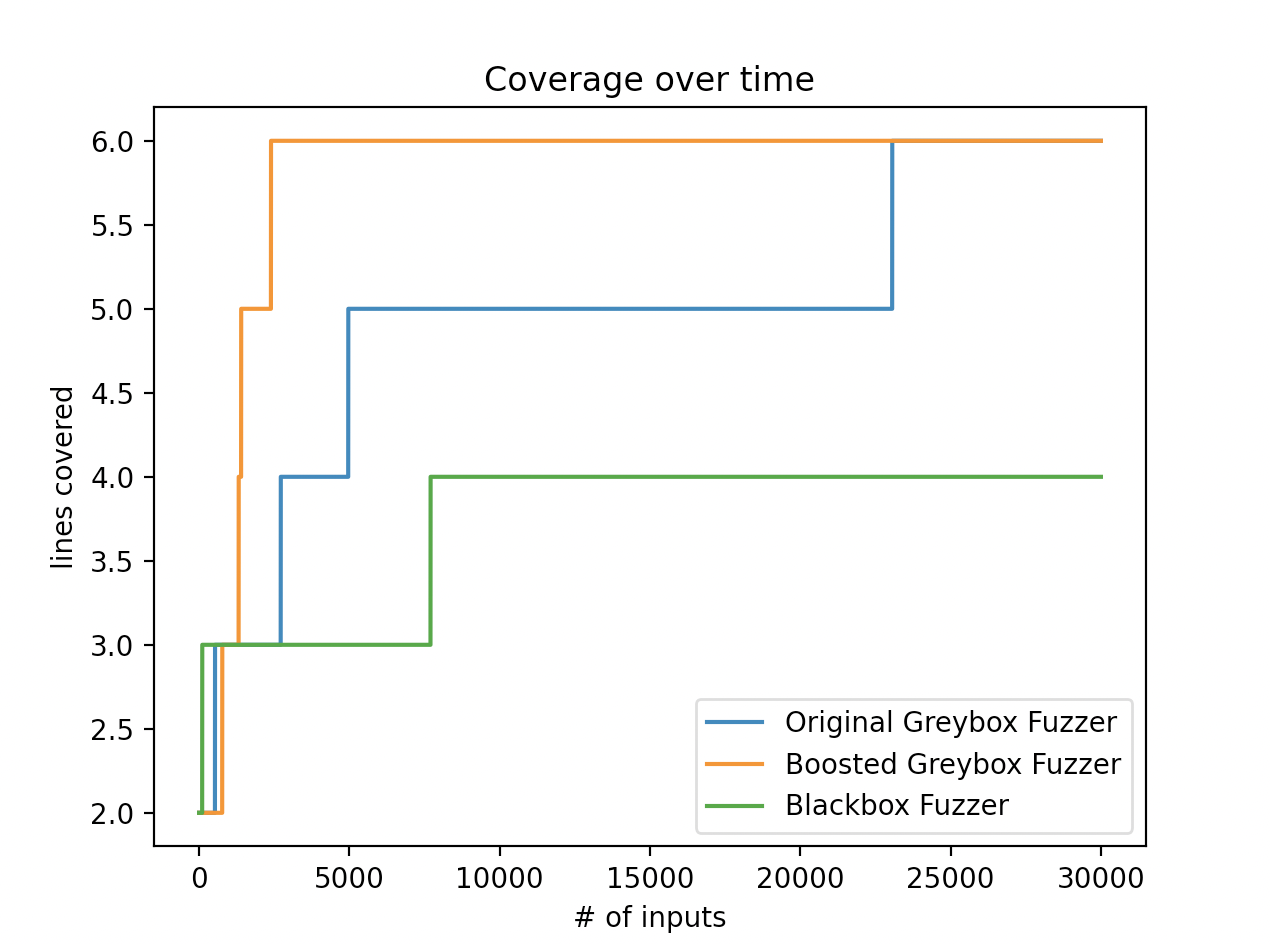
我们可以发现,使用AFLFastSchedule优化过的Fuzzer在三者之中覆盖crashme的效率确实是要更快的多。
总结
通过该部分的学习,我们基本了解了什么是Fuzzing,以及如何编写基于python程序的Fuzzer,同时根据相关理论指导来优化我们的Fuzzer。
该系列主要参考自FuzzingBook,后面逐步更新相关知识的补充






发表评论
您还未登录,请先登录。
登录